DevOps-SRE Practice Exam - PeopleCert DevOps Site Reliability Engineer (SRE)
Reliable Study Materials & Testing Engine for DevOps-SRE Exam Success!
Exam Code: DevOps-SRE
Exam Name: PeopleCert DevOps Site Reliability Engineer (SRE)
Certification Provider: PEOPLECERT
Certification Exam Name: DevOps


Free Updates PDF & Test Engine
Verified By IT Certified Experts
Guaranteed To Have Actual Exam Questions
Up-To-Date Exam Study Material
99.5% High Success Pass Rate
100% Accurate Answers
100% Money Back Guarantee
Instant Downloads
Free Fast Exam Updates
Exam Questions And Answers PDF
Best Value Available in Market
Try Demo Before You Buy
Secure Shopping Experience
DevOps-SRE: PeopleCert DevOps Site Reliability Engineer (SRE) Study Material and Test Engine
Last Update Check: Mar 18, 2026
Latest 40 Questions & Answers
45-75% OFF
Hurry up! offer ends in 00 Days 00h 00m 00s
*Download the Test Player for FREE
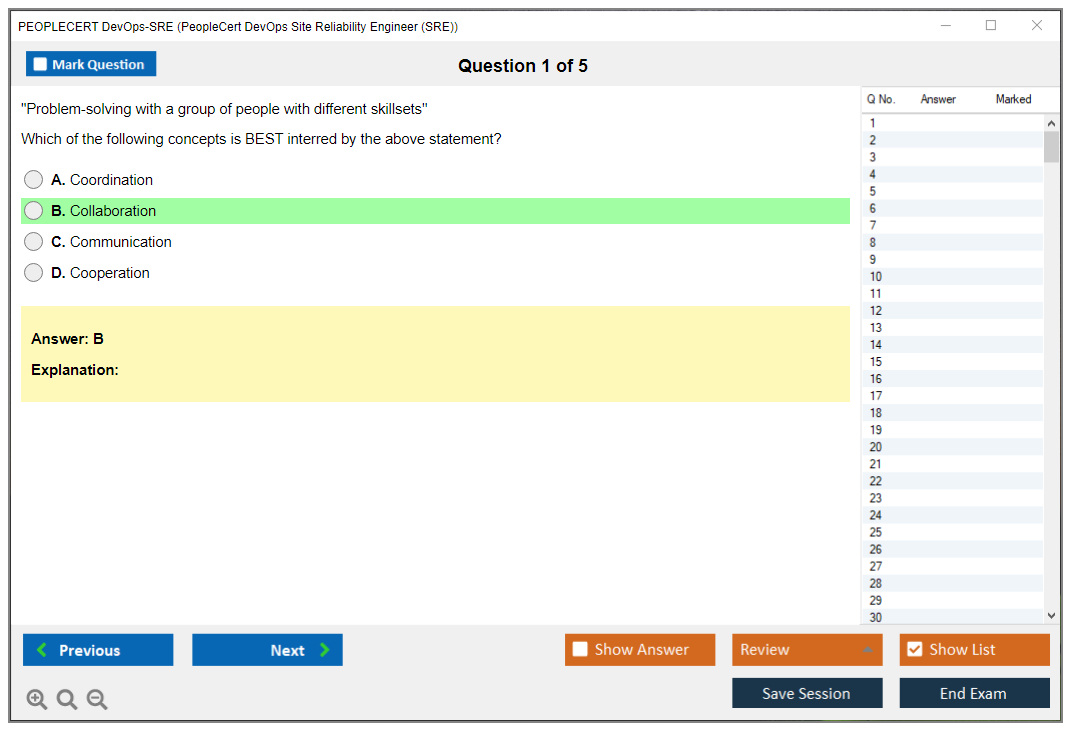
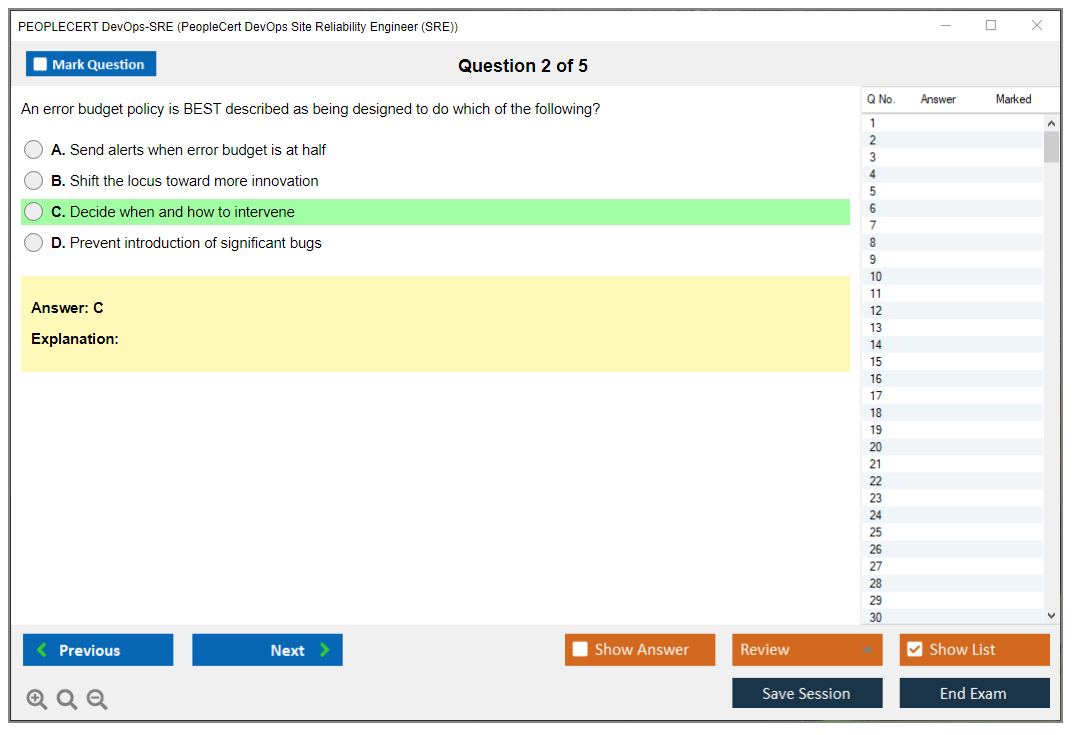
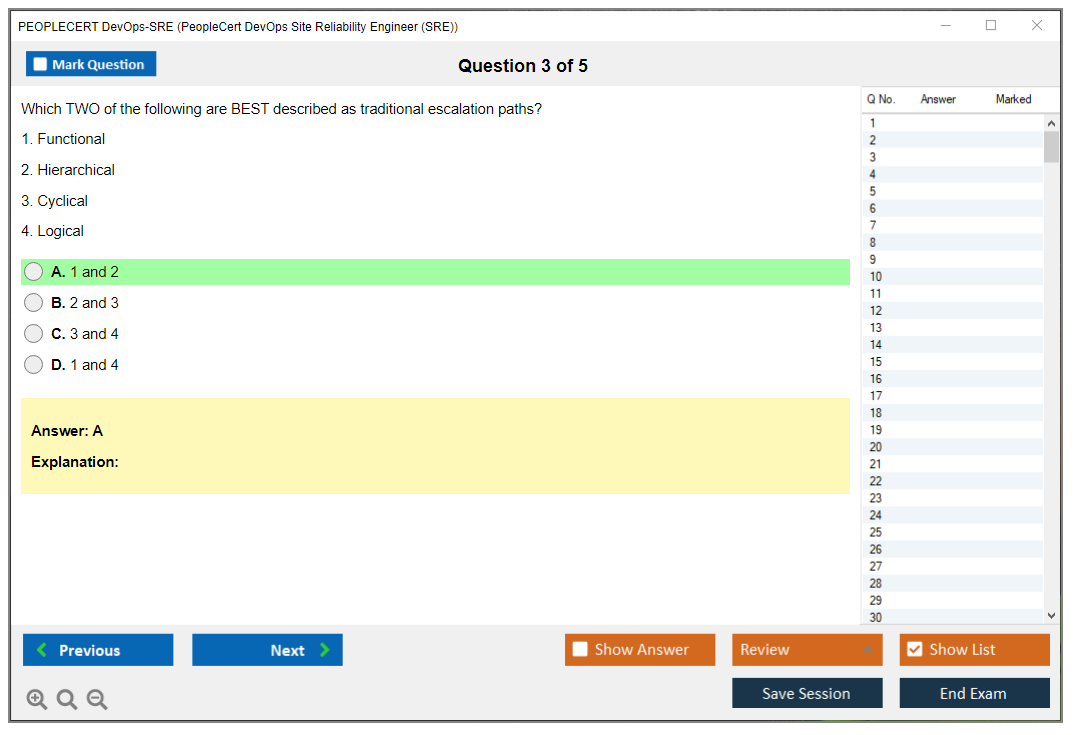
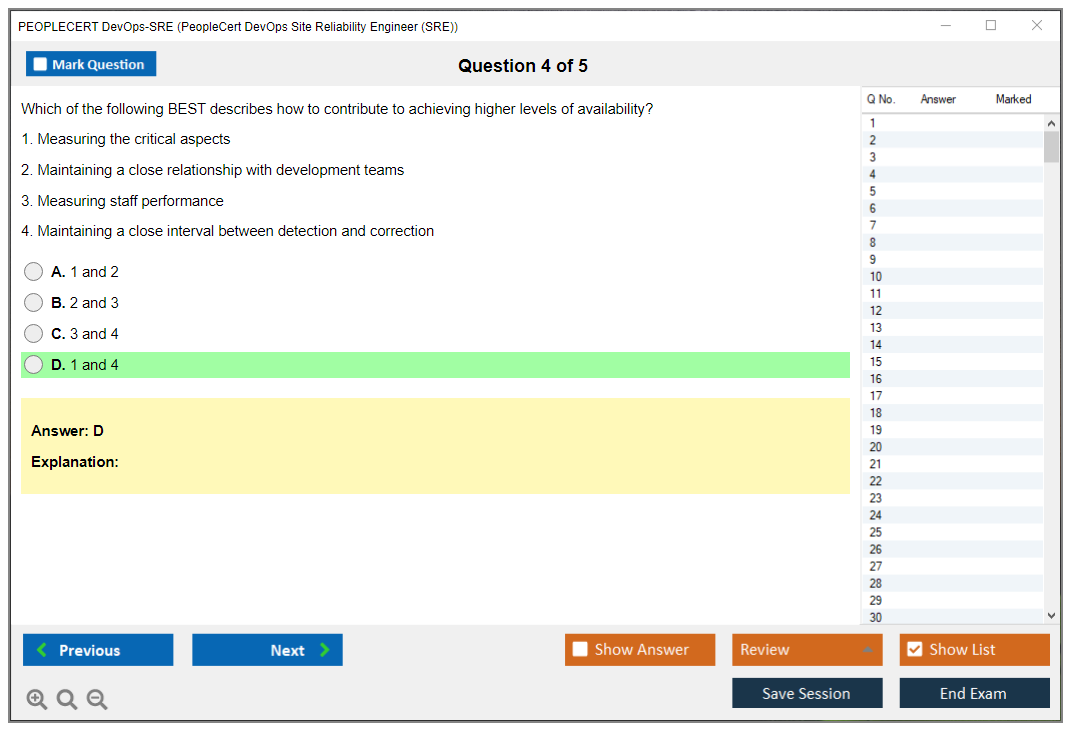
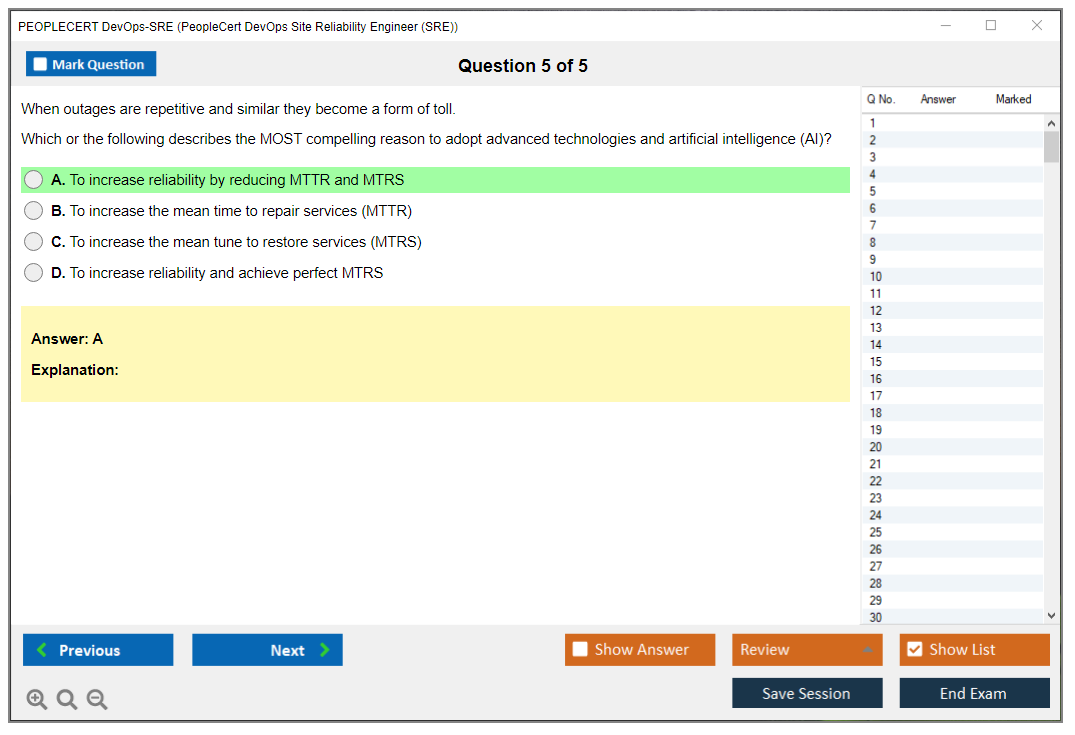
Dumpsarena PEOPLECERT PeopleCert DevOps Site Reliability Engineer (SRE) (DevOps-SRE) Free Practice Exam Simulator Test Engine Exam preparation with its cutting-edge combination of authentic test simulation, dynamic adaptability, and intuitive design. Recognized as the industry-leading practice platform, it empowers candidates to master their certification journey through these standout features.
What is in the Premium File?
Satisfaction Policy – Dumpsarena.co
At DumpsArena.co, your success is our top priority. Our dedicated technical team works tirelessly day and night to deliver high-quality, up-to-date Practice Exam and study resources. We carefully craft our content to ensure it’s accurate, relevant, and aligned with the latest exam guidelines. Your satisfaction matters to us, and we are always working to provide you with the best possible learning experience. If you’re ever unsatisfied with our material, don’t hesitate to reach out—we’re here to support you. With DumpsArena.co, you can study with confidence, backed by a team you can trust.
PEOPLECERT DevOps-SRE Exam FAQs
Introduction of PEOPLECERT DevOps-SRE Exam!
The PEOPLECERT DevOps-SREis exam is a certification exam that tests a candidate's knowledge and skills in the areas of DevOps and Site Reliability Engineering (SRE). The exam covers topics such as DevOps principles, SRE principles, automation, monitoring, and incident management.
What is the Duration of PEOPLECERT DevOps-SRE Exam?
The duration of the PEOPLECERT DevOps-SRE Exam is 2 hours.
What are the Number of Questions Asked in PEOPLECERT DevOps-SRE Exam?
There are a total of 40 questions in the PEOPLECERT DevOps-SRE Exam.
What is the Passing Score for PEOPLECERT DevOps-SRE Exam?
The passing score required in the PEOPLECERT DevOps-SRE exam is 65%.
What is the Competency Level required for PEOPLECERT DevOps-SRE Exam?
The Competency Level for the PEOPLECERT DevOps-SRE exam is Professional.
What is the Question Format of PEOPLECERT DevOps-SRE Exam?
The PEOPLECERT DevOps-SRE Exam consists of multiple-choice questions and scenario-based questions.
How Can You Take PEOPLECERT DevOps-SRE Exam?
PeopleCert DevOps-SRE exams can be taken online or at a testing center. To take the exam online, you must register for the exam on the PeopleCert website and then follow the instructions to complete the exam. To take the exam at a testing center, you must register for the exam on the PeopleCert website and then find the nearest testing center. You will need to bring a valid form of identification and a copy of the exam registration confirmation email to the testing center. At the testing center, you will be given instructions on how to complete the exam.
What Language PEOPLECERT DevOps-SRE Exam is Offered?
The PEOPLECERT DevOps-SRE Exam is offered in English.
What is the Cost of PEOPLECERT DevOps-SRE Exam?
The cost of the PEOPLECERT DevOps-SRE Exam is $250 USD.
What is the Target Audience of PEOPLECERT DevOps-SRE Exam?
The target audience for the PEOPLECERT DevOps-SRE Exam is professionals working in the DevOps field who want to become certified in the SRE (Site Reliability Engineering) area. These professionals may have experience in software engineering, system administration, cloud architecture, or other related disciplines. The exam is designed to assess their knowledge and skills in the areas of DevOps principles, methodologies, and best practices.
What is the Average Salary of PEOPLECERT DevOps-SRE Certified in the Market?
The average salary for a DevOps-SRE with a PEOPLECERT certification varies depending on the individual's experience, location, and other factors. According to PayScale, the average salary for a DevOps-SRE with a PEOPLECERT certification is $95,814 per year.
Who are the Testing Providers of PEOPLECERT DevOps-SRE Exam?
The PEOPLECERT DevOps-SRE exam can be taken at Pearson VUE test centers. Pearson VUE is an authorized testing provider for PEOPLECERT exams.
What is the Recommended Experience for PEOPLECERT DevOps-SRE Exam?
The recommended experience for the PEOPLECERT DevOps-SRE Exam is a minimum of two years of experience in DevOps and SRE, including experience in DevOps tools, automation, scripting, and cloud infrastructure. It is also recommended that candidates have a good understanding of the core principles of DevOps and SRE and have experience in developing, deploying, and managing production systems using DevOps, SRE, and cloud-native technologies.
What are the Prerequisites of PEOPLECERT DevOps-SRE Exam?
The PEOPLECERT DevOps-SRE exam requires a minimum of two years' professional experience in a DevOps-SRE related role. Candidates must also demonstrate knowledge in the following areas: IT systems and networks, operations, DevOps, and SRE best practices.
What is the Expected Retirement Date of PEOPLECERT DevOps-SRE Exam?
The expected retirement date of the PEOPLECERT DevOps-SRE exam is not available on any official website. However, you can contact PEOPLECERT directly for more information. Their website is https://www.peoplecert.org/.
What is the Difficulty Level of PEOPLECERT DevOps-SRE Exam?
The difficulty level of the PEOPLECERT DevOps-SRE exam is moderate.
What is the Roadmap / Track of PEOPLECERT DevOps-SRE Exam?
The PEOPLECERT DevOps-SRE Exam is a certification track that is designed to help IT professionals develop and demonstrate their expertise in DevOps and Site Reliability Engineering (SRE). This certification track consists of two exams: the DevOps Foundation Exam and the Site Reliability Engineering Exam. The DevOps Foundation Exam is designed to assess the knowledge and understanding of the principles and practices of DevOps. The Site Reliability Engineering Exam is designed to assess the knowledge and understanding of the principles and practices of Site Reliability Engineering. The PEOPLECERT DevOps-SRE Exam is a great way for IT professionals to demonstrate their knowledge and skills in this rapidly-evolving field.
What are the Topics PEOPLECERT DevOps-SRE Exam Covers?
The PEOPLECERT DevOps-SRE exam covers the following topics:
1. Continuous Delivery and Deployment: This topic covers the principles and best practices of continuous delivery and deployment, including automated testing, version control, and release management.
2. Infrastructure as Code: This topic covers the principles and best practices of infrastructure as code, including configuration management, automation, and security.
3. Monitoring and Logging: This topic covers the principles and best practices of monitoring and logging, including metrics collection, alerting, and log analysis.
4. Security: This topic covers the principles and best practices of security, including access control, authentication, encryption, and vulnerability management.
5. Troubleshooting and Incident Response: This topic covers the principles and best practices of troubleshooting and incident response, including root cause analysis and post-incident reviews.
6. Service Level Objectives and Agreements: This topic covers the principles and best
What are the Sample Questions of PEOPLECERT DevOps-SRE Exam?
1. What is the purpose of the Incident Management process?
2. What is the purpose of a Service Level Agreement (SLA)?
3. What is the purpose of a Change Management process?
4. What is the difference between a DevOps and a SRE approach?
5. What are the benefits of using a Continuous Delivery model?
6. How can automation be used to improve the reliability of systems?
7. What is the purpose of monitoring and logging systems?
8. How can you ensure your systems are secure and compliant?
9. How can you ensure effective communication between teams in a DevOps environment?
10. What techniques can be used to improve the speed and reliability of deployments?
PeopleCert DevOps-SRE Certification Overview The PeopleCert DevOps-SRE certification actually carries weight in operational trenches. I've seen tons of certs that basically just rubber-stamp your ability to memorize vendor marketing materials (honestly, it's exhausting) but this one targets the real operational challenges keeping SRE teams up at night. The kind of stuff that makes you question your career choices at 3 AM when everything's on fire. It validates your understanding of site reliability engineering principles, practices, and methodologies that've become table stakes at companies caring about uptime and user experience. PeopleCert issues this certification. You probably know them from ITIL credentials, but their DevOps portfolio's quietly become relevant. I mean, they're not some fly-by-night training mill anymore. The PeopleCert DevOps Site Reliability Engineer (SRE) credential sits alongside their other DevOps offerings. The vendor-neutral approach means you're learning... Read More
PeopleCert DevOps-SRE Certification Overview
The PeopleCert DevOps-SRE certification actually carries weight in operational trenches. I've seen tons of certs that basically just rubber-stamp your ability to memorize vendor marketing materials (honestly, it's exhausting) but this one targets the real operational challenges keeping SRE teams up at night. The kind of stuff that makes you question your career choices at 3 AM when everything's on fire. It validates your understanding of site reliability engineering principles, practices, and methodologies that've become table stakes at companies caring about uptime and user experience.
PeopleCert issues this certification. You probably know them from ITIL credentials, but their DevOps portfolio's quietly become relevant. I mean, they're not some fly-by-night training mill anymore. The PeopleCert DevOps Site Reliability Engineer (SRE) credential sits alongside their other DevOps offerings. The vendor-neutral approach means you're learning principles working whether you're running Kubernetes on GCP, managing EC2 fleets on AWS, or dealing with Azure App Services.
What this certification actually proves you know
Real talk here.
The DevOps-SRE exam digs into stuff separating people who just keep servers running from engineers building reliable systems at scale. We're talking reliability engineering metrics like SLI/SLO/SLA frameworks. Understanding the distinction between service level indicators, objectives, and agreements is fundamental, but I've met plenty of "senior" engineers who can't articulate why an SLO matters more than arbitrary uptime targets. Which honestly blows my mind every time.
Error budgets get serious attention. The concept's brilliant when you think about it. Quantifying how much failure your service can tolerate gives you a data-driven way to balance feature velocity against stability instead of just hoping everything works out. Too many organizations just wing it, shipping fast until something breaks catastrophically, then overcorrecting with change freezes that make everyone miserable.
Incident management shows up heavily. Blameless postmortems sound great in theory, but actually conducting them without devolving into finger-pointing requires skill and organizational maturity that's honestly pretty rare. The exam tests whether you grasp principles behind effective incident response, escalation paths, and extracting learnings from failures. Funny thing is, I once sat through a "blameless" postmortem where the VP spent forty minutes explaining why it was technically the intern's fault. Nobody caught the irony.
Automation practices matter here. Observability rounds things out. You need to understand how to reduce toil through intelligent automation, not just scripting everything blindly like some kind of bash-obsessed robot. Observability goes beyond basic monitoring. It's about instrumenting systems so you can ask arbitrary questions about behavior without having predicted every failure mode in advance.
Who needs this thing on their resume
Site reliability engineers, obviously.
But honestly the DevOps-SRE certification makes sense for a wider group. Platform engineers dealing with infrastructure reliability. DevOps engineers wanting to specialize beyond CI/CD pipelines. Systems administrators transitioning from traditional ops roles into modern SRE practices. I've seen infrastructure engineers use this credential to completely pivot their careers in ways that surprised even them.
Classic sysadmin work's evolving. The market wants people thinking like software engineers about operational problems. Operations professionals who've been managing servers for years but need to formalize their understanding of reliability engineering principles find real value here, even if they've been doing half this stuff intuitively already.
The certification sits at an intermediate to advanced level, requiring both theoretical knowledge and practical understanding of how SRE gets done in real environments where nothing ever works exactly like the documentation says. If you're fresh out of a bootcamp with no ops experience, you'll struggle. But if you've been on-call, dealt with incidents, and wrestled with monitoring tools, the material'll resonate.
Why SRE certification matters differently than generic DevOps
Here's the thing about SRE versus pure DevOps certifications. The focus shifts dramatically in ways that actually matter for day-to-day work. Most DevOps certs emphasize development pipeline automation, continuous integration, deployment strategies, and breaking down silos between dev and ops teams. All important stuff, don't get me wrong. But the PeopleCert DevOps Engineer exam covers broader ground.
The DevOps-SRE certification zeroes in specifically on reliability, availability, and operational excellence. You're learning how to apply software engineering approaches to infrastructure and operations problems instead of just throwing scripts at everything and praying. The quantitative approach to reliability through metrics and data-driven decision-making distinguishes SRE from traditional operations work.
Error budgets exemplify this difference perfectly. Instead of treating every outage as unacceptable failure (which just creates fear and cover-ups), you establish acceptable failure rates based on user impact and business requirements. This gives teams breathing room to innovate without constantly panicking. The framework allows rational conversations about risk rather than emotional reactions to downtime.
The certification also emphasizes measurable reliability. While something like ITIL 2011 Foundation focuses on process frameworks and service lifecycle management, SRE digs into the engineering practices making those processes effective at scale.
Real-world practices meet academic rigor
PeopleCert built this certification on established SRE literature and practices pioneered at companies like Google, Netflix, and other reliability engineering innovators who've actually had to solve these problems at massive scale. The Google SRE book series basically created the modern discipline. Those principles have spread across the industry in ways that've fundamentally changed how we think about operations. Startups with fifty users and enterprises with fifty million users both need reliable systems.
Global applicability matters. The principles work regardless of your infrastructure choices. Whether you're managing on-premises data centers, cloud-native architectures, or hybrid environments spanning both, the fundamentals of reliability engineering apply. Service level objectives don't care if you're running on AWS or bare metal.
For organizations adopting SRE practices, the certification provides assurance that professionals understand how to balance feature velocity with system reliability. That tension exists everywhere you look. Product managers want features shipped yesterday, while operations teams get paged when things break. SRE offers a framework for working through those competing pressures.
Career implications and market demand
SRE roles command premium salaries. Plenty of people can configure servers or write deployment scripts, but fewer understand how to build reliable distributed systems that scale gracefully under load and fail gracefully when components break. That's where the real value lives.
The DevOps-SRE certification helps validate expertise in competitive job markets where everyone claims to "do DevOps" without really understanding what that means beyond running some Jenkins jobs. Having formal recognition of your SRE knowledge distinguishes you from candidates who just list buzzwords on their resume hoping nobody actually tests them.
It also provides a structured learning path if you're transitioning into reliability engineering. The DevOps-SRE exam objectives cover capacity planning, performance optimization, resilience engineering, and the organizational culture changes required for successful SRE adoption. These aren't skills you pick up overnight no matter what anyone tells you. Having a framework for learning them systematically speeds up your growth.
The certification complements other credentials. If you're pursuing the DevOps Leadership certification or exploring adjacent areas like DevSecOps, the SRE credential adds depth to your reliability engineering expertise specifically.
What makes this certification stick
Honestly, the value comes from how closely it fits with actual SRE work you'll be doing when the rubber meets the road. The domains covered (incident response, observability, automation, error budgets, SLIs and SLOs) reflect what you'll actually deal with in SRE roles. It's not academic fluff disconnected from reality.
Real value lives here.
The emphasis on continuous improvement and organizational transformation also matters because adopting SRE practices requires cultural change, not just technical implementation that you can slap on like a band-aid. Teams need to embrace blameless postmortems, resist the urge to hide failures (which goes against every instinct people have), and use incidents as learning opportunities instead of blame sessions. The certification validates you understand these organizational dynamics, not just the technical mechanics.
For individuals, it's career insurance in a market where reliability engineering skills keep growing more valuable as systems get more complex and distributed. For employers, it's a screening tool indicating candidates have formal grounding in SRE principles rather than just cobbled-together experience. Both sides benefit when certifications actually test relevant knowledge instead of trivia.
The vendor-neutral positioning means the certification ages better than cloud-specific credentials becoming outdated as platforms shift and change. That durability makes the investment worthwhile. While you'll still need hands-on experience with specific tools and technologies, the underlying principles of reliability engineering remain constant.
DevOps-SRE Exam Format, Structure, and Logistics
PeopleCert DevOps-SRE certification is one of those credentials that looks simple on the surface, then you read the fine print and suddenly realize the exam logistics matter almost as much as the site reliability engineering principles you're actually being tested on.
Here's the thing. People skip this part.
Big mistake.
What the certification actually validates
PeopleCert DevOps Site Reliability Engineer (SRE) is aimed at proving you understand reliability as a practice, not just "I can restart pods" energy. Expect a mix of conceptual questions alongside scenario prompts that push you toward SRE thinking like risk tradeoffs, reliability engineering metrics (SLI/SLO/SLA), plus how error budgets and service availability change day-to-day decisions in ways that aren't always obvious until you're the one holding the pager at 3 AM.
Theory? Check. Real-world judgment calls? Also check.
A little "what would you do next" pressure thrown in for flavor.
Who should take it (and who probably shouldn't)
This is for DevOps folks, SREs, ops engineers, platform engineers, and even tech leads who keep getting dragged into incident management and postmortems but want a cleaner vocabulary plus a credential that HR can actually recognize.
Brand-new IT people should pause, though. If you've never been on-call, never debugged a production incident, and don't know why "just add retries" can make things worse, the DevOps-SRE exam can feel weirdly abstract and annoyingly specific at the same time. Like someone's testing you on inside jokes you weren't there for.
How the DevOps-SRE exam is delivered
The DevOps-SRE exam is delivered through PeopleCert's testing platform, and you typically get two paths: online proctored or a test center.
Online proctoring? Convenience play. Test from home or the office, pick a slot that fits your calendar, skip travel entirely. But you're signing up for strict exam security measures like continuous monitoring, screen recording, environment scans, and yes, they're definitely paying attention to what's on your desk and what your eyes are doing.
Test centers are the low-drama option, honestly. You show up, you sit down, the environment's controlled, and you don't get derailed by surprise Wi-Fi issues or a laptop that decides today is the day it needs a firmware update.
Question format and what it feels like
Question format? Multiple-choice. But don't assume that means it's easy. PeopleCert tends to test both definitions and applied thinking, so you'll see conceptual checks plus scenario-based application like "service is breaching SLO, error budget is burning fast, what's the best next action".
Some questions are obvious.
Others are "two answers seem right, pick the one that matches the syllabus worldview."
Number of questions, time limit, and pacing
Typically you're looking at 40 questions.
Exam duration? 60 minutes. One hour, and that's not a lot. The time pressure is real because scenario questions take longer to read, you'll waste minutes if you overthink terminology instead of deciding and moving on, and the clock doesn't care about your process.
Do the math here. That's about 90 seconds per question, including review time.
You need a plan, not vibes.
Closed book means closed book
Open book policy is closed book. No reference materials allowed whatsoever.
No printed notes. No second monitor "just for my calendar". No quick tab to check the difference between SLIs and SLOs, which trips people up more than it should. If you're used to open-book certs, this forces you to actually know the DevOps-SRE exam objectives, not just recognize them when Google suggests the answer.
Passing score and scoring methodology
DevOps-SRE passing score? Typically 65%, or 26 out of 40 correct. PeopleCert may adjust based on difficulty calibration, but don't build your strategy around "maybe they'll curve it".
Assume you need 26.
Scoring methodology is straightforward enough: each question carries equal weight, there's no partial credit for multiple-choice answers, and also, no negative marking. Wrong answers don't deduct points, which means leaving blanks is the only truly bad move you can make.
Answer everything. Even your best guess beats silence.
Review tools, submission, and immediate results
Most candidates get review functionality, meaning you can flag questions for review and come back before final submission. Useful, but don't abuse it by flagging every question where you're slightly uncomfortable versus truly uncertain.
Immediate results? Typically provided as pass/fail right after you finish, through the testing platform. Score reporting is often limited to overall status, and you may not get a detailed breakdown by domain. If you fail, you'll need to self-diagnose based on what felt shaky during the actual exam.
Annoying, I know.
Also normal.
Cost and why the price varies so much
PeopleCert SRE certification cost typically ranges from $250 to $350 USD, depending on region, delivery method, and whether you bought it alone or bundled with training.
Pricing variations are a real thing here. Country, currency exchange rates, local taxes, partner pricing, and "package deals" can all change what you pay, not always in ways that feel logical or fair. Buying directly versus going through an authorized training partner can swing the total. Training bundles include exam vouchers that may or may not actually save you money depending on how the math works out.
Actually, speaking of cost variations, I once watched someone complain for twenty minutes about paying different prices in two countries for the same cert. Like, yes, that's frustrating, but also economics exist? Regional pricing models are their own mess.
Retakes and the part nobody budgets for
Retake policy: if you fail, you can retake after a waiting period, and you'll pay additional fees for each attempt.
Look, it happens. But plan for it financially if you're not 100% confident. Retakes are how a $300 exam quietly becomes a $600 exam, then suddenly you're justifying the expense to your manager or your spouse and neither conversation is fun.
Scheduling flexibility and what to do early
Online proctored exams usually have strong exam scheduling flexibility, meaning you can book at your convenience. But you still want to schedule in advance because popular time slots fill up, and rescheduling late can be a pain depending on the terms attached to your voucher.
Put it on the calendar.
Treat it like a real deadline.
Technical requirements for online proctoring
If you go remote, you'll need a stable internet connection, webcam, microphone, and a secure testing environment that meets proctoring rules.
Quiet room. Clear desk. No random second devices lying around. Also, do the system check early, because nothing is worse than discovering your webcam drivers are broken 15 minutes before check-in, while your stress level is already doing incident-response cosplay.
Identification and check-in
Identification requirements are strict: government-issued photo ID is required for identity verification before you can access the exam.
Match your registration name to your ID exactly. This is a dumb way to lose a test slot. People still do it.
Language availability and regional differences
Language availability is generally English, with the possibility of additional languages depending on regional demand and how much PeopleCert thinks it's worth supporting. If English isn't your first language, confirm availability before you pay, and also check whether accommodations exist for extra time in your region.
Accessibility accommodations
Accessibility accommodations are available for candidates with disabilities or special requirements, but you usually need to request them in advance through the official process. Paperwork and timelines. Don't wait until the week of the exam and expect magic to happen.
Plan ahead here.
Seriously.
What "objectives coverage" really means
Question distribution is typically proportional across DevOps-SRE exam objectives based on the official syllabus weightings. Yes, you might personally love observability, but if the syllabus puts meaningful weight on incident management and postmortems or reducing toil through automation, you're going to see it whether you want to or not.
This is where DevOps-SRE study materials matter, I mean the real ones, not the random blog post that goes viral because someone posted it on Reddit at the right time.
The syllabus.
Practical prep advice (because format drives strategy)
DevOps-SRE practice test work is useful when it matches the exam feel: mixed conceptual and scenario questions, rationales for answers, and coverage that lines up with objectives instead of random trivia. A practice test that only quizzes definitions won't prepare you for "error budget is gone, what now" questions that require you to actually think through tradeoffs.
My opinion? Use practice exams for timing training first, knowledge checks second. If you can't comfortably finish 40 questions in 60 minutes while staying accurate, you're not ready, even if you "know the content" and can recite SLI definitions in your sleep.
Renewal and how long the cert lasts
Certification validity period is typically three years from passing, and then you'll need renewal or recertification depending on what PeopleCert's policies look like at that point. Their rules can evolve, so check the current requirements in your candidate portal, especially if your employer cares about active status for compliance or partner programs.
Track your expiration date.
Future-you will forget.
Quick answers to the questions everyone asks
How much does the PeopleCert DevOps-SRE exam cost? Usually $250-$350 USD, but region and bundles change it in ways that aren't always transparent.
What is the passing score for PeopleCert DevOps-SRE? Typically 65%, so about 26/40, and there's no curve you can count on.
How hard is the PeopleCert DevOps-SRE certification? Not impossible, but the scenario questions reward people who understand SRE vs DevOps certification differences and can apply concepts under time pressure without panicking.
What study materials and practice tests are best for DevOps-SRE? Start with the official syllabus, then add practice tests with explanations that actually teach you why answers are right or wrong. Fill gaps with hands-on drills around monitoring, on-call, and post-incident reviews.
Does PeopleCert DevOps-SRE require renewal? Typically yes, around a three-year cycle, with renewal or recertification steps defined by PeopleCert at the time you hold the credential. Check current requirements instead of assuming.
DevOps-SRE Exam Objectives and Knowledge Domains
The PeopleCert DevOps Site Reliability Engineer (SRE) certification tests you across eight major knowledge domains that cover everything from basic SRE philosophy to hands-on incident management and capacity planning. Look, this isn't one of those exams where you can memorize a bunch of definitions and call it a day. You've gotta understand how these concepts actually connect and how you'd apply them when your production systems are literally melting down at 2 AM on a Saturday.
What the exam actually measures
The DevOps-SRE exam objectives break down into domains that progressively build on each other. Honestly makes sense once you see the bigger picture. You start with foundational concepts about what SRE even is (and what it isn't), then move into the measurement frameworks (SLIs, SLOs, SLAs), then into how you use those measurements to manage risk through error budgets. Finally you hit the operational practices that make it all work: monitoring, incident response, automation, capacity planning.
The first domain covers SRE foundations and principles. Trips up a lot of people. They think they already know this stuff because they've been doing ops work for years, but site reliability engineering has specific definitions that differ from traditional operations in fundamental ways. The exam wants you to understand that SRE is about applying software engineering practices to infrastructure problems. You're not just keeping the lights on. You're building systems that scale and heal themselves without someone babysitting them at 3 AM.
The relationship between SRE and DevOps? It's complementary, not competitive. SRE provides a concrete implementation framework for the broader DevOps principles, which is something I wish more organizations understood before they tried to "do SRE" without actually changing how they work or allocate resources. I've seen companies slap the SRE label on their existing ops team and wonder why nothing improved. That's like renaming your sedan a sports car and expecting it to go faster.
One concept that the certification really hammers on is embracing risk. Not gonna lie, this is counterintuitive for folks coming from traditional IT backgrounds where the goal was always 100% uptime, no exceptions, no excuses. The SRE philosophy recognizes that perfect reliability is impossible and (here's the kicker) actually undesirable because it prevents innovation. You need enough unreliability to move fast and deploy new features. Systems thinking's another core concept. You can't just look at individual components in isolation. Gotta understand the complex interactions between services, infrastructure, and user behavior.
Measuring what matters to users
Domain 2 dives deep into Service Level Indicators, Objectives, and Agreements. Quantitative backbone of SRE. Service Level Indicators are the carefully chosen metrics that actually represent user experience. Not just "is the server responding to pings" but "can users complete their critical workflows within acceptable time frames while having a decent experience?" The exam'll test whether you can identify appropriate SLIs for different types of services, which honestly requires more judgment than people expect.
For a web application, that might be latency for the 95th percentile of requests (not the average, because averages hide problems). Error rate as a percentage of all requests. Availability measured by successful versus failed requests.
Service Level Objectives? They're the target values for those SLIs. Setting good SLOs requires balancing what users need, what your systems can realistically deliver, and what it costs to achieve different reliability levels. There's real money involved in every nine you add to your uptime percentage. The certification expects you to understand this trade-off space. Then Service Level Agreements add contractual teeth with actual legal implications. These are external commitments with consequences for non-compliance, and they're typically less strict than your internal SLOs to give you buffer room for unexpected problems.
Error budgets as negotiation tools
Domain 3 covers error budgets and risk management, which is where SRE gets really practical and also kinda brilliant. An error budget is the amount of unreliability you can afford within your SLO targets. If your SLO's 99.9% availability, your error budget is 0.1% downtime per measurement period. Simple math, right?
But the exam tests your understanding of how to use this as an objective mechanism for making decisions about feature velocity versus reliability work. This is where teams usually fight. When you've burned through your error budget, you implement your error budget policy. Maybe that means a feature freeze until reliability improves. Maybe it means redirecting engineering resources to stability work. Whatever you've agreed on ahead of time when everyone was calm and rational.
The beauty of this approach? It removes subjective arguments between development and operations teams because the data tells you what to do, no opinions needed. The certification wants you to understand how to track error budget consumption over time and how to align error budget policies with organizational risk tolerance, which varies wildly. Some companies can afford to burn their error budget quickly and operate close to their SLO threshold. Others need more conservative approaches because their customers expect near-perfect reliability.
Building visibility into complex systems
Domain 4 addresses monitoring, observability, and alerting. Foundational operational capabilities. The exam distinguishes between monitoring and observability. Monitoring's about tracking known failure modes with predefined metrics and dashboards. Observability enables you to investigate unknown problems by asking arbitrary questions of your system after something weird happens. You need both, honestly, because you can't predict every failure mode.
The three pillars of observability are metrics, logs, and traces. Metrics give you aggregated time-series data about system behavior over minutes, hours, days. Logs capture discrete events with context. What happened, when, why it mattered. Distributed tracing follows individual requests as they flow through microservices architectures, which is absolutely critical when you're trying to figure out why the checkout process is slow but only for users in certain regions during specific times of day. Like what even is that?
The certification expects you to know when to use each pillar and how they complement each other rather than compete for budget.
Alert design's its own skill. Good alerts are actionable. They indicate a problem that requires human intervention right now. They provide enough context for the on-call engineer to start troubleshooting without forty minutes of investigation just to understand what's broken. They don't fire unless something actually needs fixing immediately. Bad alerts create alert fatigue where people start ignoring notifications because most of them are false positives or things that don't actually require immediate action, which is how real incidents get missed.
If you're interested in broader DevOps engineering practices that complement SRE work, the PeopleCert DevOps Engineer Exam covers related but distinct territory.
Responding when things break
Domain 5 covers incident management. The exam tests your knowledge of structured incident response processes. How to detect incidents through automated monitoring or user reports. How to classify them by severity based on actual user impact rather than how scary the graphs look. How to coordinate response through defined roles like incident commander and communications lead.
Escalation procedures matter. A lot. You need clear pathways for bringing in additional expertise or management when an incident requires broader response or when your initial troubleshooting isn't working and you need fresh eyes. Communication during incidents is critical. Stakeholders need updates with appropriate frequency and detail, and users deserve transparent information through status pages about what's broken and when it'll be fixed, even if the answer is "we don't know yet but we're working on it."
Learning from failures systematically
Domain 6 addresses post-incident reviews and continuous improvement, which is where organizations actually get better or just keep having the same incidents repeatedly. Blameless postmortem culture's fundamental to SRE. You focus on systems and processes rather than blaming individuals because blame discourages the honest analysis you need to actually fix underlying problems instead of just patching symptoms.
The exam covers techniques for reconstructing incident timelines, identifying root causes through methods like the five whys (though that technique has limitations too), recognizing contributing factors, and generating actionable remediation items with owners and deadlines.
Writing good postmortems? Harder than most people think. It requires discipline to document what actually happened rather than what you think happened or what makes you look good. You gotta distinguish between root causes and symptoms that just looked scary. Generate concrete action items rather than vague commitments to "be more careful next time" or "improve monitoring."
The certification tests whether you understand these distinctions. For those also interested in security integration with reliability practices, the PeopleCert DevSecOps Exam explores that intersection.
Eliminating manual operational work
Domain 7 focuses on automation and toil reduction. Toil's manual, repetitive, automatable, tactical work that lacks enduring value. Basically anything that doesn't scale with your service growth and just consumes more human time as you grow. The exam expects you to know how to identify toil (which can be subtle), measure it typically as percentage of team time, and systematically eliminate it through automation investments that pay off over time.
CI/CD pipeline integration reduces toil around releases and deployments. Infrastructure as Code eliminates manual configuration work and those "wait, which settings did we use last time" conversations. Self-service platforms let developers perform common tasks without filing tickets and waiting for operators to get around to them. Improves velocity and reduces operational burden simultaneously.
Planning for growth and performance
Domain 8 covers capacity planning and performance engineering. Real stuff. You need to forecast resource needs based on growth trends and business projections. Validate capacity through load testing before your users become your load testers (never fun). Establish performance budgets that define acceptable targets for response times, resource consumption, and cost efficiency.
The exam tests your knowledge of scalability patterns. When to scale horizontally versus vertically. How to architect for growth without over-provisioning and wasting money. How to optimize resource utilization to control costs while meeting performance requirements.
If you're preparing for the DevOps-SRE exam objectives, working through scenario-based DevOps-SRE Practice Exam Questions helps you understand how these concepts apply in realistic situations where multiple factors compete. The certification doesn't just test definitions. Tests judgment about which approach to use when and why the alternatives wouldn't work as well. That's what makes it valuable and also what makes it challenging. You can't just memorize the material. You've gotta internalize the principles and practice applying them to different scenarios until the decision-making becomes intuitive.
Prerequisites and Recommended Background for DevOps-SRE
What "prerequisites" really means here
Okay, formal stuff first. No mandatory certifications or credentials required to register for the PeopleCert DevOps-SRE certification exam. That's official, and honestly? I like it. Doesn't gatekeep folks who learned on the job, came from dev, or got thrown into ops during a production fire at 3 a.m.
No required course. No "must hold X first." Just you versus the DevOps-SRE exam content.
But here's the thing: "no prerequisites" doesn't mean you can wing it without prep. The exam objectives assume you've encountered real systems, made actual tradeoffs, watched things fail spectacularly. Haven't seen that yet? You can still pass, sure, but you'll be cramming definitions instead of understanding why SRE teams have heated debates about error budgets and why "let's just add more alerts" usually makes everything worse, not better.
Required vs recommended background (my blunt take)
PeopleCert won't force a checklist on you, but SRE as a job? Totally does. Look, SRE's basically ops with a software engineering brain and a product mindset bolted on, and the certification reflects that reality. So I'd approach the DevOps-SRE prerequisites like this:
You've gotta know the vocabulary. You should know the pain. You need reps, actual experience.
Coming in cold? You'll burn tons of time translating basic concepts before you even touch the good stuff like reliability engineering metrics (SLI/SLO/SLA), incident management and postmortems, and how error budgets and service availability actually change team behavior when implemented properly.
Core IT operations and SDLC knowledge
A solid foundation in IT operations, systems administration, and the software development lifecycle makes everything else snap into place. Don't need to be a senior sysadmin or anything, but you should grasp what "production" really means, how releases happen, why change windows exist, and why rollback plans matter when that pager screams at 2 a.m. and your heart drops.
Also, basic SDLC stuff matters. Requirements, build, test, release, maintain, the whole cycle. If you've only lived in "write code, ship feature" land, SRE concepts can feel like annoying speed bumps. They're not, though. They're guardrails, and the exam keeps circling back to risk, reliability, and systems thinking from about ten different angles.
DevOps fundamentals and culture (yes, culture shows up)
You should be comfortable with DevOps principles: shared ownership, feedback loops, automation everywhere, and the idea that dev and ops aren't rival tribes fighting over territory. CI/CD's part of this, but the cultural side matters too because SRE's often the group that has to say, "Yeah, we can ship this, but here's what it'll cost us in reliability."
This is where folks get confused on SRE vs DevOps certification comparisons. DevOps is the broader practice, philosophy plus tools. SRE's a particular approach to running reliable services, usually with more explicit math, more explicit tradeoffs, and less hand-waving about "best practices." The PeopleCert DevOps Site Reliability Engineer (SRE) track expects you to actually think in those tradeoffs, not just recite tooling names like magic spells.
Linux/Unix command line comfort
Can't live in a terminal for an hour? Fix that before exam day. Linux/Unix experience matters because infrastructure management still runs through shells, processes, permissions, filesystems, systemd, and logs that absolutely do not care about your feelings or your GUI preferences.
Know how to inspect systems. Know where logs actually live. Understand what a process is.
You don't need to be a kernel wizard, honestly. But you should grasp the operating system concepts behind performance symptoms, resource exhaustion, and those delightful "why is literally everything slow right now" incidents that make you question your career choices.
Networking fundamentals for distributed systems
SRE work is distributed systems work, even when you didn't explicitly sign up for that complexity. So you'll want networking fundamentals down: TCP/IP basics, DNS behavior (oh, DNS..), load balancing concepts, TLS termination at a high level, and practical troubleshooting skills that go beyond "have you tried rebooting it?"
Here's what people underestimate: DNS failures. They show up in ways that look exactly like app bugs, and the exam's focus on reliability and observability makes DNS a recurring suspect in scenarios. If you can explain what an A record is, what TTL implies, and why caching can create these super confusing partial outages where some users are fine and others aren't, you're in good shape.
By the way, I once spent six hours debugging what turned out to be a stale DNS cache on exactly three machines in a cluster. Three. The other 47 were perfect. That kind of randomness teaches you more about distributed systems than any book ever will.
Scripting or programming ability (automation isn't optional)
Don't have to be a full-time software engineer, but you should have working knowledge of at least one language like Python, Go, Bash, or Ruby. SRE's allergic to manual repetition, the thing is, toil is the enemy, and automation's the antidote everyone keeps talking about for good reason.
Pick one language. Get practical: parse logs, call an API, write a health-check script, automate routine remediation, generate config files, or build a small tool that saves you ten minutes every day. The exam themes around reducing toil and improving reliability make way more sense when you've personally felt the soul-crushing drag of doing the same manual task 40 times in a row.
Cloud exposure and cloud-native thinking
Experience with at least one major cloud provider (AWS, Azure, or GCP) is strongly recommended. Not because the certification is specifically "a cloud exam," but because modern reliability work gets shaped by cloud primitives: managed databases, autoscaling, regions and zones, IAM policies, and that whole shared responsibility model that shifts what you're accountable for.
And cloud-native architectures change failure modes in weird ways. A VM dying is one thing, annoying but manageable. A misconfigured autoscaler plus a thundering herd plus a noisy neighbor all hitting at once? That's a different movie entirely, and if you've seen that particular disaster film at least once, the exam scenarios feel way more natural and less abstract.
Containers and orchestration (Docker and Kubernetes)
Containers are central to SRE work now, and Kubernetes is often where reliability dreams go to fight reality in confusing ways. You should know what a container actually is, what an image is, basic Docker workflows, and why orchestration exists at all instead of just running stuff on VMs like we used to.
Kubernetes knowledge doesn't need to be expert-level. But you should understand the basics: deployments, services, ingresses, config maps and secrets, and the idea that the scheduler's making choices constantly that directly affect availability. Never debugged a crash loop or chased a "works perfectly on my laptop" container issue? Do a small lab. It's worth it.
Git and version control for everything
Git proficiency is non-negotiable in actual practice. Infrastructure as code, configuration management, runbooks, dashboards, alert rules, CI pipelines, and even postmortems often live in repos nowadays. You should be comfortable branching, reviewing, merging, and resolving conflicts without panicking or accidentally force-pushing to main.
One rule: commit messages matter. Another: reviews save outages.
Monitoring and observability experience (not just dashboards)
Hands-on time with monitoring tools like Prometheus, Grafana, Datadog, or similar platforms helps tremendously. The exam leans hard into observability and monitoring: metrics, logs, traces, and how you actually use them to detect and diagnose issues before customers start complaining on Twitter.
Spend real time understanding what makes a good alert, not "CPU over 80%" nonsense. More like "user-facing latency SLO burn rate is high and trending worse" because that ties directly into reliability engineering metrics (SLI/SLO/SLA) and error budgets and service availability in ways that matter. That's SRE thinking, and it's a really different mental model than classic NOC-style monitoring where you just watch dashboards turn red.
Incident response, on-call, and postmortems
If you've participated in incident response, even outside an SRE title, you're already ahead. On-call rotations teach you what actually matters under pressure: clear escalation paths, fast triage, communication that doesn't waste time, and knowing when to stop digging and just roll back immediately.
Incidents create context. Context beats flashcards every time.
The exam topics around incident management and postmortems will feel familiar if you've done blameless reviews, written incident timelines, identified contributing factors (not just "root cause" singular), and tracked action items that actually reduce repeat failures instead of collecting dust in a Jira board somewhere.
ITIL/ITSM awareness and business context
Not saying you need to be an ITIL purist or anything. But awareness of IT service management helps you place SRE inside a bigger organization that still cares about change management processes, incident categories, SLAs with customers, and impact reporting that executives actually read.
Business context awareness matters too, honestly, reliability's a product feature, but it's also a budget decision. Downtime costs money, absolutely, but so does over-engineering everything to five nines when your users would be fine with three. The exam's mindset expects you to weigh risk and value realistically, not just chant "five nines" like it's a personality trait.
Experience level and alternative paths
Practical guideline here: 2 to 5 years in operations, DevOps, or related roles is a sweet spot for full comprehension. You've seen enough incidents to have opinions, survived enough on-call weeks to know what matters, but you're still close enough to hands-on work that the details aren't fuzzy memories.
No ops background? Still totally possible. If you're a strong developer, you can succeed with focused SRE study, particularly if you build labs around deployment, monitoring, and failure testing. But you'll need to intentionally learn systems and networking, because SRE punishes gaps there harder than you'd expect.
Recommended reading and hands-on practice before the exam
Read Google's "Site Reliability Engineering" book if you haven't already. It frames site reliability engineering principles in ways that match how many exams and interviews talk about SRE. Pair it with real practice: define an SLI for something you care about, write an SLO, create an error budget policy, and build alerting that points to user pain instead of machine trivia.
Lab time matters immensely. Set up a tiny service, put it behind a load balancer, add dashboards, break it on purpose, and practice writing a mini postmortem. Also, get familiar with DevOps-SRE study materials and the DevOps-SRE exam objectives so you're not guessing what's actually "in scope" versus what's just interesting but irrelevant.
If you want question-style prep, a decent DevOps-SRE practice test can help you spot weak areas fast. I've used packs like the DevOps-SRE Practice Exam Questions Pack when I wanted repetition and timing practice, and it's also a straightforward way to sanity-check whether you actually understand the terms or you're just recognizing them from seeing them before. Price-wise, the DevOps-SRE Practice Exam Questions Pack is $36.99, which is usually cheaper than losing a week to unfocused studying and then failing anyway.
Quick notes on common admin questions (cost, score, renewal)
People always ask about PeopleCert SRE certification cost and the DevOps-SRE passing score specifics. Those details can vary by region, exam bundle options, and voucher situations, so I'm not going to make up a number here and have it be wrong next month. Check PeopleCert's current listing or your training provider for the exact PeopleCert DevOps-SRE exam cost, and confirm how scoring works for the current version of the exam if you care about the precise DevOps-SRE passing score target.
Renewal details? Same deal. Recertification rules change.
Verify the current policy on PeopleCert's site, then plan your learning like you'll keep the skills anyway, because SRE tools and practices move fast and "I passed once" doesn't keep services up when the space shifts.
One last thing: if you're the self-study type, you'll do fine. Maturity for self-study is a real prerequisite even when it's not written down anywhere, because SRE learning is a lot of docs, experiments, and "wait, why did that break" moments, plus some focused drilling with something like the DevOps-SRE Practice Exam Questions Pack if you want structured repetition that mimics exam conditions.
Exam Difficulty Assessment: How Hard Is PeopleCert DevOps-SRE?
Okay, real talk here. Not gonna lie.
The PeopleCert DevOps-SRE certification sits firmly in that intermediate-to-advanced sweet spot that can trip up even experienced professionals if they're not careful. I mean, I've watched people with years of operations experience struggle because they didn't grasp the software engineering mindset, and I've seen developers who can code circles around me stumble on incident management scenarios. It's a weird exam. In the best way.
What makes this one different from your typical cert
Here's the thing. The DevOps-SRE exam doesn't just test whether you memorized definitions from a study guide. It wants to know if you can actually think like an SRE, which honestly is a completely different ballgame. You'll get 60 minutes to answer 40 questions, which sounds generous until you realize many of these aren't simple recall questions but rather scenario-based situations where you need to analyze what's happening, apply SRE principles, and pick the best answer. Not just any correct answer, mind you, but the one that aligns most closely with site reliability engineering philosophy. That distinction? It trips people up constantly.
I mean, 1.5 minutes per question seems reasonable on paper. But when you're reading a paragraph about an incident escalation gone wrong and trying to decide between four options that all sound plausible, time evaporates fast. Honestly, it's wild how quickly it happens. The exam is tool-agnostic too, which actually makes it harder in some ways because you can't fall back on "well, in Kubernetes you'd just.." thinking. You need underlying principles. Ones that work across any platform.
The breadth problem nobody talks about enough
This certification covers ridiculous ground.
You're expected to know technical monitoring concepts, metrics and observability, error budget policies, incident response procedures, blameless postmortem culture, capacity planning, automation strategies, and organizational dynamics. That's not a narrow technical certification. That's basically asking you to understand how modern reliability engineering works from the server room to the boardroom, and I've gotta say, it's a lot.
Some people come from traditional IT operations backgrounds. They know incident management cold but have never written a line of code or thought about toil reduction through automation. Others are software engineers who've never been on-call or dealt with a 3am production outage (lucky them, honestly). The exam doesn't care about your gaps. It tests everything.
The cultural stuff adds complexity that catches technical folks off guard, because understanding why blameless postmortems matter isn't the same as knowing what makes a postmortem actually blameless in practice. You need to grasp the human and process elements alongside the technical ones. My old manager used to say the tech part was easy compared to getting teams to actually stop pointing fingers after an outage, which sounds cynical but turned out to be completely true.
Where candidates actually struggle
Honestly? The biggest pain point I see is distinguishing between SLI, SLO, and SLA. Everyone thinks they understand these until they hit exam questions that require precision, then it all falls apart. An SLI is what you measure, an SLO is your target for that measurement, and an SLA is your promise to customers with consequences. Simple enough, right? But then you get a scenario asking which metric to use as an SLI for a specific service, and suddenly three options look reasonable, and you're sitting there second-guessing everything you thought you knew.
Error budget policies? Another killer.
The concept makes sense when you read about it, but applying it to realistic scenarios requires judgment that you can't really fake or memorize your way through. If you've burned through 80% of your error budget in the first month of the quarter, what's the appropriate response? The exam wants you to think through the implications, not just regurgitate the definition you highlighted in your study guide.
Time pressure compounds these challenges. You can't afford to overthink. I've talked to people who failed not because they didn't know the material but because they spent four minutes agonizing over two questions and then rushed through the last ten. The thing is, that's a strategy problem, not a knowledge problem.
How this compares to other certs in the space
The DevOps-SRE sits in an interesting middle ground compared to other certifications, honestly occupying a space that's neither too broad nor too narrow. It's more focused than something like the broader PeopleCert DevOps Engineer credential, which covers the full DevOps lifecycle. But it's less technically deep than platform-specific certifications like AWS or Google Cloud's SRE offerings. You won't need to know the exact API calls for a specific cloud provider, but you will need to understand reliability concepts at a level where you could implement them anywhere.
Compared to ITIL certifications, this exam requires more technical depth and less process memorization. ITIL wants you to know the framework. DevOps-SRE wants you to apply engineering thinking to reliability problems. Different muscles entirely.
Who finds this easier versus harder
Your background massively influences difficulty perception, like, night-and-day differences depending on where you're coming from. Operations professionals with incident management experience find those sections intuitive but might struggle with concepts like reducing toil through software solutions or treating operations as a software problem. Wait, I should clarify. It's not that they can't understand it, but the mindset shift is really challenging when you've spent years doing things a certain way.
Developers get the automation and engineering mindset immediately. But sometimes they lack context for on-call rotations, escalation procedures, and the realities of production support (you know, the fun stuff that wakes you up at 2am).
The ideal candidate has lived in both worlds. Written code and carried a pager, dealt with production fires while also knowing how to prevent them through better architecture. If you've only done one, expect to study harder on the other side. I've seen ops folks spend most of their prep time understanding the software engineering approach to reliability, while developers focus heavily on incident response and operational concepts.
Cloud experience helps but isn't strictly required. Kubernetes knowledge is useful for understanding modern infrastructure patterns, though again, the exam stays tool-agnostic (which I mentioned earlier, but it's worth repeating). What matters more is whether you've thought about reliability as an engineering discipline rather than just a reactive firefighting exercise.
The preparation reality check
Most people need 40-60 hours of focused study.
But that number varies wildly based on experience. Someone already working as an SRE might need 20 hours of review, while someone transitioning from traditional IT operations might need 80+ hours to internalize the mindset shift, which honestly makes sense when you think about how different the approaches are.
Quality of preparation matters more than quantity, and I can't stress this enough because I've seen people waste so much time on unfocused studying. Structured study using solid materials (official PeopleCert resources, the Google SRE books, hands-on labs) will get you further than 100 hours of unfocused reading. Practice tests are absolutely critical because they reveal how the exam thinks, not just what it covers.
The retake rate isn't officially published, but anecdotally, most failures come from insufficient preparation or misunderstanding the exam's focus. People treat it like a memorization test and get burned by scenario questions requiring judgment and application. It's not that the exam is unfair. It's testing whether you can actually think like an SRE, which is harder than regurgitating facts.
Question style and what to expect
The questions are generally well-written with clear intent.
You won't encounter trick questions designed to deceive you with tricky wording, which honestly is refreshing compared to some certifications that seem to enjoy playing gotcha with candidates. But you will face questions where multiple answers are technically correct, and you need to select the best option based on SRE principles. That requires understanding not just what works, but what fits with the philosophy of site reliability engineering.
Some questions involve quantitative reasoning. Understanding metrics, calculating availability targets, thinking through error budget math that actually means something in the real world. You don't need to be a statistician, but you should be comfortable with the numbers side.
Terminology precision matters, like really matters in ways that might surprise you if you're used to more casual industry conversations. The exam uses specific SRE language, and if you're fuzzy on what terms mean, you'll misinterpret questions. That's why reading the official exam objectives and understanding each domain thoroughly is non-negotiable.
Making it easier on yourself
Look, the exam has a difficulty level, but you control a lot of the variables, which is kind of helping when you think about it. Thorough review of exam objectives eliminates surprises about what's covered. Multiple practice tests build familiarity with question style and timing. Hands-on exploration (even just setting up a simple monitoring dashboard or running through an incident response scenario) makes abstract concepts concrete in ways that reading never will.
Focus on understanding rather than memorization.
If you can explain why SRE principles work and apply them to new situations, you'll handle scenario questions fine. But if you've just memorized definitions without understanding the underlying reasoning, you're gonna have a bad time when the exam asks you to analyze a complex situation with competing priorities and no obvious single right answer.
The difficulty is real but manageable with proper preparation, and honestly, that's the takeaway here. It's testing legitimate knowledge and thinking skills, not trying to catch you on technicalities or obscure edge cases that nobody encounters in real work. Respect the breadth of coverage. Practice applying concepts to scenarios. And make sure you understand the SRE mindset, not just the mechanics. Do that, and the intermediate-to-advanced difficulty becomes achievable rather than intimidating.
Conclusion
So should you actually go for it?
Look, the PeopleCert DevOps-SRE certification isn't just another checkbox on your resume. It validates real stuff. Site reliability engineering principles, error budgets, incident management and postmortems, the whole observability stack. Honestly, if you're already doing SRE work or trying to break into it, this cert shows you understand the difference between uptime theater and actual reliability engineering metrics like SLI/SLO/SLA frameworks.
The DevOps-SRE exam itself? Not a walk in the park. I mean, you need to know your stuff across incident response, automation to reduce toil, capacity planning, and how to run blameless postmortems that actually improve systems instead of just pointing fingers. The passing score sits at 65%, which sounds reasonable until you realize the scenario-based questions can trip you up if you've only memorized definitions. You really need hands-on context.
Here's what makes this different from generic DevOps certs: the focus on service availability and systems thinking. it's "deploy faster" vibes. It's about balancing velocity with reliability, understanding error budgets as a tool for negotiation between product and engineering, and building resilience into everything you touch. That's the stuff that separates SRE roles from traditional ops or even standard DevOps positions. The thing is, lots of people don't realize how different these actually are until they're in the role, which makes job hunting awkward when you show up expecting one thing and get handed something completely different.
The PeopleCert SRE certification cost runs a few hundred dollars depending on your region and testing center. Not the cheapest, but also not AWS-level expensive. And yes, you'll need to think about renewal down the line, because PeopleCert does have recertification requirements to keep your credential current.
Actually preparing for the thing
Study materials matter more than you'd think.
The DevOps-SRE exam objectives are publicly available, but you need more than the syllabus. Books on SRE fundamentals help (Google's SRE book is still gold), but you also need practice applying concepts to scenarios. What do you do when your error budget's exhausted? How do you prioritize during a major incident when three teams are pinging you simultaneously and everyone thinks their issue is the most critical one affecting production? That kind of stuff.
DevOps-SRE practice tests are where preparation gets real. Not gonna lie, doing timed practice exams under realistic conditions showed me gaps I didn't know I had. Humbling but necessary. You want practice materials that explain why wrong answers are wrong, not just dump correct answers at you.
Mixed feelings here.
If you're serious about passing and you want the most efficient prep path, check out the DevOps-SRE Practice Exam Questions Pack. It's built to mirror the actual exam format and covers all the exam objectives with detailed explanations. Way better than going in blind or wasting time on materials that don't match what PeopleCert actually tests.
Get your hands dirty with monitoring dashboards, run some chaos experiments if you can, practice writing postmortem docs. Then validate your readiness with solid practice tests. You've got this.
Show less info
Hot Exams
Related Exams
Genesys Cloud Certified Professional - Contact Center Administration
Cisco Customer Success Manager (CSM)
Google AdWords Fundamentals
Microsoft Dynamics 365 Fundamentals Finance and Operations Apps (ERP)
HPE Edge-to-Cloud Solutions
PSE: Endpoint Associate training for Traps 4.0
HCNP - LTE RNP & RNO
Chartered Trust & Estate Planner® (CTEP®) Certification Examination
IBM Operational Decision Manager Standard V8.9.1 Application Development
SOA Design & Architecture Lab with Services & Microservices
Certified Implementation Specialist - Vulnerability Response
PeopleCert DevSecOps Exam
PeopleCert DevOps Engineer Exam
ITIL 4 Leader: Digital & IT Strategy Exam
ITIL 2011 Foundation
PeopleCert DevOps Site Reliability Engineer (SRE)
How to Open Test Engine .dumpsarena Files
Use FREE DumpsArena Test Engine player to open .dumpsarena files

DumpsArena.co has a remarkable success record. We're confident of our products and provide a no hassle refund policy.

Your purchase with DumpsArena.co is safe and fast.
The DumpsArena.co website is protected by 256-bit SSL from Cloudflare, the leader in online security.