Google Professional-Data-Engineer (Google Professional Data Engineer Exam)
Google Professional Data Engineer Exam Overview
What is the Google Professional Data Engineer certification and why it matters
Real deal here.
The Google Professional Data Engineer certification is an industry-recognized credential that validates your expertise in designing, building, and operationalizing data processing systems on Google Cloud Platform. This is not just another checkbox cert. It actually demonstrates that you can enable data-driven decision making through collecting, transforming, and publishing data in ways organizations really care about. Companies want proof you know how to turn messy data into actionable insights. This certification? Basically your stamp of approval.
The value proposition here is pretty straightforward. You are showing employers and clients that you can architect solutions that actually work in production, not just pass some theoretical exam. We are talking about designing data pipelines that run reliably at scale. Optimizing warehouses that do not blow through budgets. Implementing governance frameworks that keep compliance teams happy. Ensuring data quality so analysts are not constantly chasing down bad numbers.
Who should take this exam and what backgrounds make sense
The target audience spans data engineers, ETL developers, data architects, analytics engineers, and ML engineers working with GCP. I have seen software engineers transitioning into data roles crush this exam. Traditional database administrators moving to cloud nail it. Analytics professionals expanding their technical skills succeed too. The common thread is that you are working with data systems and want to prove you know GCP's data stack inside out.
Not gonna lie, while Google says there are no formal prerequisites, you really need practical experience with data systems to stand a chance. Most successful candidates have 3+ years of industry experience including at least 1 year designing and managing solutions on GCP. That hands-on time matters. The exam tests scenarios you will encounter in real projects, stuff like choosing between batch and streaming architectures, optimizing query performance when BigQuery costs are spiraling, deciding whether to use Dataflow or Dataproc for a specific workload.
Actually, I once spent three weeks troubleshooting a Dataflow pipeline that kept timing out during window aggregations, only to discover the issue was how we were handling late-arriving data. That kind of pain teaches you things no documentation can.
What the certification actually validates
This cert proves you can handle data pipeline design, data processing system operations, machine learning model deployment, and solution quality assurance. The exam covers four main domains: designing data processing systems, building and operationalizing those systems, operationalizing machine learning models, ensuring solution quality through reliability, security, and governance measures.
Here's what that looks like in practice, though. You need deep understanding of data modeling, like when to denormalize in BigQuery versus normalize in Cloud SQL. SQL optimization is not optional. You will face questions about partition pruning, clustering strategies, materialized views. Distributed systems concepts matter because you are working with tools like Dataflow that parallelize work across multiple workers. Cloud-native architectures are fundamental since you are expected to use managed services rather than reinvent wheels.
But technical depth alone will not cut it. You also need business sense. The ability to translate vague business requirements into concrete technical data solutions and justify architectural decisions based on cost, performance, and maintenance tradeoffs. The thing is, I have seen brilliant engineers struggle because they could not explain why they would choose one approach over another in business terms.
Career impact and industry recognition
The career doors this opens? Legit. We are talking senior data engineering roles, consulting positions where you are architecting solutions for multiple clients, cloud architecture specialization paths. Fortune 500 companies respect this credential. Startups building on GCP look for it. Cloud-native organizations globally recognize it as proof you know your stuff.
Salary implications matter here. Certified professionals often command 15-25% higher compensation than non-certified peers with similar experience. Now, correlation is not causation. People who pursue certification tend to be more invested in their careers anyway. But hiring managers definitely notice that badge on your LinkedIn profile.
How this differs from other Google Cloud certifications
Understanding the differentiation is important.
The Associate Cloud Engineer covers broad GCP fundamentals across compute, storage, networking, and basic services. The Professional Cloud Architect focuses on overall solution design and architecture patterns across all GCP services. The Professional Machine Learning Engineer dives deep into ML model development, training, deployment.
This Professional Data Engineer cert sits right in the middle, focusing specifically on data engineering workflows. You will overlap with the Cloud Architect on designing scalable systems and with the ML Engineer on deploying models, but your lens is data pipelines, warehouses, lakes, analytics infrastructure. Think BigQuery optimization. Pub/Sub message patterns. Dataflow pipeline design. Dataproc cluster sizing. Cloud Composer workflow orchestration.
Real-world application scenarios you will encounter
The exam tests real-world application scenarios like building batch pipelines that process terabytes of logs nightly, implementing streaming architectures that handle millions of events per second, optimizing data warehouses to cut query times from minutes to seconds, implementing data governance frameworks that track lineage and enforce access controls.
Data quality scenarios come up constantly. How do you validate incoming data? Where do you implement schema enforcement? What monitoring alerts catch pipeline failures before business users notice? These are not abstract questions. They are problems you solve every week as a data engineer.
The certification path and what to expect
Timeline varies significantly.
The certification path timeline varies, but most candidates spend 2-4 months preparing depending on existing GCP experience. If you are already running production data pipelines on GCP, maybe you need 4-6 weeks focused study. Coming from AWS or Azure data engineering? Probably 3 months to learn GCP-specific services and approaches. Brand new to cloud data engineering? Budget 4+ months and get hands-on experience along the way.
Exam difficulty perception? It is considered intermediate to advanced. You need both theoretical knowledge and hands-on experience because the questions are not trivia. They are scenario-based situations where you evaluate tradeoffs and choose optimal solutions. Success factors combine documentation study, hands-on labs where you actually build stuff, practice exams that familiarize you with question styles, real-world project experience that gives you intuition.
The exam costs $200 USD (check Google's official certification site for current pricing and any regional variations). You will face a 2-hour exam with 50-60 questions in multiple-choice and multiple-select formats. It is offered worldwide through online proctoring and physical test centers. Available in English and Japanese currently.
Scoring, validity, and maintaining your certification
Here's the thing about passing scores. Google does not publish an official numeric threshold, so you will get a pass/fail result. The exam uses scaled scoring across the different domains where each domain carries different weight, meaning you need to demonstrate competency across all areas, not just ace one section while bombing another.
The certification is valid for two years. Makes sense given how rapidly GCP services change. This is a continuous learning requirement, not a one-and-done achievement. To renew, you retake the exam before expiration. The Professional Cloud Database Engineer and Professional Cloud DevOps Engineer certifications follow similar renewal patterns.
Why employers demand this certification
Employer demand stays high.
Employer demand for certified data engineers stays high as organizations migrate analytics workloads to cloud. Every company that moves from on-premises Hadoop clusters or traditional data warehouses to GCP needs people who know how to architect those solutions properly. You will get access to the Google Cloud certified community, exclusive events, networking opportunities, shareable digital badge for LinkedIn and your resume.
The certification portfolio strategy often involves pursuing this after completing the Associate Cloud Engineer or alongside the Cloud Architect certification. Some folks combine it with the Professional Cloud Security Engineer to specialize in secure data platforms.
Look, this certification is not easy, but it is worth it if you are serious about data engineering on GCP. It validates skills that matter, opens doors that stay closed to non-certified folks, and it forces you to learn the platform at a depth that makes you really better at your job.
Exam Format, Cost, and Logistics
Exam format, cost, and logistics
Exam cost
The Google Professional Data Engineer Exam runs $200 USD. Officially.
But that clean number everyone quotes? Real pricing gets messier fast. Regional variations exist and local taxes can absolutely get slapped on top depending on your booking location, so the final charge hitting your card might creep higher than that round figure you spotted in some study guide or forum post.
Payment works like most modern certification programs. Major credit cards accepted. PayPal works. Or, if you work somewhere that actually invests in training, organization vouchers (typically purchased in bulk for enterprise teams pushing Google Cloud hard). If your company's deep into GCP adoption, vouchers show up regularly and make that expense report dance way less painful.
Cost comparison? Competitive. The Professional Data Engineer exam cost sits right in the same ballpark as AWS Certified Data Analytics and Azure Data Engineer Associate, so you're not getting gouged just because it's Google's cert. The real cost isn't even the money, though. It's your time. Two to eight weeks of late nights plus hands-on labs plus practice tests becomes the actual investment, especially if you're tackling BigQuery and Dataflow exam prep properly instead of just speed-reading product documentation and hoping for the best.
Employer reimbursement? Big deal. Many companies reimburse exam fees when you pass, some reimburse even after one failure, and some need pre-approval forms signed in triplicate. Check your internal policy. Ask HR. Ping whoever controls your learning budget. One quick email. Saves you $200.
Retakes are straightforward. Kind of brutal, though. Fail once? You can retake after 14 days, and there's no cap on attempts. But here's the catch: every single attempt costs the full exam fee again. No discount pricing for round two or three. That policy should change how you approach prep, because treating your first attempt like a casual "let's see what happens" experiment can turn into an expensive pattern real quick.
Worth knowing, too. Register and then procrastinate indefinitely? You typically must take the exam within one year of registration or you lose the fee entirely, so don't play the "buy now, figure it out later" game unless you're planning to schedule soon.
Exam length, question types, and delivery method
You get 2 hours. 120 minutes. Done.
No bonus time appears unless you've gotten approved for accessibility accommodations, and those require separate requests.
Question count usually lands around 50 to 60 questions, but the exact number varies by exam version. Which means your experience might not perfectly match what your coworker encountered last month. Some questions hit fast. Quick recall. Others are "apply this concept in context." And some are these analysis-heavy scenario situations. You'll see variety. You'll recognize a service name, answer in ten seconds. Then you'll hit a case study where you're choosing between three "technically viable" designs and selecting the one matching constraints like latency requirements, governance policies, and budget limitations.
Formats include:
- multiple-choice, single answer
- multiple-select, multiple correct options
Case study questions appear too, and that's where the Google Professional Data Engineer certification starts feeling less like trivia night and more like actual work. You'll get business requirements alongside technical constraints, then choose architecture decisions or operational approaches tied to GCP data pipeline design and operations. Read carefully. Missing one word like "minimize operational overhead" can completely flip the correct answer from Dataproc to Dataflow, or from "build custom" to "use managed service."
I remember taking an older Google exam years back and spending way too much mental energy on whether the proctor could see me squinting at a poorly worded question. They could. They don't care if you squint. Just don't look off-screen.
Delivery methods: online proctored or in-person at authorized test centers. Test centers operate through the Kryterion network, and you locate them through the Google Cloud certification site. Live near a city? You probably have options. Rural area? Online becomes the practical choice.
Online proctoring has requirements. They're strict. Stable internet connection, webcam, microphone, government-issued ID, and a quiet private room. No notes allowed. No second monitor. No phone. No "my roommate just walked through the frame." A live proctor watches via webcam, and you'll perform a room scan before starting, which feels super awkward initially and totally normal by your second certification.
You'll also complete a mandatory system compatibility test before scheduling the online proctored exam. Do this early. Don't discover on exam day that your corporate laptop blocks the secure browser, or your VPN breaks the network check, or your webcam "works perfectly in Zoom" but fails in the testing application.
Breaks? None scheduled. Bathroom breaks are generally permitted, but the exam timer keeps running regardless. That means you don't want to plan some "quick break strategy" at question 35 unless you're already crushing the pace. Hydrate normally. Don't mainline coffee.
Registration and scheduling steps
Registration follows a pretty standard flow, but details matter because ID mismatch represents the absolute dumbest way to lose an exam appointment.
Here's how it works:
- Create a Google Cloud certification account
- Fill personal info and professional profile details
- Select exam and delivery method
- Pick date and time, pay, confirm
Account setup requires a Google account and accurate personal information matching your government ID exactly. Exactly. If your ID reads "Robert" and you register as "Bob," you might spend exam day in support ticket hell instead of actually testing. Fix mismatches before scheduling.
Scheduling flexibility depends on delivery method. Online exams typically run 24/7, which works great if you test better at night or you're trying to squeeze it between on-call rotations. Test centers operate specific hours, and popular slots fill up, especially end of quarter when everyone suddenly remembers performance reviews exist.
Rescheduling and cancellation rules are one of those things you ignore until you desperately need them. You can usually reschedule up to 72 hours before the exam without penalty. Cancel 72+ hours ahead and you can get full refund. Change too late? You may forfeit the entire fee. I treat that 72-hour window like an absolute hard wall, because life happens constantly, and you don't want to accidentally donate $200 to the certification testing gods for no reason.
Language selection matters more than people realize. You choose exam language during registration, and you typically can't change it after scheduling. Same deal with time zone. Online exams display in your local time zone, but if you're traveling or using a work laptop configured to a different region, double-check the booking time carefully before clicking confirm.
Accessibility accommodations are available when needed. Request them during registration and be prepared to provide documentation. Processing takes time, so don't wait until the week of your exam.
After finishing, you'll usually get preliminary pass/fail immediately. Official results appear within 7 to 10 days, and you'll receive a score report with section-level feedback, basically strengths and improvement areas tied to the Professional Data Engineer exam objectives. No, it won't specify "you got question 12 wrong." More like "you're weaker in operationalizing pipelines" or "security and governance needs work."
Pass? The digital certificate typically appears in your certification account within 15 business days. Employers can verify it through third-party verification in the Google Cloud certification directory, which helps when your recruiter or compliance team demands proof and won't accept a screenshot.
One more thing. NDA. You'll agree to exam content confidentiality before starting, and you absolutely can't share specific questions. That also means when you're shopping for Professional Data Engineer practice tests, avoid anything resembling a dump. Besides being unethical, it's a fast track to getting your cert invalidated, and it doesn't actually help when you're designing data processing systems on GCP under real pressure.
Corporate voucher programs and student discounts exist. Sometimes. Vouchers are common for enterprise customers buying in bulk for training initiatives. Student discounts can appear through Google Cloud academic programs, but they're limited and eligibility varies wildly. Mentioned casually here, because most working professionals will just pay the $200 or get reimbursed, but if you're currently in school, it's worth checking before paying full price.
And yeah, people always ask about the Professional Data Engineer passing score when planning logistics. Google generally doesn't publish a numeric passing score, so you plan around the format, the clock, and your actual readiness, not around "I need 72%." Different section feedback, scaled scoring, all that complexity. For logistics purposes, what matters is simple. Two hours. 50 to 60 questions. Pick online or test center. Show up with correct ID. Don't bring anything prohibited.
Passing Score and Scoring Details
What is the passing score?
No magic number exists.
This is probably the first question everyone asks, and Google doesn't make it easy. The thing is, Google Cloud doesn't publish a specific numeric passing score publicly for the Professional Data Engineer exam. There's no magic number like "you need 75%" posted anywhere official. You'll finish the exam and get a pass or fail. That's it. No "you scored 820 out of 1000" or anything remotely close to that kind of transparency.
Why the secrecy? It protects exam integrity and accounts for difficulty variations across exam versions. Think about it: if Google published "70% to pass," everyone would obsess over that number instead of actually learning the material. Plus different exam forms have slightly different questions, so a raw score of 70% on one version might not equal the same difficulty as 70% on another version. My cousin took the Azure equivalent and had the exact same complaint about their scoring system, by the way. Seems like all the cloud vendors love their mysterious scoring methods.
How the exam is scored
The exam uses scaled scoring methodology. Fancy term, right? Basically your raw score gets converted through some psychometric magic to ensure fairness across different test versions. Your performance gets evaluated against an established standard that Google's testing psychologists have determined represents competent professional-level data engineering knowledge.
Here's what actually happens when you're taking it. You answer all the questions. Some are multiple-choice, some are multiple-select (the ones where you pick two or three correct answers, and those are honestly the trickiest). Not all questions carry equal weight in the scoring. Complex scenario questions where you're troubleshooting a data pipeline or optimizing BigQuery costs may be weighted higher than straightforward recall questions. Makes sense, right? Real-world data engineering is about solving complex problems, not just memorizing product names.
And here's something that'll surprise most people. Some unscored questions are included for future exam development. These are experimental items Google is testing to see if they're good enough for future exam versions. They don't affect your score at all, but you can't identify experimental items while you're taking the test, so you have to answer every single question seriously. Not gonna lie, this used to bother me. Like, why am I wasting time on questions that don't count? But there's literally no way to tell which ones they are, so just treat everything as scored.
Getting your results
Immediate relief or disappointment.
Immediate results show up on screen right after you complete the exam. You'll see a preliminary pass/fail status before you even leave your desk (or close your browser if you're testing online). That moment is either pure relief or, well, not great.
Official confirmation comes via email within 7-10 business days with a detailed performance breakdown, and this is where it gets actually useful for your career development. The score report shows performance by exam domain. You'll see how you did on designing data processing systems, building and operationalizing systems, operationalizing machine learning models, and ensuring solution quality.
Results are categorized as "above target," "near target," or "below target" for each section. If you pass, great, you probably have mostly "above target" marks scattered across domains. If you fail, this section-level feedback becomes your roadmap for round two. Maybe you crushed the BigQuery optimization questions but tanked on streaming architecture with Dataflow and Pub/Sub, which tells you exactly where to focus your study efforts.
There's no minimum section scores requirement. Overall performance determines pass/fail. You don't need to pass each domain individually, which is honestly a relief because most people have stronger and weaker areas. I've seen people pass who were "below target" in one domain but absolutely killed the other sections.
Understanding the domain weighting
Each exam objective domain is weighted based on job task importance and how often professional data engineers actually use those skills in production environments. The exact percentages aren't published officially, but based on the exam guide and industry feedback, here's roughly what you're looking at:
Designing data processing systems makes up approximately 22-25% of exam content. This covers choosing the right services (BigQuery vs Bigtable vs Cloud SQL), designing for scale, data modeling, and architectural patterns that actually work at enterprise scale.
Building and operationalizing data processing systems is the biggest chunk at approximately 25-28%. You're getting tested on actually implementing pipelines, using Dataflow, scheduling with Cloud Composer or Cloud Scheduler, monitoring, logging, all that operational stuff that keeps systems running at 3 AM.
Operationalizing machine learning models sits at approximately 18-22% of exam content. This includes model deployment on Vertex AI, MLOps practices, batch vs real-time prediction, and integrating ML into data pipelines. Even if you're not a hardcore ML person (and not everyone is), you need to know how data engineers support ML workflows.
Ensuring solution quality rounds it out at approximately 25-28%. This covers reliability, security, compliance, data governance, cost optimization, and performance tuning. This domain is huge in real-world data engineering. Nobody cares if your pipeline works if it costs $50k a month or exposes PII data to the internet.
Weighting may vary slightly between exam versions, and Google doesn't commit to exact numbers publicly. But the proportions give you a sense of where to invest your study time most efficiently.
Scoring mechanics and strategy
For multiple-select questions, you need all correct answers. No partial credit for incomplete selections, which is honestly brutal. If a question asks you to select two correct ways to optimize a BigQuery query and you only pick one right answer, you get zero points for that question. This makes multiple-select questions particularly tricky and honestly where a lot of people lose points unnecessarily.
Good news though: there's no penalty for incorrect answers. No negative marking whatsoever. Guessing strategically is better than leaving anything blank, which means if you're stuck on a question with three minutes left, take your best educated guess based on elimination and move on. I've passed exams where I honestly guessed on 5-6 questions I wasn't sure about.
What about retaking?
There's no formal score appeal process. If you disagree with your results, well, you can retake the exam. Google doesn't do score reviews or let you challenge individual questions after the fact. The psychometric analysis and scaled scoring are considered final.
You can't compare scores across attempts since numeric scores aren't provided. You just know pass or fail, period. So if you fail once and pass the second time, you have no idea if you "barely passed" or crushed it the second time around. Some people find this frustrating, but honestly it keeps you focused on mastery rather than chasing a specific number.
How hard is it really?
Honestly? Challenging but fair.
Industry estimates suggest a 60-70% passing rate for first-time test takers, though Google doesn't publish official statistics so these are based on community feedback. That's comparable to the Professional Cloud Architect certification in terms of difficulty, and definitely more challenging than Associate Cloud Engineer level.
The exam difficulty is calibrated through ongoing psychometric analysis to ensure consistent difficulty across versions over time. Google regularly reviews question performance, removes items that are too easy or too hard, and adjusts the question pool based on statistical analysis. This is why they can use scaled scoring, because they know statistically how difficult each version is compared to every other version that's been administered.
If you're considering practice materials, the Professional-Data-Engineer Practice Exam Questions Pack at $36.99 can help you get familiar with the question format and difficulty level. Real practice questions that mirror the exam structure are honestly more valuable than just reading documentation, because they force you to apply knowledge under time pressure like you'll experience in the actual exam.
Using your results strategically
Whether you pass or fail, use that section feedback intelligently. If you were "below target" on operationalizing ML models, spend more time with Vertex AI, understand batch vs online prediction differences, learn about model monitoring and drift detection techniques. If you crushed designing systems but struggled with ensuring solution quality, dive deeper into Cloud IAM, VPC Service Controls, data encryption options, DLP API, and cost optimization techniques that actually matter in production.
The score report isn't just a pass/fail. It's a diagnostic tool for your professional development. Even if you pass, knowing your weaker areas helps you be a better data engineer in actual job roles where these skills matter daily.
Final thoughts on scoring
Focus on mastery. Period.
Focus on mastery rather than minimum passing scores. I've seen people cram just enough to maybe scrape by, and even if they pass, they struggle in actual data engineering roles where you can't just memorize answers. The certification is supposed to validate that you can design and build production data systems on Google Cloud that actually work at scale. Deeper knowledge serves your long-term career way better than barely passing with minimal understanding.
The scoring methodology is designed to be fair and consistent, even if the lack of a published passing score feels frustrating initially. Trust the process, study thoroughly, get hands-on experience with BigQuery, Dataflow, Pub/Sub, Cloud Storage, Dataproc, and Vertex AI, and you'll likely pass comfortably without stressing over specific numbers. And if you don't pass the first time? The section-level feedback tells you exactly what to fix for round two.
Similar to other Google Cloud certifications like Professional Cloud Database Engineer or Professional Machine Learning Engineer, the Professional Data Engineer exam rewards practical experience and deep understanding over rote memorization. The scoring reflects that priority consistently across all exam versions.
Difficulty: How Hard Is the Professional Data Engineer Exam?
Google Professional Data Engineer Exam overview
The Google Professional Data Engineer Exam is basically Google asking, "Can you design, build, and run data systems on GCP when things get messy?" Not toy pipelines. Real ones. The cert validates you can pick the right storage, processing, orchestration, governance, and monitoring approach while juggling cost, reliability, and security. Harder than it sounds.
Data engineers, analytics engineers drifting into platform work, ML engineers who keep getting stuck owning pipelines, and cloud engineers trying to move into data roles are the usual crowd. If your day job includes BigQuery, Dataflow, Pub/Sub, Dataproc, or even just constant arguments about batch vs streaming, you're the target. New grads can try, but honestly they usually suffer. I watched a friend's younger brother attempt it fresh out of school with a CS degree and good grades. Kid was sharp, no question, but he got absolutely steamrolled because the exam wants production scars, not just textbook knowledge. He passed on the second attempt after six months of actual infrastructure work.
Exam format, cost, and logistics
Exam cost
List price is typically $200 USD (plus tax where applicable), but taxes and currency conversion vary by region. Some countries tack on VAT/GST, so your Professional Data Engineer exam cost might land noticeably higher than $200 when the checkout page finishes doing its thing. Retakes also cost money. Plan for that.
Exam length, question types, and delivery method
You get 2 hours for roughly 50 to 60 questions. That's about 2 to 3 minutes per question if you do the math. Some are quick hits. Many are not. Expect multiple-choice and multiple-select, with scenario-heavy prompts and case studies that feel like someone pasted a mini design doc into the exam.
Delivery is usually online proctored or test center, depending on what Google's testing partner supports in your area. Online is convenient, but it's also picky about room setup, webcam, and "why is your cat walking behind you" type stuff. Test centers remove that headache but add commute time.
Registration and scheduling steps
Pick the exam in the Google Cloud certification portal, go to the testing provider, choose online vs center, pay, and schedule. That's the easy part. The real scheduling hack is giving yourself a time slot where your brain works, not a random 9:00 PM after-work slot where you're fried and start misreading Dataflow vs Dataproc like they're the same thing. They're not.
Passing score and scoring details
What is the passing score?
People keep asking for the Professional Data Engineer passing score, and look, Google generally doesn't publish a numeric passing score. You get a pass/fail result. That's it. No "you got 78%." So if you're hunting for a magic number, you won't find it.
How the exam is scored
Scoring is scaled, and questions are weighted. Translation: two candidates can answer the same number of questions correctly and still get different outcomes depending on what they missed. Domains matter, and the exam likes to mix them, so you're rarely "just doing BigQuery." You're doing BigQuery plus IAM plus cost plus governance plus an angry stakeholder with a deadline.
Difficulty: how hard is the professional data engineer exam?
Difficulty level (beginner/intermediate/advanced)
My honest take: the Google Professional Data Engineer Exam is intermediate to advanced. It requires theory, sure, but it also expects you to have scars from production. Distributed systems concepts show up in sneaky ways. Data modeling. Performance optimization. Cost management. Reliability planning. You can't fake those with flashcards for long.
Compared to Associate Cloud Engineer, it's significantly harder. ACE is more like "can you operate GCP." This one is "can you design the right system, defend the tradeoffs, and keep it running when the data volume triples and compliance shows up with a clipboard." Broader scope. Deeper questions.
Versus Professional Cloud Architect, the difficulty is similar, but the center of gravity is different. PCA ranges across everything, whereas the data engineer exam goes deep on data pipelines and analytics patterns. It expects you to know the Google-recommended way, not just a technically possible way.
Why candidates fail (common gaps)
Hands-on is the big one. Studying docs without building pipelines leaves gaps you don't notice until the exam asks about Dataflow windowing, BigQuery partitioning and clustering choices, or Pub/Sub delivery behavior under load. Memorization feels good but it lies.
Scenario questions get underestimated. Case studies are long. Reading comprehension becomes a skill. You'll get business requirements, budget limits, timeline constraints, security rules, maybe RPO/RTO targets, then you have to choose the "most correct" architecture even when multiple answers feel defensible. Ambiguity is real. The exam likes tradeoffs.
Other common wipeouts: neglecting ML or security because "I'm a data person," spending too long on one brutal question, using outdated materials that don't match current best practices, and skipping Professional Data Engineer practice tests so the format surprises you. Also, overconfidence from AWS/Azure experience. It's a great background, don't get me wrong, but not a free pass. GCP service names, patterns, and defaults matter.
Recommended experience to feel confident
For confidence, I like 1 to 2 years doing real GCP data engineering work, or an equivalent intense build cycle where you've shipped pipelines and dealt with failures. Career changers often need 3 to 6 months part-time with regular labs. Experienced data engineers who are new to GCP can sometimes do it in 6 to 8 weeks if they go hard, but that means daily practice, not weekend skimming.
And yeah, you need a lab environment. You can't pass comfortably without building stuff, breaking stuff, and fixing it.
Exam objectives (official domains)
Google publishes the Professional Data Engineer exam objectives, and they map roughly to these domains:
Designing data processing systems
You'll get architecture selection questions: batch vs streaming, lake vs warehouse, managed vs self-managed, cost vs latency. Expect multi-service integration prompts where Pub/Sub meets Dataflow meets BigQuery meets Cloud Storage, plus monitoring and security wrapped around it.
Building and operationalizing data processing systems
This is the "can you run it" section. Dataflow pipeline behaviors, Dataproc tradeoffs, orchestration choices, error handling, retries, idempotency, schema evolution. Little details. The kind you learn after your first on-call.
Operationalizing machine learning models
Not super deep research ML. More like "how does a data engineer support ML workflows" on GCP. Think Vertex AI basics, feature data considerations, batch prediction pipelines, governance, and keeping training data access under control. People ignore this and then wonder why they failed.
Ensuring solution quality (reliability, security, governance)
IAM, encryption, key management patterns, data access boundaries, audit logs, data governance, and reliability planning. Disaster recovery shows up too, with RPO/RTO requirements and the architecture implications. This is where "best practices emphasis" really bites.
| Objective | Key services you'll keep seeing | |---|---| | Designing data processing systems | BigQuery, Cloud Storage, Pub/Sub, Dataflow, Dataproc, Cloud SQL, Spanner, Bigtable | | Building and operationalizing | Dataflow, Dataproc, Composer/Workflows, Cloud Scheduler, Cloud Logging/Monitoring, Cloud Build | | Operationalizing ML models | Vertex AI, BigQuery ML, Cloud Storage, Dataflow, Pub/Sub | | Ensuring solution quality | IAM, Cloud KMS, VPC Service Controls, Secret Manager, Cloud Audit Logs, Dataplex (often), DLP (sometimes) |
Prerequisites and recommended background
Are there formal prerequisites?
No mandatory prerequisites, which is classic Google. The Professional Data Engineer prerequisites are basically "please don't do this cold." You can. You'll hate it.
Recommended skills and knowledge
SQL is non-negotiable. Data modeling. Streaming vs batch patterns. Partitioning and clustering in BigQuery. Pub/Sub delivery, ordering, and retry concepts. IAM basics. Networking basics. Monitoring and alerting. Cost awareness. If you can't explain why one design costs 5x more, the exam will find you.
Helpful prior certifications (optional)
Associate Cloud Engineer helps with general GCP comfort. Professional Cloud Architect helps with scenario thinking. Neither replaces real pipeline work.
Best study materials (official + third-party)
Official Google Cloud learning paths and documentation
Start with the exam guide, then use product docs, Architecture Center patterns, and best practice pages. The exam is very "Google says do it this way." If your approach works but isn't recommended, you might still lose points. Annoying, but predictable.
Courses and books to consider
Structured courses help if you need a map. Courses without labs are like watching gym videos and expecting abs. Pick training that includes building, debugging, and cost discussion, not just feature tours.
Hands-on labs and projects (portfolio-style practice)
Build one batch pipeline and one streaming pipeline end-to-end. Add governance. Add monitoring. Break it on purpose. Fix it. Do BigQuery optimization work: partitioning, clustering, materialized views, slot reservations vs on-demand. For BigQuery and Dataflow exam prep, nothing beats actually running Dataflow jobs and seeing how choices affect throughput and cost.
Practice tests and exam prep strategy
Practice tests: what to use and what to avoid
Use reputable Professional Data Engineer practice tests that teach you why an answer is right. Avoid brain dumps. Not moralizing here, just practical: they're often outdated, they teach bad habits, and they don't prepare you for the "most correct" logic.
If you want a focused set to drill the format, I've seen people pair labs with a question pack like Professional-Data-Engineer Practice Exam Questions Pack to build timing and pattern recognition. Same link again later, because repetition is how studying works.
Study plan (2-week / 4-week / 8-week options)
Two-week is only realistic if you already do GCP data pipeline design and operations at work and just need exam alignment. Four-week is intense but doable for experienced engineers switching clouds. Eight-week fits most career changers with a job and a life.
Topic-by-topic checklist and last-week revision plan
Hit BigQuery optimization hard. Do Dataflow patterns next. Then Pub/Sub, Storage formats, Dataproc tradeoffs, orchestration, IAM/KMS/VPC SC, governance. Last week: timed practice, review mistakes, reread best practices, and run one more mini build. Use Professional-Data-Engineer Practice Exam Questions Pack as a timer tool if that works for you, but don't let questions replace labs.
Renewal and validity
Certification validity period
Google Cloud certs are typically valid for 2 years, but check Google's site because policies can change. This matters for your resume and for employer reimbursement cycles, not just bragging rights.
How to renew
Renewal usually means retaking the exam. Keep your certification profile updated, and don't wait until the last week, because scheduling slots can be weird. If you're thinking ahead, also track Google Cloud certification renewal Professional Data Engineer requirements since Google occasionally tweaks exam versions and objectives.
FAQs (People Also Ask)
How much does the exam cost?
Typically $200 USD plus tax, with regional differences. That's the headline Professional Data Engineer exam cost number most people plan around.
Is there a published passing score?
No official numeric Professional Data Engineer passing score is published. You get pass/fail.
How long should I study?
Most people land in the 6 to 12 week range unless they already work in GCP daily. If you're new to GCP, give yourself time for labs and troubleshooting.
What are the most important services to know?
BigQuery and Dataflow are the core. Pub/Sub patterns matter. IAM and KMS show up constantly. Vertex AI basics can't be ignored. The exam tests 20+ services, but depth matters most on the core ones.
How do I renew after it expires?
Usually by retaking the exam, assuming your credential is past validity. Plan ahead, keep materials current, and don't rely on old notes from three years ago. GCP changes fast. Your freshest hands-on experience beats any old Professional Data Engineer study guide every time.
Exam Objectives and Official Domains
Domain structure overview
The Google Professional Data Engineer certification breaks down into four major domains that walk you through the complete lifecycle of data engineering on GCP. These domains map directly to what you'll actually do as a data engineer, not some abstract framework dreamed up in a conference room.
You've got designing data processing systems, building and operationalizing those systems, operationalizing machine learning models, and ensuring solution quality. Each domain flows naturally into the next. You can't just be great at designing pipelines but terrible at actually building them, right? Google structured this to force you to demonstrate end-to-end competency, which makes sense because that's what the job requires when you're working on production systems at scale.
Objective alignment with job tasks
Look. Real talk?
These domains reflect the actual responsibilities you'd have as a professional data engineer working with Google Cloud. When you're sitting in a meeting with stakeholders trying to figure out how to get customer event data from your mobile app into a data warehouse for analysis, that's domain one (designing systems). When you're writing the actual Dataflow pipeline in Python and deploying it, that's domain two (building and operationalizing). If the data science team needs those customer events to train a churn prediction model and you're integrating that into production, domain three (ML models). And when you're setting up monitoring, access controls, and making sure the whole thing doesn't fall over or leak PII, that's domain four (solution quality).
The exam objectives map to tasks in a typical job description for data engineers at companies using GCP. You'll see questions about translating business requirements into technical specs, choosing between BigQuery and Bigtable for specific use cases, optimizing query performance, setting up IAM policies. All stuff you'd encounter in week one of a data engineering role.
Weighting and emphasis
Here's the thing about the weighting: each domain contributes significantly to your overall score. Google doesn't publish exact percentages, but you can't ignore any single domain and expect to pass. Some candidates try to focus heavily on BigQuery and data warehousing because that's what they use daily, but then they bomb on the streaming questions or the ML integration scenarios.
The exam forces you to be well-rounded. Period. You might get 15-20% of questions on ML operationalization even though you've never touched Vertex AI in your current job. Can't skip it. The building and operationalizing domain is probably the heaviest, but designing systems and ensuring quality aren't far behind. Treat all four domains seriously.
I remember talking to a colleague who passed on his third attempt. First two times? He kept skipping the ML sections during study, figured he could wing it since he was strong everywhere else. Nope. Those questions will get you.
Business requirements analysis and data source identification
Translating stakeholder needs into technical data architecture specifications is where most real-world projects start, and Google tests this heavily. You'll get scenarios like "the marketing team needs near-real-time customer behavior analytics with historical trending" and you need to figure out the architecture. Does that mean Pub/Sub feeding into Dataflow with BigQuery as the sink? Or maybe streaming inserts directly to BigQuery? The thing is, it depends on latency requirements, data volume, transformation complexity.
Understanding various data sources matters. You've got relational databases (Cloud SQL, on-prem MySQL), NoSQL stores (Firestore, Bigtable), streaming sources (Pub/Sub, Kafka), REST APIs, flat files in Cloud Storage, even mainframe batch exports. Each source has different ingestion patterns. CDC (change data capture) for databases, polling for APIs, event-driven for streaming. The exam will throw mixed-source scenarios at you and expect you to design appropriate ingestion strategies for each.
Data pipeline architecture and storage solution selection
Designing batch, streaming, and hybrid processing workflows is core to this exam. Batch might be daily aggregations using Dataproc Spark jobs. Streaming could be real-time fraud detection with Pub/Sub to Dataflow to BigQuery. Hybrid is where it gets interesting. Maybe you're doing micro-batching with Dataflow or combining historical batch data with streaming updates.
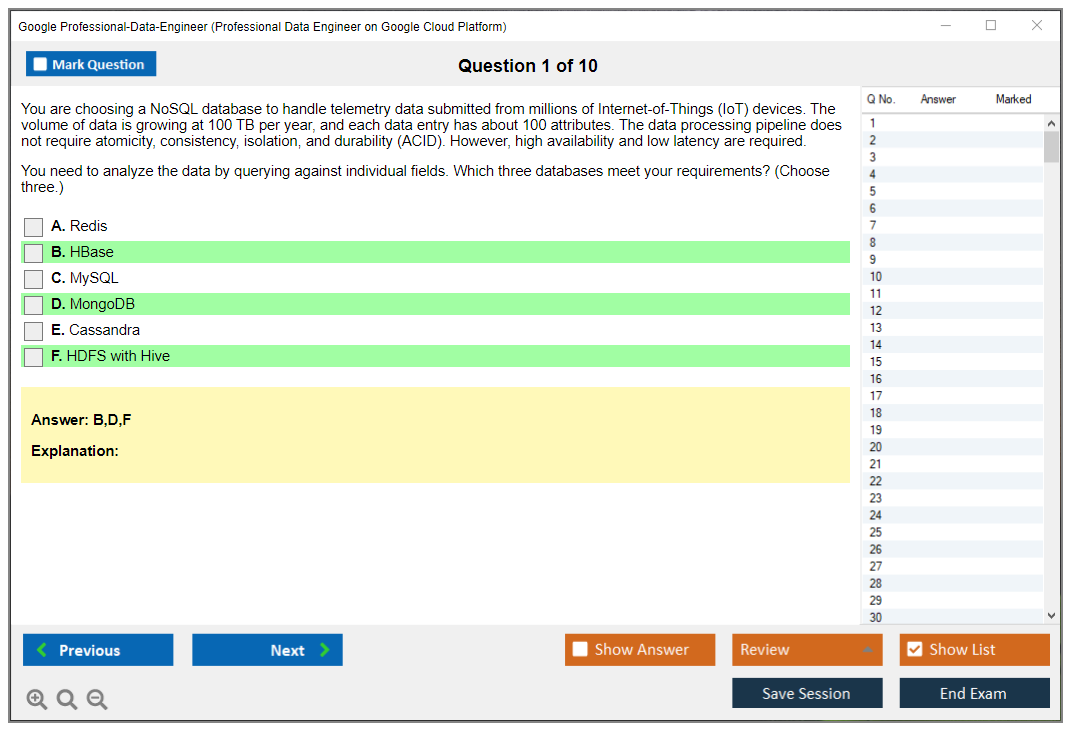
Choosing appropriate storage is huge. Cloud Storage for raw data lakes, files, archives. BigQuery for analytics, data warehousing, anything SQL-heavy. Bigtable for high-throughput, low-latency NoSQL (think time-series, IoT). Firestore for transactional document data with mobile/web sync. Cloud SQL when you need a managed relational database with ACID guarantees. The exam loves questions that give you requirements and ask which storage service fits best. You need to know the strengths, limitations, and cost profiles of each option because they'll test you on edge cases where two services seem viable but only one's actually appropriate.
Data modeling decisions
Dimensional modeling (star schema, snowflake schema) shows up frequently, especially for BigQuery data warehouse designs. When do you denormalize vs. keep things normalized? In BigQuery, denormalization often wins because storage is cheap and nested/repeated fields perform well. But you still need to understand when normalization makes sense for data integrity or update patterns.
Schema design for analytics is different from transactional schema design. You're optimizing for read performance, aggregations, joins. Partitioning and clustering in BigQuery change how you model data. A partitioned table on ingestion timestamp with clustering on customer_id performs way better than a flat table for time-based queries filtered by customer.
Batch and streaming processing design
Batch processing design covers Dataproc for Hadoop/Spark workloads (especially when migrating from on-prem), Dataflow batch for more complex transformations with Apache Beam, and BigQuery scheduled queries for SQL-based ETL. When do you use which? I mean, Dataproc makes sense for existing Spark code or very large-scale batch jobs. Dataflow when you need cross-service integration and complex windowing. BigQuery scheduled queries for simple SQL transformations already in BigQuery.
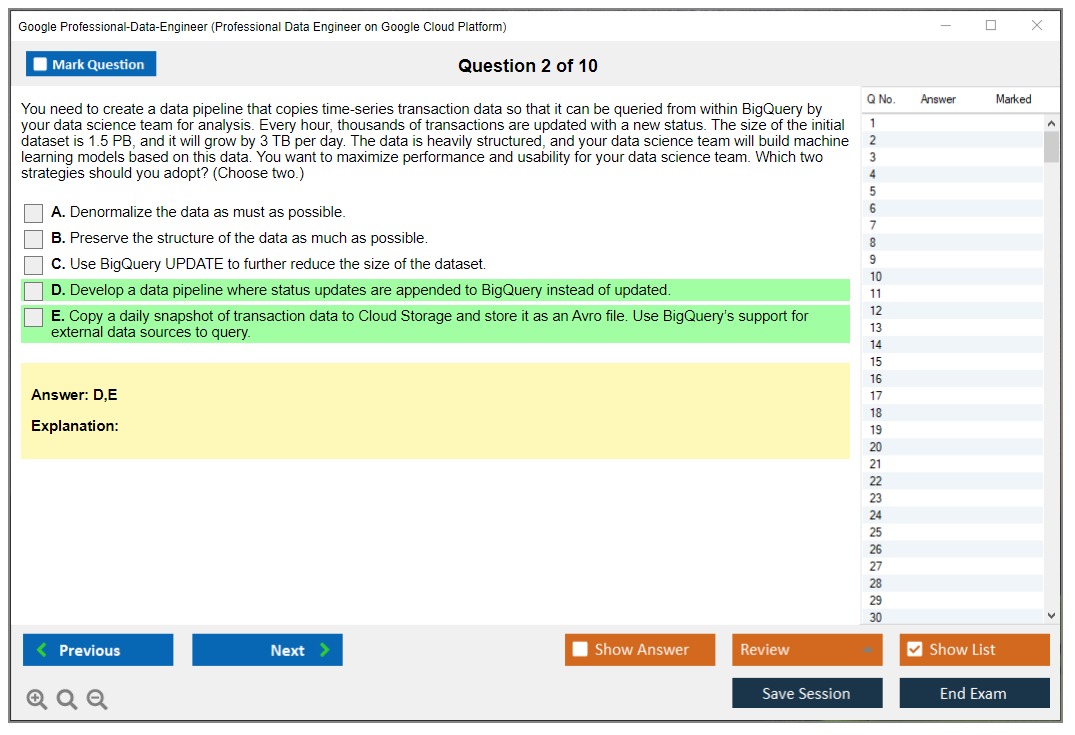
Streaming is Pub/Sub for ingestion (it's the messaging backbone), Dataflow streaming for transformations with exactly-once processing guarantees, and BigQuery streaming inserts for getting data into your warehouse quickly. The exam will test your understanding of windowing, watermarks, late data handling, and stateful processing in Dataflow.
Data warehouse and data lake patterns
BigQuery dataset organization matters more than you'd think. Logical separation by business unit, data domain, or environment (dev/staging/prod). Partitioning strategies: by ingestion time, by a date column, by integer ranges. Clustering within partitions for common filter columns. These decisions impact both query performance and cost.
Data lake patterns in Cloud Storage typically follow raw/curated/consumption layers. Raw is exactly as ingested (immutable). Curated is cleaned, validated, maybe partitioned by date. Consumption is optimized for specific use cases, maybe Parquet files optimized for analytics tools. Understanding this layering and when to move data between layers is testable.
Migration, capacity planning, and cost estimation
Moving on-premises data systems to GCP comes up in scenario questions. Do you use Transfer Service for cloud-to-cloud? Storage Transfer Service for on-prem? Database Migration Service for databases? What about hybrid architectures where some data stays on-prem but you replicate subsets to GCP?
Estimating storage, compute, and network requirements prevents nasty surprises down the road. If you're processing 10TB daily with Dataflow, how many workers do you need? What machine types? Calculating TCO includes not just compute costs but also storage, network egress, and operational overhead. The exam expects you to identify cost optimization opportunities. Using lifecycle policies to move cold data to Nearline/Coldline, using partitioning to reduce query costs, autoscaling clusters instead of leaving them running 24/7.
Scalability, high availability, and disaster recovery
Designing systems that handle growth in data volume and user concurrency is fundamental. Autoscaling Dataflow workers, BigQuery slots management, Dataproc autoscaling policies. Multi-region strategies for high availability: replicating Cloud Storage buckets, using BigQuery multi-region datasets, setting up Pub/Sub topics in multiple regions with failover mechanisms.
Disaster recovery planning means understanding backup strategies for each service, defining RPO (recovery point objective) and RTO (recovery time objective), and implementing restore procedures. BigQuery snapshots, Cloud Storage versioning, database backups to Cloud Storage. You need to know what's available and how to use it.
The exam objectives for the Google Professional Data Engineer certification cover substantially more ground than other Google Cloud certs like the Associate Cloud Engineer, requiring deeper specialization in data-specific services and patterns compared to the broader infrastructure focus of the Professional Cloud Architect.
Implementation topics
Building actual pipelines means knowing Cloud Storage operations inside out. Bucket creation, lifecycle policies, versioning, IAM and ACLs. BigQuery implementation goes beyond just running queries. Creating datasets with proper organization, tables with appropriate partitioning and clustering, views for access control, materialized views for performance, understanding when to use external tables vs. native tables.
Dataflow pipeline development requires Apache Beam knowledge in Python or Java. PCollections, transforms, windowing, side inputs, state and timers. Dataproc cluster management is different. Creating ephemeral vs. long-running clusters, submitting Spark or Hadoop jobs, configuring autoscaling, using initialization actions.
Pub/Sub messaging includes creating topics and subscriptions, understanding push vs. pull, message ordering guarantees, configuring dead-letter topics for failed messages. Cloud Composer (managed Airflow) for orchestrating complex workflows: writing DAGs, setting up dependencies, scheduling, handling retries.
Operationalization topics
SQL optimization in BigQuery is heavily tested. Writing efficient queries, avoiding SELECT *, using appropriate JOINs, using partitioning and clustering in WHERE clauses, understanding query execution plans from the EXPLAIN output.
Performance tuning extends to Dataflow (worker machine types, autoscaling parameters, fusion optimization) and Spark jobs (executor memory, parallelism, shuffle optimization). Monitoring implementation with Cloud Monitoring dashboards, setting up alerts for pipeline failures or SLA violations, defining SLOs.
CI/CD for data pipelines is increasingly important. Version control for pipeline code, automated testing (unit tests for transformations, integration tests for full pipelines), deployment automation using Cloud Build or similar tools. Infrastructure as Code with Terraform or Deployment Manager ensures reproducible environments.
Machine learning integration topics
ML pipeline integration is where data engineering meets data science. Incorporating model predictions into data processing workflows. Maybe a Dataflow pipeline calls a Vertex AI endpoint for real-time scoring, or a batch job runs predictions on Cloud Storage files.
Vertex AI platform covers model training (custom training jobs, hyperparameter tuning with Vizier), deployment (endpoints for online prediction), and monitoring (model evaluation, feature attribution). AutoML services let you build models quickly without deep ML expertise: AutoML Tables for tabular data, AutoML Vision, AutoML Natural Language.
BigQuery ML deserves special attention because it lets you build and deploy models using SQL, which data engineers already know. CREATE MODEL statements, evaluation functions, ML.PREDICT for scoring. Super powerful for common use cases like regression, classification, forecasting.
Feature engineering, model versioning, A/B testing, canary deployments, prediction serving patterns are all testable. Understanding batch vs. online prediction trade-offs, monitoring for data drift and model performance degradation, automated retraining triggers.
Security and quality topics
Security implementation is domain four but permeates everything. IAM roles and permissions (principle of least privilege), service accounts for pipeline execution, VPC Service Controls for data perimeter security. Data encryption at rest (CMEK for customer-managed keys), in transit (TLS), tokenization and masking for PII.
Data quality validation, anomaly detection, error handling with retry logic and dead-letter queues keep things running reliably. Testing strategies, resource optimization to control costs while maintaining performance. This domain ties everything together, ensuring your data architecture doesn't become a security nightmare or cost overrun disaster.
Conclusion
Wrapping things up
Look, you don't just stumble into this unprepared. The Google Professional Data Engineer certification demands actual preparation. I mean, $200 isn't pocket change, and nobody wants to throw that away on a failed attempt, right?
The passing score thing? It's weird. Google won't tell you "hey, you need 75% to pass" or anything straightforward like that, which drives people crazy. They use scaled scoring across those four main exam objectives, and you'll either see "pass" or the alternative nobody wants. But here's what I've seen work with people who actually pass: if you can confidently design data processing systems on GCP, know your way around BigQuery and Dataflow without constantly Googling syntax (we've all been there though), understand how to operationalize machine learning models even if you're not technically a data scientist, and can discuss security and governance without your eyes glazing over, you're in solid shape.
The prerequisites question comes up constantly. Technically there aren't formal ones, but I'm not gonna lie. Walking in with zero GCP experience expecting to pass because you binged a few YouTube videos is rough. Like, really rough.
I actually knew someone who tried that route after switching from Azure. Scheduled the exam after two weeks of video cramming and dumped $200 on what turned into a learning experience he didn't want. Three to six months of hands-on work with actual data pipelines, solid study time with a Professional Data Engineer study guide, consistent practice with real-world scenarios. That's the sweet spot most people need to hit.
Here's my recommendation. Final stretch preparation matters most.
Get quality Professional Data Engineer practice tests that mirror the real exam format. I'm talking about questions testing your understanding of GCP data pipeline design and operations, BigQuery optimization decisions, streaming versus batch trade-offs, machine learning on Google Cloud for data engineers. All the practical stuff showing up when you're designing data processing systems on GCP in actual work environments. The thing is, memorizing facts won't cut it here.
The Professional-Data-Engineer Practice Exam Questions Pack covers exactly what you need. Full scope of exam objectives with scenario-based questions that actually make you think through architecture decisions, not just regurgitate memorized answers. Use it in the last two weeks before your exam, treat wrong answers as genuine learning opportunities (because they are), and you'll walk into that test center or fire up the online proctored session way more confident than you'd expect.
And remember, Google Cloud certification renewal for Professional Data Engineer happens every two years. Getting certified's just the beginning. But cross that bridge later. Right now? Focus on passing this thing and adding those credentials to your LinkedIn profile.