NVIDIA NCA-AIIO (NVIDIA AI Infrastructure and Operations) Certification Overview
The NVIDIA NCA-AIIO certification is an industry-recognized credential that validates your expertise in deploying, managing, and operating AI infrastructure built on NVIDIA technologies. If you're working with GPU clusters, containerized AI workloads, or trying to keep ML services running smoothly in production, this cert proves you know what you're doing beyond just theory.
AI infrastructure isn't like traditional IT anymore. You're dealing with multi-GPU systems that cost more than a luxury car, workloads that can tank if you misconfigure resource allocation by even a small margin, and executives who expect 99.9% uptime for their shiny new AI initiatives. The thing is, they don't always understand why that's challenging to deliver consistently when you're managing bleeding-edge hardware and software stacks that weren't even possible a few years ago. The NCA-AIIO certification shows you can handle the operational complexity that comes with managing NVIDIA AI Enterprise software, orchestrating containerized AI applications, and troubleshooting issues before your data scientists start flooding Slack with complaints about job failures.
What NCA-AIIO validates (roles, skills, and outcomes)
This certification focuses on infrastructure and operations rather than development or data science. You're not writing CUDA kernels or building neural networks here. You're making sure the people who do that work have reliable, performant infrastructure that doesn't fall over when someone submits a training job that wants 32 GPUs.
The skills validated include GPU resource management across clusters, NVIDIA driver and software stack administration (which honestly gets messy fast if you don't know what you're doing), Kubernetes for AI workloads, monitoring and troubleshooting AI infrastructure, and capacity planning for ML workloads. Real-world stuff here. Applications? Managing multi-GPU clusters, deploying NVIDIA AI Enterprise software, implementing monitoring for GPU utilization, maintaining uptime for production ML services.
After certification you should be able to design resilient AI infrastructure and implement best practices for GPU cluster operations. You'll troubleshoot complex infrastructure issues where logs span multiple systems and everyone's pointing fingers. Plus you'll optimize resource utilization so you're not burning budget on idle GPUs.
Who should take the NCA-AIIO exam
IT administrators, that's who. Infrastructure engineers too. DevOps professionals, site reliability engineers, and cloud operations specialists working with AI/ML workloads. If you're currently managing servers and someone just dropped a requisition for a DGX system on your desk, this cert will help you not look completely lost.
This is also valuable for people transitioning from traditional infrastructure roles into AI-focused positions. Organizations are scaling machine learning initiatives and need folks who understand both infrastructure fundamentals and the specific quirks of GPU-accelerated workloads. Financial services companies running fraud detection models need this. Healthcare orgs deploying diagnostic AI need this. Autonomous vehicle companies, cloud service providers.. they all need people who can keep AI infrastructure running without constant handholding.
The certification complements other credentials you might already have. Got Kubernetes certifications? Great foundation. Linux admin background? Even better starting point. This stacks nicely with those and adds the NVIDIA-specific knowledge that makes you more valuable when companies are implementing DGX systems or building custom GPU-accelerated infrastructure.
How this differs from other NVIDIA certifications
NVIDIA has a whole portfolio of professional certifications, but NCA-AIIO focuses specifically on operational excellence and infrastructure management. Compare this to development-focused certifications or specialized deep learning credentials. Those are about building AI systems, while this is about keeping them running when things inevitably go sideways at 2 AM.
If you're looking at something like the NCA-GENL certification, that's oriented toward generative AI and LLMs from an application perspective. The NCP-AIO certification covers broader AI operations topics. NCA-AIIO sits in the sweet spot for people who manage the underlying infrastructure layer, dealing with GPUs, drivers, container runtimes, and orchestration platforms day-to-day.
While it's NVIDIA-specific in many ways, the concepts transfer. Container orchestration skills work across platforms. Infrastructure monitoring principles apply whether you're watching GPU utilization or CPU metrics or memory bandwidth saturation, which becomes critical with certain workloads. Resource scheduling and reliability engineering are universal concepts. You're just applying them to AI workloads with their unique characteristics.
Actually, I once watched a team spend three days troubleshooting what they thought was a network bottleneck before realizing their monitoring wasn't even capturing PCIe bandwidth properly. The model training was stalling because data couldn't move fast enough between host and GPU memory, not because of anything network-related. That kind of diagnostic thinking matters more than memorizing spec sheets.
Career impact and market demand
Growing demand for professionals who can manage AI infrastructure is real. Every mid-size company and larger is either running AI projects or planning to, and most of them are discovering their traditional IT teams don't know how to handle GPU clusters or ML platform reliability.
Not gonna lie, this certification opens opportunities in AI infrastructure teams, MLOps engineering roles, GPU cloud operations, and specialized AI platform administration positions. These roles didn't really exist five years ago. Now they're everywhere and often paying well because qualified candidates are scarce.
As AI infrastructure becomes critical enterprise infrastructure (not just experimental projects), operations expertise remains valuable across technology cycles. The specific tools might change but the core skills around reliability, monitoring, capacity planning, and troubleshooting stick around.
Exam format, time limit, and delivery method
The NCA-AIIO exam is delivered through Pearson VUE testing centers or online proctoring. You're looking at a performance-based exam format that tests practical knowledge, not just memorization. Expect hands-on scenarios where you need to demonstrate actual skills rather than just selecting multiple choice answers.
Time limits vary but plan for 2 to 3 hours. The exam tests your ability to work through realistic infrastructure scenarios under time pressure, which actually mirrors real operational work pretty well.
Exam cost (pricing, vouchers, regional variation)
NCA-AIIO exam cost runs around $300 to $400 USD depending on your region and any promotions NVIDIA might be running. Regional pricing variations exist, so check NVIDIA's official certification site for your specific location.
Some organizations purchase training bundles that include exam vouchers at a discount. If your employer is paying, ask about those. Otherwise you're buying the voucher directly through the registration process.
Passing score (what's published vs. what to expect)
NVIDIA doesn't always publish exact passing score percentages publicly, which is common for performance-based exams where scoring can be more complex than simple percentage-correct calculations. Different tasks might be weighted differently based on criticality.
That said, aim for 70 to 75 percent mastery across all domains to feel confident. Don't just barely scrape by on some domains while acing others. Operational roles require balanced knowledge because infrastructure problems don't care about your favorite topics.
Exam registration steps and policies
Registration happens through Pearson VUE after you create an account on NVIDIA's certification portal. You'll select your exam date, choose between test center or online proctoring, and pay for your voucher.
Rescheduling policies allow changes up to 24 to 48 hours before your exam slot, but last-minute cancellations might forfeit your fee. Read the specific policy when you register because it affects your flexibility if something comes up.
Exam objectives breakdown (domains and key tasks)
The NCA-AIIO exam objectives cover several major domains. Infrastructure fundamentals for AI workloads include compute architecture, GPU technologies, storage systems for AI datasets (which get huge fast), and networking considerations for distributed training.
Operations and reliability domain? That hits monitoring, logging, capacity planning, and incident response. You need to know how to set up monitoring that actually catches problems before they impact users, not just generates noise. Capacity planning for AI workloads is tricky because training jobs have different resource profiles than inference serving.
Platform and orchestration concepts cover containers and Kubernetes, especially Kubernetes for AI workloads which has some specific considerations around GPU scheduling. Also resource management and workload scheduling. Security and governance basics include access controls, workload isolation, and compliance considerations for regulated industries.
Official requirements vs. recommended background
Prerequisites officially don't exist. NVIDIA doesn't gate the exam behind other certifications or mandatory training courses. Practically though, you want solid Linux systems experience, networking fundamentals, and containerization knowledge before attempting this.
If you've never touched Kubernetes or don't understand how containers work, you're gonna struggle. Same if you're unfamiliar with basic networking concepts or haven't administered Linux systems. The exam assumes you know those foundations and tests how you apply them to AI infrastructure scenarios.
Suggested skills checklist: comfortable command-line work in Linux, understanding of virtualization and container technologies, basic networking like VLANs and routing and storage networks, and conceptual understanding of ML/AI workflows even if you're not a data scientist.
Difficulty by candidate profile
NCA-AIIO difficulty varies dramatically based on your background. New to IT? Honestly this is probably too advanced. Start with foundational Linux and networking certifications first. For experienced sysadmins, the difficulty is moderate if you take time to learn the AI-specific aspects.
DevOps professionals with Kubernetes experience often find this more approachable because container orchestration is already familiar territory. ML engineers sometimes struggle with the infrastructure operations aspects if they've only worked on model development without worrying about production deployment.
Common challenge areas include GPU resource management specifics (it's different from CPU scheduling), NVIDIA driver stack troubleshooting (version compatibility can be a nightmare), and capacity planning for AI workloads which behave differently than traditional applications. Address these by getting hands-on practice with actual NVIDIA hardware or cloud GPU instances.
Official NVIDIA training, docs, blueprints
Best study materials for NCA-AIIO start with official NVIDIA training courses if you can access them. NVIDIA offers instructor-led and self-paced options specifically aligned with certification objectives. The documentation for NVIDIA AI Enterprise software is essential reading. Dry but thorough.
NVIDIA's reference architectures and deployment blueprints provide real-world context for how infrastructure should be configured. Don't skip these thinking they're just marketing fluff. They contain actual architectural decisions and best practices from production deployments.
Community resources like NVIDIA Developer Forums and technical blogs help with specific troubleshooting scenarios. Reading about problems other people encountered (and solved) builds your troubleshooting intuition.
Hands-on labs and practical setup ideas
You need hands-on practice. Period. Reading about GPU cluster management isn't enough. If your employer has NVIDIA hardware, get access to a dev or test system. If not, cloud providers offer GPU instances you can spin up for practice. It costs money but less than failing the exam multiple times.
Set up a small Kubernetes cluster with GPU support. Install NVIDIA drivers and container runtime. Deploy some sample AI workloads and practice monitoring, troubleshooting, and resource management. Break things deliberately and fix them. That muscle memory matters during performance-based exam scenarios.
Study plan timing depends on your background. With strong infrastructure operations experience, 3 to 4 weeks of focused study might work. Coming from a different background, budget 6 to 8 weeks or more. Don't cram. The practical knowledge takes time to internalize.
What to look for in quality practice questions
Practice tests should mirror the performance-based format, not just offer multiple choice questions. Look for scenario-based questions that require multi-step problem solving. Quality practice materials explain why answers are correct and incorrect, helping you learn rather than just memorize.
Domain-by-domain practice helps identify weak areas. If you're consistently struggling with monitoring and observability questions, that tells you where to focus additional study time.
Validity period and recertification options
NCA-AIIO renewal timeline typically runs 2 to 3 years before recertification is required, though NVIDIA's specific policies should be verified on their certification portal. Renewal usually involves passing a current version of the exam or completing specific continuing education requirements.
Keeping skills current matters beyond just maintaining certification status. NVIDIA releases new software versions, platform updates, and features regularly. What you learned for the exam won't stay current without ongoing learning through documentation updates, webinars, and hands-on experimentation with new capabilities.
The certification gets you in the door but continuous learning keeps you valuable. The NCP-AII certification might be worth pursuing next if you want to deepen AI infrastructure knowledge, or explore NCP-AIN if networking for AI workloads interests you.
How much does the NVIDIA NCA-AIIO exam cost?
NCA-AIIO exam cost is approximately $300 to $400 USD. Pricing varies by region and current NVIDIA promotions. Check the official NVIDIA certification website for exact pricing in your location.
What is the passing score for NCA-AIIO?
NVIDIA doesn't publish the exact passing score publicly. Performance-based exams use weighted scoring across different tasks and domains rather than simple percentage calculations.
Is the NCA-AIIO certification hard for beginners?
Yes, absolutely. Complete beginners to IT infrastructure will struggle significantly. The exam assumes foundational knowledge of Linux systems, networking, and containerization. Experienced infrastructure professionals find it moderate difficulty with proper preparation.
What study materials are best for NVIDIA NCA-AIIO?
Official NVIDIA training courses, AI Enterprise documentation, reference architectures, and hands-on practice with GPU systems provide the best preparation. Combine theoretical study with practical lab work for optimal results.
How do I renew the NVIDIA NCA-AIIO certification?
Renewal typically requires passing the current exam version or completing continuing education requirements within 2 to 3 years of initial certification. Check NVIDIA's certification portal for specific renewal policies and timelines.
NCA-AIIO Exam Details
what the NVIDIA NCA-AIIO certification actually is
The NVIDIA NCA-AIIO certification targets folks keeping AI platforms alive. Not researchers. Not model architects. The people making GPU systems behave in production, under load, with users screaming when jobs tank.
The thing is, "AI infrastructure and operations" sounds fancy, but honestly, it's familiar territory if you've done sysadmin work, SRE stuff, or platform engineering. GPU nodes, drivers, CUDA-ish dependencies, container stacks, Kubernetes handling AI workloads, telemetry, plus those boring-but-necessary security controls everyone ignores until something breaks. You're proving you can keep an AI platform reliable, not that you'll train the next frontier model.
Your job includes phrases like GPU cluster operations and monitoring? Or you're getting paged when training runs fail at 2 a.m.? This exam fits. Same deal if you're supporting data science teams and you're tired of being the "Docker person" who also somehow owns the storage array.
Good candidates: Sysadmins moving into AI. DevOps engineers managing GPU nodes now. Platform teams rolling out NVIDIA AI Enterprise administration. ML engineers who got voluntold to run the cluster.
Brand new to IT? You can still pass, but expect pain. More on NCA-AIIO difficulty later.
format, timing, and how you take it
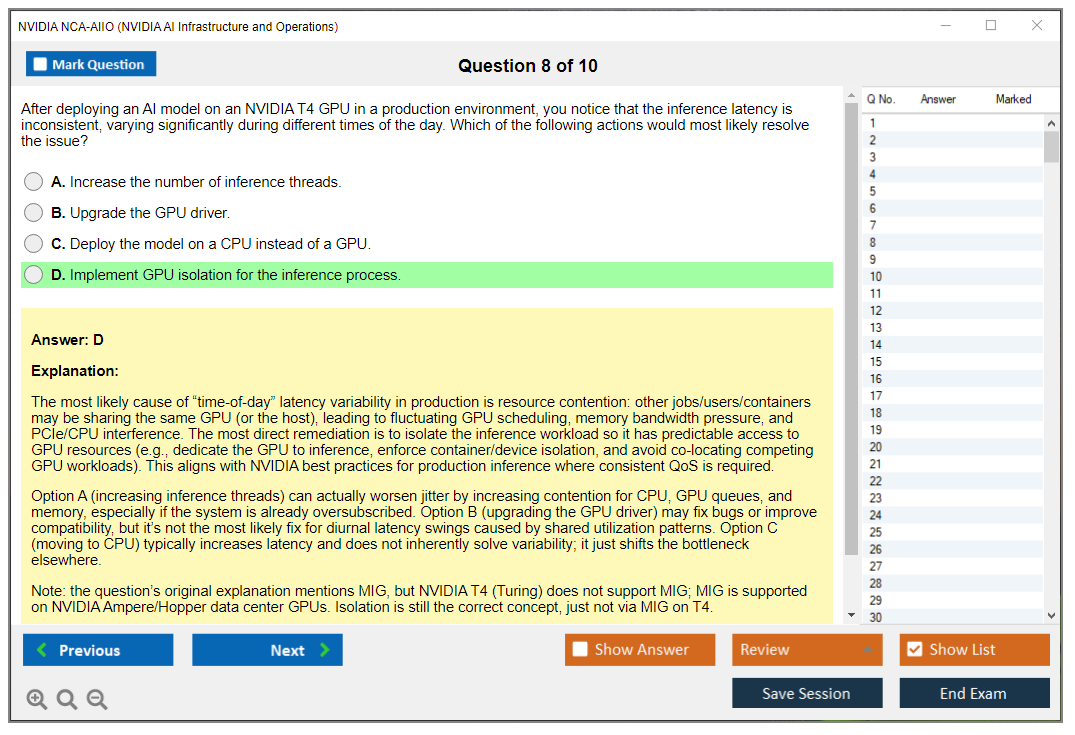
The exam format mixes multiple-choice with scenario-based questions. That matters. it's vocabulary and definitions. You'll face "what would you do next" situations testing whether you understand practical operations tradeoffs, like isolating a noisy neighbor workload on a shared GPU box or deciding what to check first when performance tanks.
Question count typically runs 60 to 75. Distribution gets weighted across domains, so expect a mix covering infrastructure, operations, platform, and security topics, not random scatter. I mean, you might hit several questions in a row on Kubernetes for AI workloads then swing into identity and access stuff. Normal.
Time limit? 120 minutes. Two hours. Do the math and you're sitting at roughly 90 to 120 seconds per question, and that includes reading longer scenarios, thinking, choosing the best answer. Some questions fly by. Some get wordy. A couple will make you re-read because the "best" answer reflects operational reality, not textbook purity.
Delivery method offers either proctored online through NVIDIA's certification platform or authorized testing centers. Remote proctoring's the big win for global accessibility. Convenient, sure, but stricter than people expect.
what your testing setup needs to look like
Online proctoring comes with exam environment requirements. Stable internet. Webcam. Microphone. Clean workspace. Government-issued ID. Compatible browser. All of it.
Do the system check early.
Also, the proctor usually requires an environment scan where you'll pan the camera around the room. No extra monitors. No notes. No "my phone is face down." Put it away. Shared space? Don't risk it. The AI-powered proctoring plus human review flags weird stuff, and fighting a disqualification is absolutely miserable.
exam cost, vouchers, and regional pricing
The NCA-AIIO exam cost sits at $300 USD as of 2026. Pricing varies by region and promos, so don't tattoo that number on your brain forever, but it's the working figure.
Regional pricing variations are real. Some countries show local currency pricing that's not a straight conversion, and certain regions get discounts for students or academic programs. You're at a university lab or you've got an EDU email? Check the portal and any NVIDIA academic options before paying full price.
Voucher options exist. Corporate training packages sometimes bundle an exam voucher, NVIDIA partner program members can snag discounted vouchers, and bulk purchases drop the per-exam price. Mentioning the rest quickly: event promos, internal enablement budgets, and training bundle retakes sometimes happen, depending on your org.
Payment methods are standard. Major credit cards work. Enterprise customers often use purchase orders. Some folks pay with training credits through NVIDIA's learning platform, which is nice if your company already buys credits and you just need approval.
passing score, scoring model, and what you'll see after
The NCA-AIIO passing score commonly gets described as 70%, often shown as a scaled score of 700 on a 1000-point scale. NVIDIA doesn't always publish an exact cut score publicly for every version, so treat the "70%" as the practical target, not a promise carved in stone.
Scaled scoring explanation, plain terms: your raw correct answers get converted to a scaled score adjusting for difficulty differences across exam forms. If one version has slightly harder questions, scaling keeps the passing standard consistent. Fairness thing. It's also why comparing "I got X questions wrong" with your friend is pointless.
No partial credit exists. Each question's right or wrong. Multiple-choice? You don't get points for "almost." That pushes you toward learning concepts, not pattern-matching.
Score reporting happens immediately for pass/fail when you finish. Fail? You typically get a breakdown by domain showing where you were weak.
That breakdown is gold.
Score validity applies per attempt. Retakes get scored independently. No averaging. No mercy points for "improved a lot."
registration, scheduling, rescheduling, and ID rules
Exam registration process is straightforward: create an NVIDIA certification account, pick the exam, choose online or test center, schedule, pay. The only annoying part? Getting your name to match your ID exactly. Your account says "Mike" and your passport says "Michael"? Fix it first. Honestly, don't gamble on the proctor letting it slide.
Scheduling flexibility works better online. Many online proctored slots are available 24/7, and you can often book up to 24 hours in advance. Test centers have limited hours, fewer seats, and sometimes a long wait, especially in busy cities.
Rescheduling policies typically let you move your appointment up to 24 hours before without penalty. Late cancellations can forfeit the fee. Read the confirmation email. Screenshot the policy. People get burned here.
Identification requirements: government-issued photo ID matching registration. Some sessions ask for a secondary ID, especially online. Keep something like a credit card or other official ID handy if the provider lists it.
Testing accommodations exist. You request them in advance with documentation. Extra time, screen readers, other modifications. Don't wait until the day before. It's paperwork.
Language availability is primarily English, with additional options in some regions. Check the portal because this changes, and you don't want to discover on exam day that your preferred language isn't offered.
Non-disclosure agreement is mandatory. You accept the NDA before starting, and you cannot share exam questions or exact scenarios afterward. Don't post "here's what I saw." Not worth it.
Exam security measures are intense online: AI-powered proctoring, screen recording, environment scans, behavioral monitoring. Technical support exists for platform issues, plus pre-exam system checks, but they won't help with content. Your browser crashes? They can help. You don't know what MIG is? You're on your own.
Results timeline after passing: you get the pass status immediately, and the official digital certificate usually shows up within 5 to 7 business days.
Certificate delivery is digital. Badge and PDF in the portal. No physical certificate. Verification for employers typically happens through NVIDIA's public verification system using your name and certification ID.
what the NCA-AIIO exam objectives feel like in practice
The NCA-AIIO exam objectives tend to map to four buckets: infrastructure, operations, platform, and security. That's the core mental model I'd study with.
Infrastructure fundamentals for AI workloads includes compute and GPU basics, storage patterns that don't choke training jobs, and networking that doesn't fall apart when you scale. You should be comfortable with the operational side of GPU nodes: drivers, container compatibility, and the "why is my framework not seeing the GPU" class of issues. Not fun. Very real.
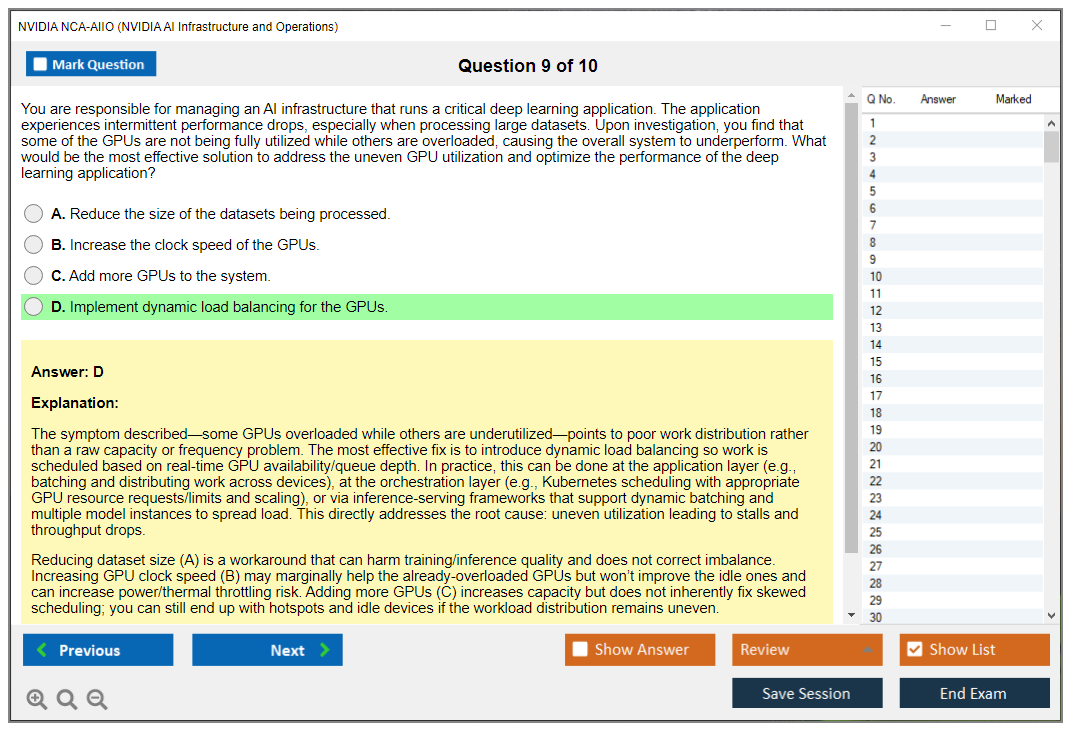
Operations and reliability is where the exam earns its name. Monitoring, logging, capacity planning, and incident response. You'll see questions that sound like an on-call ticket: utilization is weird, jobs fail after a node reboot, latency spikes on inference, or someone pushed a config change and now half the cluster is flaky. MLOps and AI platform reliability shows up here, mostly as "keep it stable," not "build a fancy pipeline."
Platform and orchestration concepts means containers and Kubernetes for AI workloads. Scheduling. Resource management. How you isolate workloads. What you monitor. How you reason about GPU allocation and contention. This is also where many candidates stumble, because they know Kubernetes generally but haven't dealt with GPU-specific scheduling behaviors and the operational gotchas.
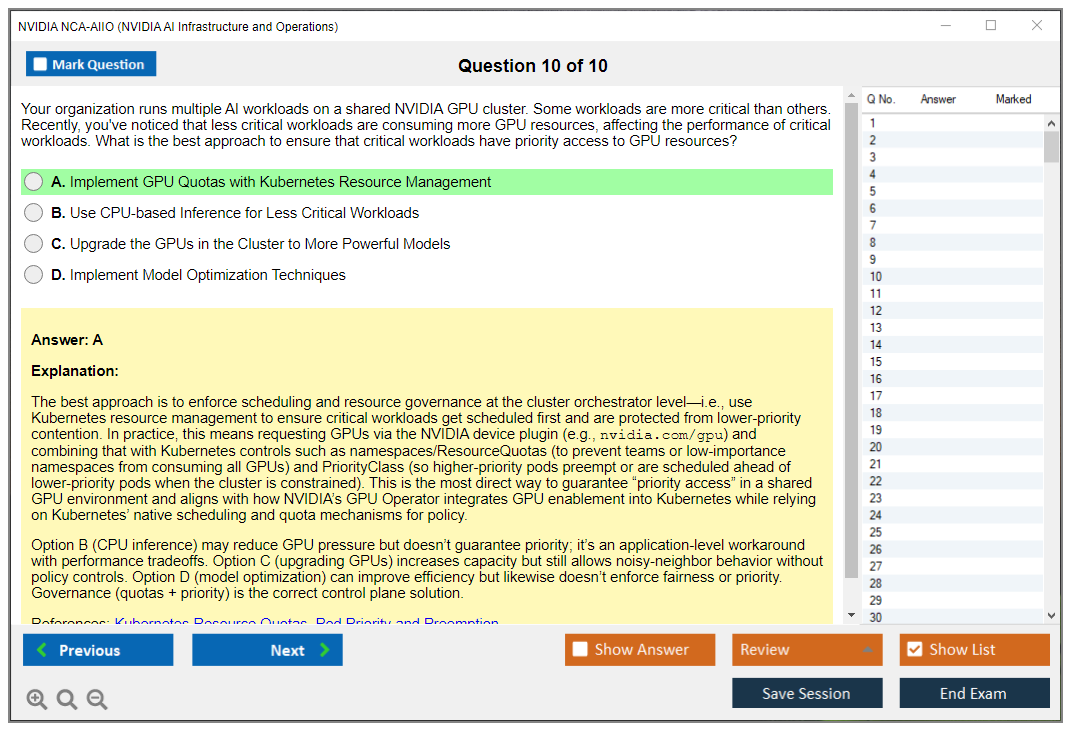
Security and governance basics is less about being a security engineer and more about not doing reckless things. Access control, isolation, compliance considerations, and sane operational hygiene. Secrets handling, audit trails, and basic segmentation concepts matter here too.
I was talking to someone last week who failed twice before passing, and both times they ignored the security domain because "it's only like 15% of the questions." Then they got three long scenarios back-to-back about role assignments and secret management during their third attempt. Don't be that person.
prerequisites and recommended background
The NCA-AIIO prerequisites are usually light on strict requirements, but the recommended background isn't. You want comfort with Linux basics, networking fundamentals, and containers. Never tailed logs, checked systemd services, or debugged DNS? You're going to spend your study time catching up.
Suggested skills: Linux CLI and basic troubleshooting. Basic TCP/IP and network flows. Docker and container runtimes. Some Kubernetes familiarity. Comfort reading monitoring dashboards. Basic understanding of how ML training and inference consume compute.
That's it. Still a lot.
difficulty: who struggles and why
NCA-AIIO difficulty depends on your starting point.
New to IT? Hard. You're learning ops concepts and AI platform concepts at the same time, and scenario questions punish shallow memorization.
Sysadmins usually do fine on infrastructure and troubleshooting, but they may trip on Kubernetes scheduling and AI platform specifics. DevOps folks often crush containers and orchestration but may underweight hardware realities like storage throughput, PCIe constraints, or GPU node maintenance practices. ML engineers can be great at the "why" of workloads yet weaker on the "how" of running the platform day after day without outages.
Common challenge areas: Kubernetes GPU scheduling, driver and container compatibility, diagnosing performance bottlenecks, and security basics that ops people skip because "it's internal." Fix it by doing hands-on practice, not only reading.
study materials and hands-on prep
The best NCA-AIIO study materials are usually the official NVIDIA training and the docs, plus the exam blueprint if NVIDIA publishes one for your version. Read the objectives like a checklist. An objective says "monitoring and incident response"? You should be able to explain what you monitor, what alerts matter, and what first steps you take.
Hands-on labs help more than people admit. Even a single GPU workstation can teach you tons: install drivers, validate with basic tools, run containers that need GPU access, and break things on purpose so you can recover. If you can get access to a small Kubernetes cluster, practice scheduling GPU workloads and observing resource behavior.
Study plan ideas: 1 to 2 weeks if you already run GPU systems and Kubernetes and you just need to align with the exam shape. 3 to 4 weeks for most working sysadmins or DevOps folks. 6 to 8 weeks if you're new to either Kubernetes or GPU operations and you need repetition.
practice tests and exam strategy
NCA-AIIO practice tests are useful if they're scenario-heavy and explain why answers are right or wrong. Avoid cheap dumps. Not only because it's unethical and against the NDA vibe, but because they train you to memorize patterns, and the exam likes practical judgment.
Domain-by-domain practice works. Do a set focused on infrastructure, review misses, then operations, then platform, then security. Keep notes. Short ones. You're building an ops playbook in your head.
Final week: confirm your exam environment, run the system check, clean your desk, and do timed question sets so 120 minutes doesn't feel tight. On exam day, don't get stuck. If a scenario's eating time, mark it and move on. Your goal is points, not perfection.
renewal and how long it stays valid
The NCA-AIIO renewal policy depends on NVIDIA's current certification rules, and those can change, so you need to verify inside the portal for your credential version. Some certifications have a validity period and require recertification or a newer exam to stay current.
Keeping skills current is the real answer anyway. Drivers change. Kubernetes changes. NVIDIA AI Enterprise administration changes. You treat this like a one-and-done? You'll be out of date fast, and your next on-call shift will remind you.
FAQ
The NCA-AIIO exam cost is $300 USD as of 2026, with possible regional currency differences and discounts through students, academics, or partner programs.
The NCA-AIIO passing score is typically communicated as 70%, often represented as a scaled 700 out of 1000, though exact cut scores may not be publicly fixed across all versions.
Yeah, for beginners it can be tough because it mixes Linux and platform ops with GPU and Kubernetes concepts, and the scenario questions reward hands-on experience over memorization.
Start with official NVIDIA training, the exam blueprint and objectives, and NVIDIA documentation, then add hands-on labs around GPU setup, containers, and Kubernetes scheduling.
Check your credential in the NVIDIA certification portal for the current NCA-AIIO renewal policy, including validity period and recertification options, since rules can change by version and over time.
NCA-AIIO Exam Objectives (What You'll Be Tested On)
Four domains and how they split the questions
The NCA-AIIO exam objectives break down into four main domains, and honestly they're weighted in a way that makes sense when you think about what you're actually doing day-to-day. Big focus on operations. Operations and reliability grabs the biggest chunk at 35%, which tells you something. NVIDIA knows that keeping AI infrastructure running is where most of your time goes. I mean, it's literally the job when things break at midnight and engineers are screaming about failed training runs. Infrastructure fundamentals sits at 30%, platform and orchestration takes 25%, and security/governance rounds out the exam at 10%.
Not gonna lie, that 10% security allocation might seem small, but those questions tend to be scenario-based and can trip you up if you're not thinking about multi-tenancy or compliance requirements. The weighting basically mirrors what an AI infrastructure operator or administrator actually deals with, which is refreshing compared to some vendor exams that test obscure features you'll never touch.
Matching exam content to what you'll actually do at work
Look, the exam domains aren't just random knowledge buckets. They line up pretty directly with real-world responsibilities you'd have managing GPU clusters for machine learning teams. You'll troubleshoot GPU memory errors at 2 AM. You'll explain to data scientists why their training job died because they requested 8x A100s but didn't account for NVLink topology. Or wait, actually sometimes it's because they just wrote terrible code but blamed the infrastructure anyway. Which is frustrating but you still gotta diagnose it professionally.
You'll architect storage solutions that don't become bottlenecks when fifty researchers try pulling 500GB datasets at once. The objective connection to job tasks is actually one of the stronger aspects of this certification. Real-world stuff. I've seen plenty of certs where you memorize feature lists that don't translate to actual work, but NVIDIA structured this around operational scenarios. When the exam asks about DCGM configuration or pod scheduling for multi-GPU workloads, those are things you really need to know if you're running a production AI platform.
Where to find the detailed breakdown
NVIDIA publishes a detailed exam blueprint on their certification portal. Go grab it before you start studying seriously. The blueprint availability makes prep way more productive because it lists specific subtopics and knowledge areas under each domain. Instead of guessing what "infrastructure fundamentals" means, you get granular callouts like "PCIe topology considerations" or "NVSwitch interconnect architecture."
The blueprint also hints at cognitive levels tested, which matters more than people realize. Some questions are pure recall. What's the command syntax for nvidia-smi to show GPU temperature? Others hit application level. You get a scenario where training is slower than expected and you need to diagnose whether it's compute-bound, memory-bound, or network-bound, which honestly requires you to understand performance profiling at a pretty deep level, not just surface knowledge. Then you've got analysis questions about design decisions where you're choosing between scale-up versus scale-out approaches based on workload characteristics. Or optimization strategies that require understanding tradeoffs.
GPU and compute infrastructure you need to understand
You'll absolutely need solid knowledge of NVIDIA GPU families relevant to AI workloads. That means understanding A100, H100, and L40S capabilities. Not just memorizing spec sheets, but knowing when you'd pick each one. An H100 brings massive performance for large language model training, but maybe you're running inference workloads where L40S gives you better TCO. Compute capabilities matter because they determine what CUDA features you can use. Memory hierarchies affect how you optimize data movement.
Server configurations for AI workloads go way beyond "stick GPUs in a box." You need to understand DGX systems as integrated appliances versus HGX platforms that OEMs build into certified servers. CPU-GPU ratios matter. Underpowering your CPU can bottleneck data preprocessing, which I've seen happen more times than I can count when teams go GPU-heavy but skimp on the host processors. PCIe topology becomes critical when you're running multi-GPU training and need to understand which GPUs can communicate directly versus going through CPU hops.
NVLink and NVSwitch interconnects? Big topics. NVLink gives you high-bandwidth GPU-to-GPU communication that's way faster than PCIe. NVSwitch creates all-to-all connectivity in systems with many GPUs. If you don't understand these, you'll struggle with questions about optimal configurations for distributed training workloads. There's also this whole consideration around power delivery that doesn't get talked about enough in study materials but definitely shows up on the exam.
Storage and networking considerations that trip people up
High-performance storage requirements for AI datasets aren't like regular enterprise storage. You're dealing with potentially petabytes of training data that needs to feed dozens of GPUs at once without becoming the bottleneck. Parallel file systems like Lustre or GPFS show up in exam scenarios. NVMe storage and data locality optimization, keeping data physically close to compute resources, these concepts appear in capacity planning and troubleshooting questions.
Networking for AI clusters deserves serious study time. The thing is, the InfiniBand versus Ethernet debate for AI workloads isn't just "InfiniBand is faster." You need to understand RDMA protocols, latency sensitivity for collective operations during distributed training, and when Ethernet with RoCE might be sufficient depending on your budget constraints and scaling plans. Network topology design comes up too. Fat tree architectures or rail-optimized topologies. Bandwidth requirements for distributed training scale with GPU count and model size, and you'll see questions asking you to calculate or estimate these.
Software stack and framework integration
The NVIDIA software stack layers are something you'll get tested on repeatedly. CUDA drivers form the foundation. You need to know installation procedures, troubleshooting common driver issues, version compatibility. The NVIDIA Container Toolkit enables GPU access from containers, which is basically required for modern AI infrastructure. GPU Operator for Kubernetes automates deploying and managing the GPU software stack across cluster nodes.
Mixed feelings here. Understanding how TensorFlow, PyTorch, and other frameworks interact with NVIDIA infrastructure matters because framework-specific requirements affect your infrastructure decisions. PyTorch might need certain CUDA versions, TensorFlow has specific cuDNN dependencies. Compatibility matrices showing which NVIDIA driver versions work with which CUDA versions and frameworks, yeah, you need to know how to work through those and make correct compatibility decisions.
Operations domain deep dive
GPU cluster operations and monitoring is the heaviest weighted area, so expect lots of questions here. Real-time monitoring using nvidia-smi is baseline knowledge. You'll need hands-on familiarity with DCGM. Installation, configuration, what metrics it collects, how you integrate it with Prometheus and Grafana. I mean, if you haven't actually set up DCGM and scraped metrics into a monitoring stack, you're going to struggle with scenario questions.
Performance troubleshooting scenarios? Common. You'll diagnose GPU underutilization. Is the training code terrible? Is data loading the bottleneck? Are GPUs waiting on network for gradient synchronization? Profiling tools like Nsight Systems and Nsight Compute come up, and you should understand when to use each one.
Incident response procedures cover handling GPU failures. Driver crashes, out-of-memory errors. Capacity management means tracking utilization trends and planning expansions. Job scheduling with competing workloads, priority policies, preemption strategies, these operational realities show up frequently, and honestly they're the questions that separate people who've actually run production systems from folks who just read documentation. The NCA-AIIO practice questions I've seen include really solid scenario-based items around these topics.
Platform orchestration with Kubernetes
The Kubernetes for AI workloads domain assumes you understand container orchestration fundamentals. Control plane architecture, worker nodes, how etcd fits in. NVIDIA GPU Operator automates managing the GPU software stack in Kubernetes environments, and you'll definitely see questions about how it works and what components it deploys.
GPU device plugin configuration? Critical. This is what exposes GPUs as schedulable resources. You need to understand resource limits and requests for GPU pods. How to specify multi-GPU requirements. Node selectors and affinity rules for placing GPU workloads on appropriate nodes.
Storage orchestration with persistent volumes for large datasets. CSI drivers for high-performance storage. Helm charts for deploying AI applications, these are all fair game. Job and CronJob resources for batch training workloads appear in questions. Understanding AI-specific platforms like Kubeflow helps, though you don't need to be a Kubeflow expert for this exam.
Security and governance essentials
Even though it's only 10% of the exam, don't skip security and governance topics. RBAC for GPU resources, MIG (Multi-Instance GPU) for secure multi-tenancy, container image scanning, secrets management, these come up. Network security patterns like encryption in transit and network segmentation matter when you're running multi-tenant AI platforms.
Compliance considerations appear in scenario questions. You might get asked how to handle HIPAA requirements for healthcare AI workloads or GDPR data residency constraints, which honestly can get pretty nuanced when you're dealing with distributed training across multiple regions but need to keep certain data localized. Audit logging, vulnerability management for NVIDIA drivers, policy enforcement with admission controllers, study these even though they're a smaller percentage.
If you're coming from a traditional sysadmin background, check out the NCP-AII certification as a stepping stone since it covers some foundational AI infrastructure concepts. For those already working with AI platforms, the NCA-GENL certification complements this nicely if you want to understand the generative AI application side.
Cognitive levels and question types you'll encounter
The mix of cognitive levels keeps the exam from being pure memorization. Recall questions test terminology and concepts. What's the difference between NVLink and NVSwitch? What DCGM metric tracks GPU memory errors? Table stakes stuff.
Application questions give you troubleshooting scenarios or configuration tasks. You'll see monitoring dashboards with anomalies and need to identify the root cause. You'll get deployment requirements and need to select appropriate hardware configurations. Analysis questions are trickier, comparing design approaches, evaluating optimization strategies, choosing between architectural patterns based on specific constraints.
The NCA-AIIO exam objectives preparation really benefits from hands-on lab time. Reading documentation helps with recall, but actually configuring GPU Operator in a Kubernetes cluster, debugging failed training jobs, tuning storage performance, that's how you build the applied knowledge for scenario questions.
The certification also relates to broader NVIDIA credential paths. The NCP-AIN certification focuses specifically on AI networking if that's your specialty area, while NCP-AIO dives deeper into operations aspects. Understanding how these certs connect helps you plan a coherent certification strategy rather than randomly collecting credentials.
Prerequisites and Recommended Experience
Official requirements versus what you really need
NVIDIA's pretty upfront about the NCA-AIIO prerequisites on paper: there aren't any. No mandatory class. No "you must already hold X cert." Zero gatekeeping. The NVIDIA NCA-AIIO certification exam's open to anyone wanting to prove they can handle AI infrastructure and ops tasks.
That said. Open enrollment isn't the same thing as open difficulty.
Look, the exam targets people doing real-world NVIDIA AI infrastructure operations certification type work, which means if you register with zero Linux, zero containers, and "networking is my router password" level knowledge, you're setting yourself up for pain. Not gonna lie, that's where the NCA-AIIO difficulty spikes and where people start hunting for the NCA-AIIO passing score like it's gonna save them. It won't. If the foundations aren't there, questions that should feel like routine operational decision-making turn into guesswork, and the pass rate for that profile's obviously gonna be lower.
So yes, the exam's open. But prerequisites still matter. They matter 'cause they predict whether this is "prep and pass" or "pay the NCA-AIIO exam cost twice."
Recommended experience level (the realistic baseline)
If you want a practical target, I like the "6 to 12 months hands-on" guideline, and specifically hands-on with Linux system administration, container tech, and infrastructure operations. Not reading blog posts. Touching systems. Breaking things in a lab. Fixing them. Repeating.
Some people can compress that timeline. Others need longer. But as a general bar, at least 6 months of Linux administration in something resembling production, or a serious home lab where you treat it like production, is a good minimum. Same vibe for containers: 3 to 6 months working with Docker, plus basic Kubernetes exposure, is where you stop feeling lost and start feeling like you're operating a platform.
And honestly, the "ops mindset" matters too. Tickets. Incidents. Change windows. Root cause notes. If you've never been on-call, you can still pass, but a bunch of scenarios will feel abstract instead of familiar.
Self-assessment before you register (do this, seriously)
Before paying for the exam, do a quick readiness audit across the skill areas the NCA-AIIO exam objectives imply. I mean, you don't need to write a spreadsheet unless you're that person. But you should be able to answer "can I do this without Googling every step" for the basics.
Here's a checklist that maps well to what shows up in AI infrastructure operations work:
- Linux command line and admin basics
- Monitoring and performance tools
- Logs and troubleshooting flow
- Process and service management
- Shell scripting for automation
- TCP/IP and network troubleshooting
- Firewalls and access control concepts
- Containers (Docker) and registries
- Kubernetes fundamentals, at least at the kubectl level
- Basic GPU and AI workload awareness
- Monitoring stacks, metrics, dashboards, plus alerting
If half of that list feels fuzzy, slow down. That's not a moral failing. It just means you're not ready yet, and your study plan should include foundational learning, not only NCA-AIIO study materials and NCA-AIIO practice tests.
Linux skills you should already have
Linux is the daily driver for this cert's job role. You need command-line comfort, not just "I can SSH in."
At minimum, you should be good with file system navigation and manipulation. Know where logs live. Know how to find stuff fast. Permissions shouldn't be mysterious either, 'cause AI platforms are full of "why can't this service read that file" problems. Users, groups, sudo, chmod, chown. The basics.
Package management matters more than people expect. You should know how apt and yum (or dnf) behave, how repos work at a basic level, and how to verify what's installed. The questions won't be "type this exact command" as much as "what would you do next" in a scenario where nodes need consistent dependencies.
Three short truths. Linux bites. Permissions bite harder. Package chaos is real.
Monitoring tools (know what "bad" looks like)
For performance monitoring, you should understand what the classic tools are telling you: top, htop, iostat, vmstat, sar. Not every flag. The meaning.
If iostat shows high await times, what does that suggest about storage? If vmstat shows swapping, what does that imply about memory pressure? If load average's high but CPU's idle, what are you suspecting next? AI workloads make these signals louder 'cause they can hammer CPU, RAM, disk, and network in weird combos, especially when data pipelines are involved and not just GPU compute.
And yes, GPU cluster operations and monitoring adds another layer later, but the exam expects you to understand the standard OS-level symptoms first.
Log file analysis (the unglamorous superpower)
Logs are where the truth is. You should be able to read system logs and not panic.
Know journalctl well enough to filter by unit, follow logs live, and slice by time. Understand the idea of log rotation, 'cause "the disk filled up" is one of the most boring, common outages on the planet, and AI nodes with chatty services can fill disks faster than you'd expect.
Fragments. Grep's your friend. So's knowing when not to grep.
Process and service management (systemd is everywhere)
You should be comfortable with systemd basics: checking service status, restarting, reading unit logs, enabling or disabling on boot. Also process monitoring and control, like identifying runaway processes, understanding resource consumption, and knowing what resource limits are conceptually (ulimits, cgroups at a high level).
This matters 'cause AI infrastructure's a pile of daemons. Container runtimes. Monitoring agents. GPU persistence services. Kubernetes components if you're on that path. If you can't reason about services, you'll struggle to reason about the platform.
Shell scripting basics (automation, not wizardry)
You don't need to be a Bash poet. But you should be able to automate repetitive ops tasks.
Think simple scripts that validate disk space, check service health, parse a log for error counts, or roll through nodes and run a command. Basic sed and awk for log parsing's a big win. Not advanced one-liners that impress strangers. Just enough to get signal out of noise.
Networking baseline (the "I can troubleshoot" level)
TCP/IP basics are non-negotiable. IP addressing, subnetting fundamentals, routing basics, and DNS resolution. If you can't explain what happens when DNS breaks, you'll misdiagnose half your incidents.
Then you need practical troubleshooting tools: ping, traceroute, netstat or ss, and tcpdump. Not full packet forensics, but enough to confirm "is traffic flowing," "is a port listening," and "is the handshake even happening." AI clusters also tend to have multiple networks (management, storage, high-speed fabric), so being able to reason about paths matters.
Firewall concepts come up too: basic iptables or nftables awareness, plus cloud security groups and network access control ideas. You don't have to be a security engineer. You do need to avoid accidentally locking yourself out or exposing something dumb.
High-performance networking like RDMA and InfiniBand's helpful but not mandatory. If you've heard the terms and know they exist for low-latency, high-throughput GPU-to-GPU and node-to-node communication, you're ahead. Same with load balancing basics: distributing traffic, health checks, failover. You're not building a global CDN here, but you should understand what a load balancer's doing when an endpoint starts failing.
A good target's Network+ level knowledge, or equivalent time spent troubleshooting real networks.
Containers and Kubernetes (the daily ops layer)
Container fundamentals are core. Docker concepts, images versus containers, writing a basic Dockerfile, and managing the container lifecycle. If you can't build an image, tag it, run it, inspect it, and clean it up, you're gonna feel behind.
Registries matter too. Pulling and pushing images, private registry concepts, and tagging strategies. Honestly, half of "it worked on my machine" becomes "it pulled the wrong tag" once you're operating at scale.
Docker networking's another common weak spot. Bridge networks, host networking, container-to-container communication. Volume management also shows up fast: bind mounts, named volumes, persistence, and what happens when you redeploy.
Kubernetes basics are "highly beneficial" for a reason. You should know pods, deployments, services, namespaces, and be comfortable with kubectl. Scheduling and service discovery concepts matter 'cause Kubernetes for AI workloads has special constraints, like GPU resources, node selectors, taints and tolerations, and resource requests or limits. You don't need to be a cluster architect, but you should understand how workloads land on nodes and how config gets into containers.
Recommended container experience: 3 to 6 months with Docker, plus basic Kubernetes exposure. More's better. Obviously.
GPU and AI basics (ops-focused, not data science)
You need basic GPU concepts: GPU versus CPU, parallel processing, and why GPUs are used for deep learning. Also the resource profile of AI workloads: they can be memory-hungry, they can saturate IO, and they can be sensitive to driver or runtime mismatches.
NVIDIA product familiarity helps. You don't need to memorize every SKU, but you should be aware of datacenter GPU families, DGX systems as a packaged platform, and what NVIDIA's enterprise software ecosystem looks like, including NVIDIA AI Enterprise administration as a concept.
AI and ML workflow basics are useful too: training versus inference, what deployment looks like, and common frameworks like TensorFlow and PyTorch. You're not required to be an ML expert. The exam's about infrastructure operations, not building models. Still, if you don't understand what the workloads are trying to do, you'll make bad operational decisions, and that bleeds into MLOps and AI platform reliability thinking.
Monitoring, metrics, and on-call reality
Metrics collection's a whole skill set. You should understand time-series metrics, the idea of pull versus push monitoring models, and the basic shapes of monitoring architectures.
Grafana familiarity helps, especially dashboards and alerting concepts. Log aggregation's also part of modern ops. You don't need to run ELK in anger, but you should understand centralized logging, why it exists, and how it changes troubleshooting.
Alerting strategy matters. Threshold alerts are easy and noisy. Anomaly detection basics are nice to know. On-call response's the real thing: acknowledge, triage, mitigate, then fix, then write it down.
Recommended monitoring background: real experience with at least one stack, like Prometheus, Nagios, Datadog, or similar.
If you're missing pieces, do this first
If your Linux experience's limited, take Linux Foundation LFS101 (free) or a similar intro Linux course before serious NCA-AIIO prep. If you have no container background, do Docker fundamentals and Kubernetes basics training for 1 to 2 months, then come back with hands-on reps. If networking's minimal, Network+ prep or a networking fundamentals course'll pay off quickly.
No GPU exposure? Start with the basics: learn what nvidia-smi's for, understand driver versus CUDA concepts at a high level, and read a beginner-friendly overview of how GPUs are scheduled and monitored in containerized environments. That alone removes a lot of fear.
And one last opinion. The thing is, wait, I'm getting ahead of myself here. Don't obsess over the NCA-AIIO renewal policy or the exact NCA-AIIO passing score before you can confidently troubleshoot a Linux service and a container pull failure. Get the fundamentals, then worry about the paperwork.
Conclusion
Wrapping up your NCA-AIIO path
Real talk here. Getting your NVIDIA NCA-AIIO certification? That's not something you just accidentally fall into. It takes genuine preparation, the kind where you're actually rolling up your sleeves and diving deep into GPU cluster operations and monitoring, Kubernetes for AI workloads, MLOps and AI platform reliability, all of it.
You've already absorbed the breakdown on NCA-AIIO exam objectives, you're aware the NCA-AIIO exam cost hovers around $250-300 (depends on your region, honestly), and you understand that while the NCA-AIIO passing score typically sits somewhere around 70%, NVIDIA keeps that exact threshold pretty locked down.
Here's what I've noticed. The NVIDIA AI infrastructure operations certification is exploding right now. Companies running NVIDIA AI Enterprise desperately need people who really understand how to keep these systems alive and humming smoothly, not just folks who attended one webinar and called it a day. The thing is, the NCA-AIIO difficulty hits hard for anyone without real hands-on experience with GPU systems and container orchestration, but it's completely manageable if you've been working with this stack or you dedicate focused study time using quality NCA-AIIO study materials.
The hands-on component? Don't skip it. Just don't. Reading documentation about driver troubleshooting or resource scheduling is helpful, sure, but actually spinning up a test environment and deliberately breaking things, then fixing them, that's what'll cement those concepts way better than any video course ever could. Combine that practical work with solid NCA-AIIO practice tests and you're setting yourself up properly.
Quick tangent about the NCA-AIIO prerequisites. Yeah, NVIDIA officially says there aren't strict requirements listed, but let me be blunt: you're gonna struggle massively if you've never touched Linux administration or don't grasp basic networking and storage concepts. Be realistic with yourself about your starting point and plan your timeline accordingly. I've seen people with zero command-line experience try to speedrun this thing in two weeks. It never ends well.
Oh, and the NCA-AIIO renewal policy gives you two years before recertification, which honestly provides breathing room to actually apply these skills in production environments before stressing about keeping the cert current.
If you're serious about passing on your first attempt, I mean really serious, grab a quality resource that mirrors the actual exam format. The NCA-AIIO Practice Exam Questions Pack delivers that domain-specific practice with scenarios matching what you'll face on test day. Not gonna sugarcoat it: practice questions covering the full spectrum of infrastructure fundamentals, operations tasks, and platform concepts make a tremendous difference when you're sitting in that proctored exam second-guessing whether you studied the right material.
You've got this.
Now go build something.