C2090-101 Practice Exam - IBM Big Data Engineer
Reliable Study Materials & Testing Engine for C2090-101 Exam Success!
Exam Code: C2090-101
Exam Name: IBM Big Data Engineer
Certification Provider: IBM
Corresponding Certifications: IBM Analytics: Platform Analytics , IBM Analytics Platform


Free Updates PDF & Test Engine
Verified By IT Certified Experts
Guaranteed To Have Actual Exam Questions
Up-To-Date Exam Study Material
99.5% High Success Pass Rate
100% Accurate Answers
100% Money Back Guarantee
Instant Downloads
Free Fast Exam Updates
Exam Questions And Answers PDF
Best Value Available in Market
Try Demo Before You Buy
Secure Shopping Experience
C2090-101: IBM Big Data Engineer Study Material and Test Engine
Last Update Check: Mar 18, 2026
Latest 106 Questions & Answers
45-75% OFF
Hurry up! offer ends in 00 Days 00h 00m 00s
*Download the Test Player for FREE
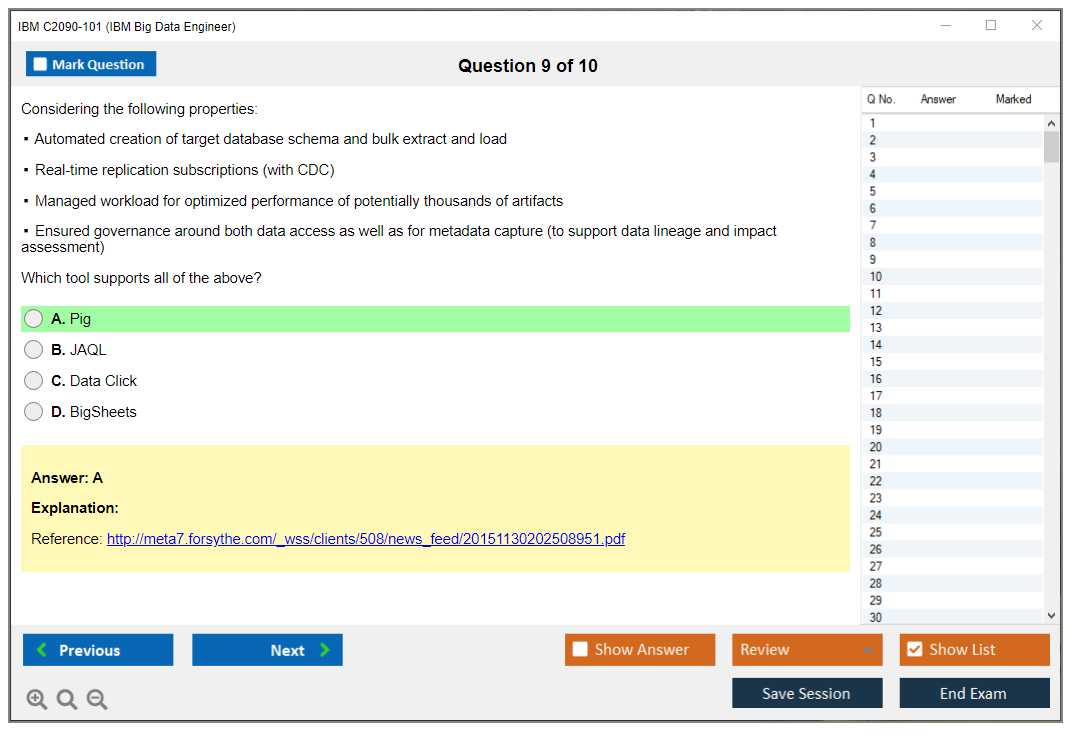
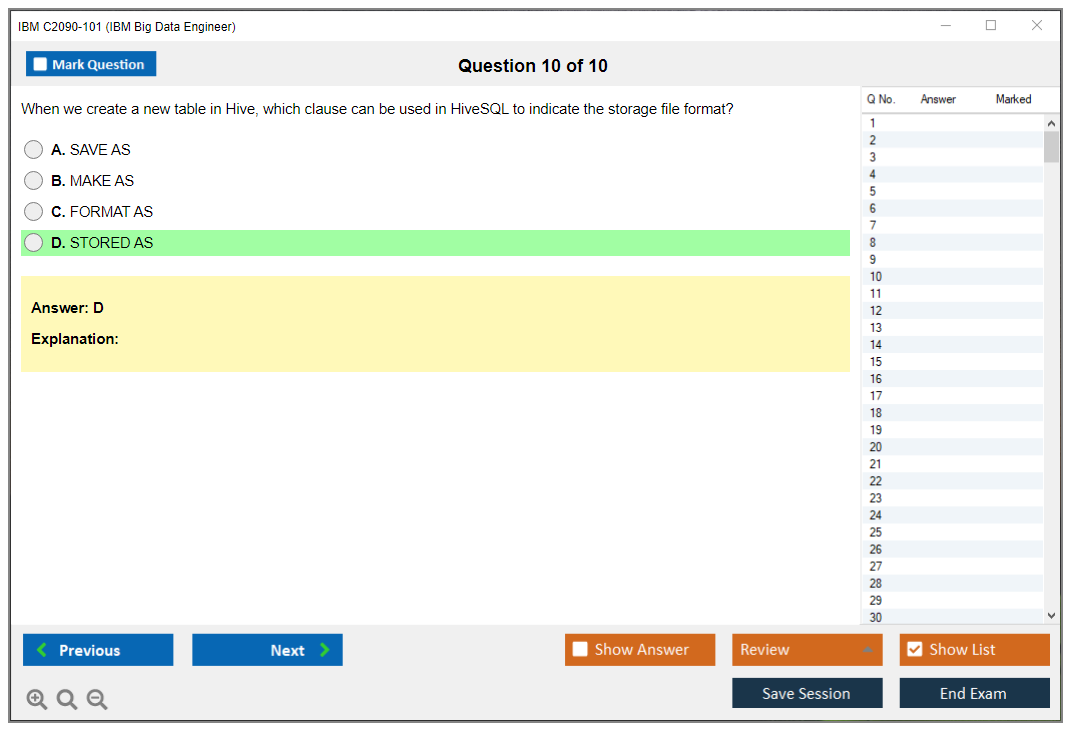
Dumpsarena IBM IBM Big Data Engineer (C2090-101) Free Practice Exam Simulator Test Engine Exam preparation with its cutting-edge combination of authentic test simulation, dynamic adaptability, and intuitive design. Recognized as the industry-leading practice platform, it empowers candidates to master their certification journey through these standout features.
What is in the Premium File?
Satisfaction Policy – Dumpsarena.co
At DumpsArena.co, your success is our top priority. Our dedicated technical team works tirelessly day and night to deliver high-quality, up-to-date Practice Exam and study resources. We carefully craft our content to ensure it’s accurate, relevant, and aligned with the latest exam guidelines. Your satisfaction matters to us, and we are always working to provide you with the best possible learning experience. If you’re ever unsatisfied with our material, don’t hesitate to reach out—we’re here to support you. With DumpsArena.co, you can study with confidence, backed by a team you can trust.
IBM C2090-101 Exam FAQs
Introduction of IBM C2090-101 Exam!
IBM C2090-101 is an exam for IBM Big Data Engineer certification. It tests a candidate's knowledge and skills related to the design, implementation, and maintenance of big data solutions using IBM Big Data technologies. The exam covers topics such as data ingestion, data transformation, data analysis, data visualization, and data security.
What is the Duration of IBM C2090-101 Exam?
The duration of the IBM C2090-101 exam is 90 minutes.
What are the Number of Questions Asked in IBM C2090-101 Exam?
There are 60 questions in the IBM C2090-101 exam.
What is the Passing Score for IBM C2090-101 Exam?
The passing score required in the IBM C2090-101 exam is 65%.
What is the Competency Level required for IBM C2090-101 Exam?
The IBM C2090-101 exam requires a competency level of Intermediate.
What is the Question Format of IBM C2090-101 Exam?
The IBM C2090-101 exam consists of multiple-choice and drag-and-drop questions.
How Can You Take IBM C2090-101 Exam?
IBM C2090-101 exam is available online and at testing centers. The online version is offered through Pearson VUE, and the testing center version is offered through Prometric. You will need to register for the exam through the appropriate website and pay the exam fee. When registering for the exam, you will need to provide a valid ID and select a testing location. Once you have registered, you will receive a confirmation email with your exam date, time, and location.
What Language IBM C2090-101 Exam is Offered?
IBM C2090-101 exam is offered in English language.
What is the Cost of IBM C2090-101 Exam?
The IBM C2090-101 exam is offered for a cost of $200 USD.
What is the Target Audience of IBM C2090-101 Exam?
The target audience for the IBM C2090-101 exam are IT professionals who wish to demonstrate their mastery of the IBM Big Data Architect V2 exam. This exam is designed for individuals who have experience working with IBM Big Data and related technologies, such as Apache Hadoop, Apache Spark, and IBM BigInsights. Candidates should also have a working knowledge of data warehousing, data analytics, and related technologies.
What is the Average Salary of IBM C2090-101 Certified in the Market?
The average salary for a certified IBM C2090-101 professional is around $90,000 per year.
Who are the Testing Providers of IBM C2090-101 Exam?
IBM offers a practice test for the C2090-101 exam. The practice test is available on the IBM website and is designed to help you prepare for the exam. It contains questions and answers that are similar to those you will encounter on the actual exam. Additionally, there are a variety of third-party providers that offer practice tests and other study materials for the C2090-101 exam.
What is the Recommended Experience for IBM C2090-101 Exam?
The recommended experience for IBM C2090-101 exam is three to five years of experience in developing data warehouse or business intelligence solutions using IBM Cognos Analytics. This should include experience in designing and developing Cognos Analytics solutions with dashboards, reports, and active reports. Candidates should also have experience in working with complex data models, data visualization techniques, and advanced analytics.
What are the Prerequisites of IBM C2090-101 Exam?
The IBM C2090-101 exam requires that the test-taker have a basic understanding of IBM Big Data and Analytics Platforms, as well as knowledge of common data analysis tasks and techniques. It is also recommended that the test-taker have experience with IBM BigInsights, IBM BigSQL, and IBM DataStage.
What is the Expected Retirement Date of IBM C2090-101 Exam?
The expected retirement date of IBM C2090-101 exam is currently unavailable. However, you can find more information about the exam on the IBM website: https://www.ibm.com/certify/exam.html?id=C2090-101
What is the Difficulty Level of IBM C2090-101 Exam?
The difficulty level of the IBM C2090-101 exam is considered to be moderate to difficult. It is recommended that you have a good understanding of the topics covered in the exam and have some experience working with the IBM BigInsights software before attempting the exam.
What is the Roadmap / Track of IBM C2090-101 Exam?
The IBM C2090-101 exam is part of the IBM Certified Data Engineer certification track. This exam tests a candidate's knowledge and skills in data engineering, data modeling, and data warehousing. The exam is designed to assess a candidate's ability to design, implement, and maintain data warehouses and data marts using IBM DB2. Passing this exam is a prerequisite for the IBM Certified Data Engineer certification.
What are the Topics IBM C2090-101 Exam Covers?
IBM C2090-101 exam covers the following topics:
1. Data Warehouse Fundamentals: This section covers the fundamentals of data warehousing, including topics such as data modeling, data integration, data management, and data warehousing architecture.
2. IBM DB2 Warehouse: This section covers the features and capabilities of IBM DB2 Warehouse, including topics such as the DB2 Warehouse Server, DB2 Warehouse Client, and DB2 Warehouse Manager.
3. Data Analysis: This section covers the basics of data analysis, including topics such as data mining, data visualization, and data exploration.
4. Business Intelligence: This section covers the fundamentals of business intelligence, including topics such as business intelligence tools, data warehousing best practices, and data analysis techniques.
5. Big Data: This section covers the fundamentals of big data, including topics such as Hadoop, Hive, and NoSQL.
6. Cloud Computing: This
What are the Sample Questions of IBM C2090-101 Exam?
1. What is the purpose of the IBM BigInsights Text Analytics component?
2. What is the IBM BigInsights File System (IBM BFS)?
3. What is the difference between Hadoop and IBM BigInsights?
4. How does IBM BigInsights use distributed computing to provide faster data processing?
5. What are the components of the IBM BigInsights Analytics Platform?
6. What is the purpose of the IBM BigInsights Data Refinery component?
7. How can IBM BigInsights be used to analyze unstructured data?
8. What is the IBM BigInsights Query Language?
9. What is the IBM BigInsights Workbench?
10. How can IBM BigInsights be used to improve the security of data?
IBM C2090-101 (IBM Big Data Engineer) Exam Overview Look, if you're reading this, you probably already know that big data isn't going anywhere. The IBM C2090-101 exam exists because companies need people who can actually build and maintain data pipelines that don't fall apart when you throw terabytes at them. I mean, it's one thing to talk about distributed computing in theory. This certification is about proving you can handle the real mess of enterprise data engineering. Why this certification matters for your career The IBM Big Data Engineer certification validates that you know how to design, build, and keep big data solutions running. Not just on paper. We're talking complete data pipelines: ingestion, processing, storage, the whole thing. Companies using IBM technologies want engineers who understand both the IBM ecosystem and how it plays with open-source frameworks like Hadoop and Spark. That's where a lot of the work happens anyway. This exam tests your knowledge of... Read More
IBM C2090-101 (IBM Big Data Engineer) Exam Overview
Look, if you're reading this, you probably already know that big data isn't going anywhere. The IBM C2090-101 exam exists because companies need people who can actually build and maintain data pipelines that don't fall apart when you throw terabytes at them. I mean, it's one thing to talk about distributed computing in theory. This certification is about proving you can handle the real mess of enterprise data engineering.
Why this certification matters for your career
The IBM Big Data Engineer certification validates that you know how to design, build, and keep big data solutions running. Not just on paper. We're talking complete data pipelines: ingestion, processing, storage, the whole thing. Companies using IBM technologies want engineers who understand both the IBM ecosystem and how it plays with open-source frameworks like Hadoop and Spark. That's where a lot of the work happens anyway.
This exam tests your knowledge of distributed computing approaches. Batch processing. Streaming architectures. You need to know when to use what and why one approach tanks performance while another scales beautifully. It also digs into data governance, security protocols, and compliance requirements because enterprise environments don't let you just dump data wherever you want. There are rules. Breaking them gets expensive fast.
Performance optimization is huge here too. Anyone can build a pipeline that works with a few gigabytes of test data. Can you tune it for production-scale workloads? The C2090-101 exam wants to see that you understand how to troubleshoot complex distributed systems when they fail. Because they will. Data quality frameworks, validation mechanisms, metadata management, lineage tracking. All of that becomes critical when you're dealing with data at scale. A lot of engineers skip this stuff early on and regret it later.
Who actually needs to take this exam
Data engineers with 1-3 years of hands-on experience building big data solutions are the main target. You've probably already dealt with some pipeline failures. Maybe optimized a few Spark jobs. You want formal validation of what you know. Software developers transitioning into data engineering roles also benefit, especially if they're already working with distributed systems but need to formalize their big data knowledge.
Database administrators looking to expand beyond traditional RDBMS work should consider this. ETL/ELT developers too. If you're moving from legacy integration tools to modern big data platforms, the C2090-101 helps bridge that gap. Solutions architects designing enterprise data infrastructure need this kind of certification to back up their recommendations. I've seen analytics professionals pursue it when they realize they need deeper technical understanding of how their data actually gets processed and delivered. Sometimes they've been asking for features that turned out to be physically impossible given the architecture, which is awkward in meetings.
IT professionals managing IBM big data deployments. Consultants advising on architecture. DevOps engineers working with data platform infrastructure. Technical leads establishing engineering standards for their teams. Basically, if you're responsible for making sure big data systems work reliably in production, this exam is worth your time.
What the actual exam looks like
You're looking at 55-65 questions, mostly multiple-choice and multiple-select. The whole thing runs 90 minutes. That's not a ton of time when some questions throw scenario-based problems at you, complete with code snippets or architectural diagrams. You need to know your stuff cold.
IBM delivers this through Pearson VUE testing centers worldwide, plus online proctored options if you prefer testing from home. It's computer-based, and you get immediate preliminary pass/fail notification when you finish. That's both great and nerve-wracking. Some questions clearly tell you how many options to select for multiple-select items. Others expect you to apply concepts to real-world situations, which is harder than it sounds when you're under time pressure.
No calculator allowed. No scratch paper in most cases. Maybe a digital notepad depending on delivery method. You can't mark questions for review and come back to them later in most IBM exam formats, so you're making decisions on the fly. Wrong answers don't penalize you beyond counting as incorrect, but unanswered questions hurt your score. The exam content updates periodically to match current IBM product versions and industry practices, which means older study materials can mislead you.
English is the primary language, with potential regional options. It's closed-book, zero external resources. Not adaptive testing. You get a fixed question set. After you finish, the results report shows section-level performance so you know which domains you crushed and which ones need work if you have to retake it.
How this connects to other IBM certifications
If you're already working with IBM cloud technologies, you might find overlap with certifications like the IBM Cloud Professional Architect v5. A lot of big data solutions now run in cloud or hybrid environments, and understanding cloud architecture helps you design better data pipelines. The IBM Cloud Pak for Integration V2021.2 Administration certification covers integration patterns that frequently appear in data engineering contexts.
For folks dealing with data transformation and ETL workloads specifically, the InfoSphere DataStage v11.3 exam dives deeper into IBM's traditional ETL tooling. It's older tech compared to Spark-based processing, but plenty of enterprises still run DataStage in production. Knowing both gives you more flexibility. The IBM Netezza Performance Server V11.x Administrator certification focuses on a specific data warehouse appliance that big data engineers often interact with. This matters especially for analytics workloads where query performance becomes critical.
Security considerations come up constantly in big data work, which makes the IBM Security Guardium V10.0 Administration relevant if you're handling sensitive data. Data governance isn't optional in regulated industries. And if you're supporting application developers who consume your data pipelines, understanding IBM App Connect Enterprise V11 Solution Development helps you design better APIs and integration points.
Preparing without losing your mind
Hands-on experience matters more than memorizing documentation. Build actual pipelines. Break them. Fix them. That's how you learn troubleshooting and performance tuning. The exam includes scenario-based questions that assume you've done this work before. Reading about data quality frameworks is one thing. Implementing validation logic that catches bad records in a 10TB daily ingestion job is something else.
Official IBM learning paths and product documentation should be your foundation. Focus on the exam objectives. Don't waste time on tangential topics. Practice tests help you identify weak areas, but make sure they're high-quality. Some practice exams floating around online are outdated or just plain wrong. The IBM Cognos Analytics Administrator V1 exam uses similar testing formats, so if you've taken that, you know what to expect from IBM's question style.
Set up a lab environment where you can actually run distributed processing jobs. Cloud platforms make this easier and cheaper than it used to be. You don't need a massive Hadoop cluster to learn the concepts, but you do need to see how data flows through a pipeline and where bottlenecks appear. Understanding concepts like data locality, partition strategies, and shuffle operations requires hands-on experimentation.
The C2090-101 exam isn't impossibly hard if you've been doing the work, but it's not a gimme either. It tests breadth across multiple domains and expects you to apply knowledge, not just recall facts. Take it seriously, prepare properly, and it becomes a solid credential that actually reflects your capabilities as a big data engineer.
IBM Big Data Engineer Certification Prerequisites and Recommended Experience
What this exam is really about
The IBM C2090-101 exam is IBM's older-school big data engineering credential that's heavily tied to the Hadoop ecosystem and "classic" data platform thinking. Honestly, it's less about trendy warehouse-only setups and more about proving you can move, store, process, and troubleshoot data when the system's distributed, messy, and under pressure.
Look, if you're aiming at a Big data engineering certification IBM path because your org still runs Hadoop, Spark, and enterprise governance, this one fits. If you only know modern managed cloud UIs, you can still pass, but the exam tends to reward people who've actually stared at logs at 2 a.m. and know what "why is YARN mad" feels like. That's the vibe.
Who should take it (and who probably shouldn't)
This IBM Big Data Engineer certification is for data engineers, platform engineers, and analytics engineers who touch ingestion, ETL/ELT, Spark jobs, cluster operations, security basics, and performance tuning. It also works for folks doing IBM analytics stacks in big companies, especially if you're trying to formalize your experience into an IBM data engineering credential.
Not gonna lie, if your day job's 95 percent dashboards and you never ship pipelines, you're going to have a rough time. Same if you've never used Linux and you treat the command line like a haunted house. Possible? Yes. Fun? No.
Exam format details (confirm before you schedule)
IBM changes delivery details over time, and some listings move between vendors, so treat this as a "go verify" section. The exam page is the source of truth for number of questions, time limit, and whether it's remote-proctored or test-center only. Seriously, confirm it on the official IBM listing before you plan your week around it.
Also, a quick note. I mean, some candidates obsess over "tricks." This exam usually isn't about gotchas. It's about scenario judgment and knowing what tool or setting solves the real problem.
Cost and registration basics
C2090-101 exam cost varies by country and currency, plus whatever the testing provider's doing this month. IBM usually routes you through their certification portal to purchase and schedule. Check there, because random blog numbers go stale fast.
Retakes. Same deal.
Policies and fees can change, so confirm on IBM's page or the vendor page right before you click buy. Paying twice hurts. I mean, paying once already hurts.
Passing score and scoring policy (again, confirm)
People ask about the C2090-101 passing score constantly. IBM exams often use scaled scoring, and sometimes they publish the passing mark, sometimes they don't, and sometimes it's visible only on the exam listing, so yes, check the exam page.
What you should expect, though, is a score report that at least hints at weak areas. Section-level feedback's usually broad, not a full "here's what you missed" breakdown. Don't expect a training plan gifted from above. You still have to do the work.
Difficulty level, realistically
The C2090-101 difficulty level is "wide but practical." Breadth gets people. You need storage concepts, ingestion patterns, processing (batch and streaming), governance/security basics, and operations knowledge. The hardest part? The thing is, you can't brute-force memorize your way through everything because lots of questions are "what would you do next" or "what's the best approach here."
Common failure mode: candidates know Spark APIs but not how jobs behave on a cluster when resources are constrained. Another one: people know Hadoop nouns, but not how data actually flows, where it lands, how partitions work, and why performance tanks. The exam wants applied thinking, not trivia night. Actually reminds me of the time I watched someone debug a skew issue for three hours before realizing they'd accidentally salted their join keys wrong and created a single massive partition. Sometimes the solution's embarrassingly simple once you see it.
Exam objectives and what to study (use IBM's exact blueprint)
I'm not going to pretend I can quote the current C2090-101 exam objectives word-for-word without risking being wrong. IBM updates blueprints. You should open the official exam guide and match your study plan to the listed domains exactly.
That said, the typical shape includes:
- data pipeline fundamentals and design
- Hadoop/Spark storage and processing concepts, the "Hadoop and Spark on IBM exam" style content
- ingestion and integration patterns
- data quality, governance, security
- ops, troubleshooting, tuning
Print the blueprint. Make it your checklist. Old-school, but it works.
Official prerequisites (what IBM actually requires)
Here's the part people overthink. The IBM Big Data Engineer prerequisites are basically "there aren't hard gates."
No mandatory prerequisite certifications are required to register for the IBM C2090-101 exam. You can sign up without having any earlier IBM badges. IBM recommends training, but doesn't require you to complete specific courses before attempting the exam. Training's a smart move, not a permission slip. There's no minimum number of years of professional experience formally required. IBM doesn't ask for your resume at checkout. Still, practical experience is a big deal for passing.
Foundational understanding of computer science is assumed, stuff like data structures, basic networking, OS concepts. But it's not a formal prerequisite you must prove. Having access to IBM big data platforms for hands-on practice is recommended, but not required just to register. You can technically sit the exam with zero lab time, which is wild, but it happens.
No age restrictions. No required degree. No "must be employed as a data engineer." None of that. Previous IBM certs can help. They're not required pathways, though, and you won't get blocked without them.
That's the official story. And honestly, it's good. Certs shouldn't be locked behind other certs unless there's a serious reason.
Recommended technical background (what you should already know)
Even without formal gates, you want a baseline. This is the "show up prepared" list, and yes, it's opinionated.
Start with SQL.
You need joins, aggregations, window-ish thinking, and some sense of query optimization. Not because the test's a SQL exam, but because data engineering without SQL is like cooking without a stove. You can do it, but why.
Pick at least one language and be comfortable reading code. Python's common. Scala shows up around Spark. Java's everywhere in enterprise stacks. R's less common for engineering pipelines, but you might see it in analytics-heavy orgs. Proficiency means you can debug, not that you can recite syntax. Big difference.
Linux matters. Command-line navigation, permissions, shell basics, grepping logs, editing configs. Fragments. Real life stuff.
Distributed systems concepts also show up more than people expect. CAP theorem, eventual consistency, partition tolerance, tradeoffs when the network's unreliable. You don't need to be a PhD. You do need to understand why "just scale it" isn't a plan.
Other good-to-have foundations:
- data modeling for structured and semi-structured data
- Git for versioning code and configs
- basic networking, ports, TLS, service endpoints
- containers like Docker, at least conceptually
- REST APIs and formats like JSON, XML, Avro, Parquet
- serialization and compression basics, because storage and transfer costs are real
Some of these you can learn while studying. But if all of them are new, slow down and build fundamentals first.
Hands-on experience expectations (what usually separates pass from fail)
IBM doesn't demand work history, but for exam success, I'd treat 12 to 18 months of practical big data experience as the realistic minimum. Not because you need a calendar. Because you need reps.
The biggest thing: you should've built ETL/ELT pipelines that process large datasets, ideally terabyte-scale or at least "too big for one machine without pain." You need to understand ingestion from databases, APIs, files, and streaming platforms, and what changes when the source is unreliable or late.
You also want real Hadoop ecosystem exposure. HDFS, YARN, MapReduce concepts, Hive, Pig. Even if you don't love Pig, you should know what it is and when it shows up in legacy environments. Spark's the main character for many teams, so expect batch and streaming patterns, plus the tuning knobs that matter.
Troubleshooting's where the exam gets honest. Failed jobs. Performance bottlenecks. Resource contention. Skew. Bad partitions. Misconfigured executors. The "why did this run in 10 minutes yesterday and 3 hours today" problem. If you've lived that, you'll recognize the right answers faster.
A few more experience areas that help a lot:
- orchestration with tools like Airflow or Oozie
- data quality checks at scale, not just "we eyeballed it"
- security basics around authentication, authorization, encryption at rest and in transit
- monitoring and logging for distributed systems
- Spark optimization including partitioning, caching, broadcast variables
- governance and metadata management concepts
- both batch and streaming architectures
- cloud exposure, and how deployment models change operations
- Agile/DevOps habits, CI/CD for pipelines
Not all of these need to be deep, but you should've touched most of them at least once.
Study materials and practice tests (what I'd do)
For C2090-101 study materials, start with IBM's official exam guide and any recommended courseware they list. Then pair it with product documentation, especially around Hadoop/Spark behavior, security config concepts, and operational troubleshooting.
For a C2090-101 practice test, be picky. Avoid brain-dump vibes. You want scenario questions that force you to reason, because the real exam tends to do that. My strategy: timed sets, an error log of what you missed and why, then focused drills on weak domains. Simple. Effective.
Quick FAQ hits (People also ask)
What is the IBM C2090-101 exam and who should take it?
It's an IBM big data engineering exam focused on distributed data processing and platform concepts. Data engineers and platform folks benefit most.
How much does the IBM C2090-101 exam cost?
The C2090-101 exam cost varies by region and vendor. Confirm in IBM's certification portal before scheduling.
What is the passing score for IBM C2090-101?
The C2090-101 passing score is listed (or not) on IBM's official exam page depending on the current policy. Don't trust old screenshots.
How hard is the IBM Big Data Engineer (C2090-101) exam?
The C2090-101 difficulty level is moderate to high if you lack hands-on ops and troubleshooting. With real pipeline experience, it's manageable.
What are the best study materials and practice tests for C2090-101?
Use the official IBM Big Data Engineer exam guide, IBM docs, and a reputable C2090-101 practice test that's scenario-based, not memorization bait.
IBM C2090-101 Exam Objectives and Core Domains
What you're actually signing up for with C2090-101
The IBM C2090-101 exam isn't your typical "memorize some definitions and you're good" certification. This thing tests whether you can actually architect, build, and maintain big data pipelines at enterprise scale. IBM designed this specifically for engineers who work with massive datasets (we're talking terabytes to petabytes) and need to prove they understand the entire ecosystem from ingestion through processing to storage and optimization.
The exam validates that you know your way around Hadoop, Spark, and the dozen other tools that make up modern big data infrastructure. But it goes deeper than that. You need to understand why you'd choose Parquet over Avro in specific scenarios, how to handle data skew that's killing your Spark job performance, and what happens when your HDFS NameNode goes down at 3 AM. Not exactly trivia questions.
The breadth is intense. One question might ask about Kafka consumer group rebalancing, the next about implementing slowly changing dimensions in your data warehouse layer. That variety is exactly what makes the C2090-101 practice exam questions pack so valuable. You need exposure before test day, period.
Pipeline architecture that actually matters in production
Data pipeline architecture is probably 25-30% of what you'll see on the exam. They don't just ask "what is a data pipeline?" They give you scenarios. Like, you've got a source system that generates 500GB of transaction data daily, some of it arrives late due to network issues, and you need to process it for both real-time dashboards and end-of-day batch reports. Now what?
You need to know the difference between lambda and kappa architectures cold. Lambda combines batch and streaming by running parallel processing paths and merging results. Kappa simplifies by treating everything as a stream. Each has trade-offs. Lambda gives you reprocessing flexibility but doubles your code maintenance. Kappa's cleaner but harder to handle major schema changes.
Change data capture comes up constantly. The exam expects you to understand incremental loads against full loads, and when CDC makes sense for capturing just the deltas from source databases. Schema evolution too. What happens when the upstream team adds a new field to their JSON payload and your pipeline needs to stay compatible with old and new data simultaneously?
Idempotency is huge. Your pipeline needs to produce the same results whether it runs once or five times on the same input data. The exam tests whether you understand exactly-once semantics in distributed systems and how to implement retry logic that doesn't create duplicate records.
Watermarking in stream processing? That thing separates people who've actually built streaming systems from those who just read about them. Event time against processing time, late-arriving data, how windows close. This stuff trips people up every time.
I remember the first time I had to explain watermarks to a junior engineer. She kept asking why we couldn't just use the current time for everything. Spent an hour drawing diagrams about mobile apps sending data after reconnecting to wifi, and how event time reflects when something actually happened versus when we received the message. That confusion shows up on the exam too.
Storage formats and when each one wins
File format selection sounds simple until you're choosing between four options for a specific workload. Parquet and ORC are both columnar formats optimized for analytics, but Parquet has better cross-platform support while ORC integrates tighter with Hive. Avro excels at schema evolution because it embeds the schema with each record. JSON's human-readable but terrible for large-scale analytics.
The exam loves asking about the small file problem in HDFS. When you've got millions of tiny files, the NameNode's memory gets hammered storing all that metadata, and MapReduce/Spark job startup times explode because the scheduler has to plan tasks for each file. Compaction strategies and proper partitioning solve this, but you need to know the details.
HDFS architecture questions come up often. How block replication works, what happens during a DataNode failure, read/write patterns. Understanding data locality is critical because moving data across the network is expensive. You want your compute tasks running on the same nodes where the data already lives.
NoSQL database selection? Another domain entirely. Key-value stores like HBase for fast lookups. Document databases like MongoDB when you need flexible schemas. Columnar stores like Cassandra for wide tables with billions of rows. Graph databases for relationship-heavy data. The exam gives you a use case and asks which fits best, so memorizing definitions won't cut it.
Data lake architecture typically organizes into raw/bronze, processed/silver, and curated/gold zones. Raw's exactly what came from source systems. Processed has cleaning and standardization applied. Curated is business-ready with joins, aggregations, and quality checks complete. Similar concepts appear in the C2090-424 InfoSphere DataStage exam focused on ETL tooling specifically.
Spark and Hadoop ecosystem depth requirements
Spark architecture questions go beyond surface-level knowledge. You need to understand the driver program creates the DAG of operations, the cluster manager allocates resources, and executors run the actual tasks. Lazy evaluation means transformations don't execute until you call an action. The Trigger optimizer rewrites your logical plan before execution.
RDD against DataFrame against Dataset. Each has its place. RDDs give you low-level control but lose Trigger optimization. DataFrames provide the best performance for structured data. Datasets add compile-time type safety in Scala/Java but aren't available in Python.
Structured Streaming builds on DataFrames for near-real-time processing. Micro-batch mode processes data in small intervals. Continuous processing mode achieves lower latency but supports fewer operations. Watermarks handle late data. Output modes determine whether you append new results, update existing ones, or rewrite everything.
MapReduce still appears because legacy systems use it and you need to understand the approach. Map phase processes input splits in parallel. Shuffle phase sorts and groups intermediate data by key. Reduce phase aggregates values for each key. Knowing when MapReduce makes sense compared to Spark matters.
Hive turns SQL into MapReduce or Spark jobs, letting analysts query HDFS data with familiar syntax. Partitioning tables by date or region dramatically speeds up queries that filter on those columns. Bucketing distributes data across files by hashing a column, useful for joins. The exam tests HiveQL syntax and optimization techniques like partition pruning.
YARN manages cluster resources. Queue configuration lets you allocate percentages of cluster capacity to different teams or workloads. Understanding fair scheduling compared to capacity scheduling comes up.
Performance tuning questions? Brutal. You'll get a Spark job configuration and have to identify why it's failing or running slowly. Maybe executor memory's too low and causing spills to disk. Could be you're using too few executors and underutilizing the cluster. Or shuffle partitions are too small and creating overhead.
Ingestion patterns from every possible source
Sqoop handles bulk transfers between RDBMS and HDFS. Import jobs pull data from databases using JDBC. Export jobs push data back. Incremental imports use a check column to grab only new/modified rows since last run. Understanding split-by columns for parallelizing imports matters.
Flume collects log data from distributed sources. Sources receive data, channels buffer it, and sinks write to destinations. Interceptors let you modify events in flight. Flume's great for aggregating application logs from hundreds of servers into HDFS or Kafka.
Kafka integration with Spark? Massive area of focus. Kafka topics partition data across brokers. Consumer groups parallelize consumption. Spark Structured Streaming can read from Kafka with exactly-once semantics using checkpointing. You need to understand offset management and what happens when consumers rebalance.
REST API ingestion comes up for pulling data from SaaS platforms. File-based ingestion handles CSV, JSON, XML. You need to know how to parse each format robustly, handling malformed records without crashing your pipeline. Similar integration patterns show up in the C1000-147 Cloud Pak for Integration exam from the API connectivity angle.
User-defined functions extend Spark and Hive with custom logic. You write them in Python, Scala, or Java. The exam might ask when to use a UDF instead of built-in functions, or how UDFs impact performance (they often prevent optimization).
Quality, governance, and keeping data secure
Data quality dimensions include accuracy, completeness, consistency, timeliness, validity. They form the foundation. The exam expects you to design validation checks that catch bad data early in the pipeline. Profiling reveals distributions and anomalies before you build transformations.
Metadata management tracks technical metadata (schemas, formats), business metadata (definitions, ownership), and operational metadata (run times, row counts). Data catalogs help users discover what datasets exist and understand what they contain.
Kerberos authentication secures Hadoop clusters using tickets and keytabs. RBAC controls who can access what data. Encryption at rest protects stored data. Encryption in transit uses TLS/SSL. The exam tests implementation details, not just concepts.
Data masking replaces sensitive values with realistic but fake data for non-production environments. Tokenization substitutes sensitive values with random tokens stored in a secure vault. Both help with compliance requirements like GDPR and HIPAA.
Audit logging tracks who accessed what data when. Retention policies automatically delete data after specified periods. Understanding how to implement these across distributed systems matters for the exam.
Troubleshooting when everything goes sideways
Data skew's the nightmare scenario where one partition gets 90% of the data while others sit idle. The exam asks how to detect it (look at task execution times in Spark UI) and fix it (repartition, salting keys, broadcast joins for small tables).
Memory tuning questions are common. Executor memory, driver memory, and memory overhead all need proper sizing. Out-of-memory errors have different causes. Maybe your dataset doesn't fit in memory and you need to increase executors. Or maybe you're caching too aggressively.
Shuffle optimization separates average and great Spark developers. Shuffles move data across the network and write to disk. You minimize them by filtering early, using broadcast joins when appropriate, and choosing the right number of shuffle partitions.
Broadcast joins work when one table's small enough to fit in memory on each executor. Spark sends a copy to every node, eliminating the shuffle needed for a regular join. The exam gives you table sizes and asks which join strategy to use.
Caching and persistence store intermediate results in memory or disk. Use it for datasets accessed multiple times in iterative algorithms. But cache too much and you'll run out of memory. The exam tests when caching helps compared to when it hurts performance.
Predicate pushdown moves filter operations as close to the data source as possible, reducing data read from disk. Partition pruning skips entire partitions that don't match filter criteria. Both dramatically improve query performance when used correctly.
Resource right-sizing involves matching cluster configuration to workload requirements. Overprovisioning wastes money. Underprovisioning causes failures and slow execution. The exam expects you to calculate appropriate executor counts, core allocations, and memory based on job characteristics.
The C2090-101 practice exam questions pack covers all these domains with scenario-based questions similar to what you'll face. At $36.99, it's cheaper than failing the real exam and having to pay again. Performance tuning scenarios especially benefit from practice because you need to recognize patterns quickly under time pressure.
How these objectives connect to real engineering work
What makes C2090-101 different from cloud-focused certifications like C1000-118 IBM Cloud Professional Architect is the emphasis on data-specific challenges at scale. Cloud architecture covers compute, networking, and services broadly. This exam dives deep into data pipeline internals, storage optimization, and processing frameworks.
If you're working with IBM's data platforms, you'll see overlap with exams like C1000-085 IBM Netezza Performance Server Administrator on the data warehousing side or C2090-623 IBM Cognos Analytics Administrator on the BI side. But C2090-101 focuses on the engineering layer that feeds those systems.
The exam difficulty? Sits somewhere between associate and professional level. You don't need years of experience, but you can't just read documentation for a week and pass. Hands-on practice with Spark, HDFS, and Kafka makes a huge difference. Actually building pipelines, watching them fail, troubleshooting the errors. That's what prepares you for scenario questions.
People with SQL and Linux backgrounds find parts easier, but distributed systems concepts trip up even experienced developers who haven't worked at scale. Understanding eventual consistency, partition tolerance, and CAP theorem trade-offs requires shifting how you think about data.
Study materials should include official IBM documentation, hands-on labs in a Hadoop environment, and quality practice tests. The C2090-101 practice exam questions pack helps identify weak areas before you schedule the real thing. Budget 6-8 weeks if you're studying part-time with limited big data experience, 3-4 weeks if you work with these tools daily.
IBM C2090-101 Exam Cost, Registration, and Policies
What this exam actually is
The IBM C2090-101 exam is tied to the IBM Big Data Engineer certification, and it's aimed at people who can build and operate data pipelines in an IBM-flavored big data stack. Not theory-only. Real-world-ish. You're expected to recognize what to do when data ingestion breaks, when Spark jobs crawl, when storage formats matter, and when governance rules turn a "quick fix" into a compliance problem.
If you're coming from general data engineering, this feels familiar, but the product naming and IBM analytics certification C2090-101 framing can throw people off. Hadoop and Spark on IBM exam topics show up, and the questions tend to be scenario based rather than "define this term." Some candidates ask about IBM Big Data Engineer prerequisites and expect an official checklist. Often there isn't a hard prerequisite listed, but you still need the skills or the exam'll humble you fast.
Also. Timing matters. Most versions of this exam run around 90 minutes, and delivery's either testing center or online proctored, but you should confirm the exact format on the current IBM listing because IBM changes exam pages over time and old blog posts get stale.
Price and what changes it
Let's talk C2090-101 exam cost, because that's what most people are trying to budget. The standard exam fee in the United States typically lands in the $200 to $300 USD range, but you need to verify current pricing on IBM's certification site or the Pearson VUE checkout screen because pricing does move. Sometimes quietly.
Country pricing's a whole other thing. Pricing varies by country and region due to local currency conversion and regional pricing policies, which means your coworker in Canada and your teammate in India might pay different amounts even on the same day, and neither of you's "getting ripped off," that's just how the program's set up.
The more interesting part's the discounts. IBM occasionally offers promotional discounts during special events, and I've also seen organizations buy in bulk and get vouchers as part of internal enablement programs. Academic pricing may be available for students enrolled in accredited institutions, but don't assume. Verify eligibility requirements, because "I have a .edu email" isn't always enough.
One detail people miss. There's typically no separate fee for online proctored vs. testing center delivery, so the same base price applies, even though the experience's totally different. Your real extra costs are optional, like training courses, a C2090-101 practice test, and C2090-101 study materials that aren't free. Corporate training packages sometimes bundle exam vouchers with courseware at a discounted rate, which's great if your employer's paying, and annoying if you're self funding because you see the bundle price and think you can get it solo.
Vouchers also expire. Exam vouchers typically have expiration dates, commonly 12 months from purchase, and yes, people forget and lose them. I mean, set a calendar reminder the day you buy it. Future you'll thank you.
Where you register and how scheduling works
Registration's through Pearson VUE, IBM's authorized testing partner. You create an account on the Pearson VUE site, then search for the exam by code "C2090-101" or by the name "IBM Big Data Engineer" in the catalog, and then you pick delivery type.
Two choices. Testing center or online proctored.
Testing center appointments are usually available during business hours Monday through Saturday, depending on the location. The thing is, online proctored exams offer more flexible scheduling, including evenings and weekends, which's great if you work weird hours or you just test better at night, but it also means your home setup has to be perfect and your roommates need to cooperate.
Schedule at least 24 to 48 hours in advance if you can, because popular slots disappear, though last-minute openings do happen. After you schedule, you get a confirmation email that includes exam details, location info or technical requirements, and the check-in procedures. Keep it. Don't rely on "I'll just search my inbox later." Later never comes.
One more admin thing: an IBM account may be required for credential tracking and digital badge issuance post-exam. That part's usually painless, but if your name differs across accounts, fix it early because mismatched names are how people get blocked at check-in.
Testing center rules vs online proctoring reality
At a testing center, you arrive 15 to 30 minutes early for check-in and identity verification. Valid, unexpired government-issued photo ID's required, like a passport, driver's license, or national ID card, and the name must match your registration exactly. Not "close enough." Exactly.
Then the ritual begins. Personal belongings including phones, watches, bags, and notes go into provided lockers. The testing center provides the computer, monitor, and a quiet environment. It's boring. That's the point. You sit down, you test, you leave.
Online proctoring's more personal and more annoying. You need a webcam, microphone, stable internet, and a compatible computer, and you'll do a room scan and workspace check before the exam starts to prove you're following policy. No additional monitors. No phones. No one walking behind you. If you live in a small place, that can be harder than the exam itself.
I once had a neighbor start drilling through concrete at 9 AM on a Saturday. Naturally, that was exactly when I'd scheduled my proctored exam. Noise canceling headphones aren't allowed, and explaining "my building's being renovated" to a proctor through a chat window while calculus problems are counting down is its own kind of nightmare. Test on a weekday if you can.
Breaks usually aren't permitted during the 90-minute exam duration, so plan accordingly before starting. Water, bathroom, shut down notifications, close every app you don't need. Friction kills focus.
Retakes, waiting periods, and the money part
Retake rules are where people get surprised, especially if they're used to "retake tomorrow" vendor exams. For the IBM C2090-101 exam, if you fail your first attempt, there's a 14-day waiting period before the second attempt. After the second failure, it's another 14-day waiting period before the third attempt. After the third failure, there's a 6-month waiting period before the fourth and subsequent attempts.
That 6-month rule's brutal. It basically forces you to stop guessing.
Each retake requires purchasing a new exam voucher at full price, with no discounted retake fees, so the cost adds up fast. There's no limit on total attempts, but waiting periods and costs pile up, and at some point it's cheaper to step back and fix your fundamentals than to keep paying.
Score reports from failed attempts typically provide section-level feedback, which's actually useful if you treat it like a diagnostic instead of a punch in the gut. Passing score achieved on any attempt results in full certification, with no distinction between first-attempt vs. retake passes, so nobody sees your scars.
Missed appointments are usually non-refundable. Rescheduling's typically allowed up to 24 to 48 hours before exam time, but cancellation policies vary, so review Pearson VUE terms for the exact deadlines in your region.
Passing score, scoring, and what "good enough" means
People always ask about C2090-101 passing score, and the honest answer's you should confirm it on the official IBM exam page because IBM's used different scoring approaches across programs. Some exams use scaled scoring, some report as percentages, and some only show pass/fail plus domain feedback.
Even when you know the number, don't obsess over it. Focus on the C2090-101 exam objectives and whether you can answer scenario questions without hand-waving. If you're doing practice questions and your reasoning's "I think IBM wants option C," that's not knowledge, that's vibes, and vibes don't pass exams consistently.
How hard it feels in the real world
The C2090-101 difficulty level depends on your background. If you've actually built pipelines, tuned Spark jobs, handled schema drift, and fought with access controls, it's manageable. If your experience's mostly notebooks and dashboards, it can feel like a wall because this exam expects engineering thinking, not analytics tourism.
Big data engineering certification IBM exams tend to reward breadth. You need storage basics, processing fundamentals, ingestion patterns, transformation logic, data quality checks, governance considerations, plus performance tuning and troubleshooting. Not gonna lie, the breadth's what gets people, not the trickiness of any single topic.
Prep resources that don't waste your time
Start with the official IBM Big Data Engineer exam guide and the published blueprint, because that's what the writers used. Then get hands-on, even if it's a small lab. Reading alone's slow.
For paid prep, I'm a fan of mixing one solid question bank with your own error log. If you want something lightweight and focused, the C2090-101 Practice Exam Questions Pack is cheap enough to fit most budgets, and using it in timed sets can expose weak domains quickly. Use it like a mirror, not a security blanket. If you just memorize, the real exam'll feel different and you'll panic anyway.
Also worth mentioning casually: IBM documentation, product guides, and whatever official learning path IBM links from the certification page. Those are usually aligned with the IBM data engineering credential expectations, even if the docs are sometimes a slog.
If you want a second pass at exam-style questions closer to test day, loop back to the C2090-101 Practice Exam Questions Pack and redo only the ones you missed, slowly, writing why each wrong answer's wrong. Boring. Effective.
Quick FAQs people search
What is the IBM C2090-101 exam and who should take it? It's a certification exam for IBM Big Data Engineer certification candidates, best for data engineers working with distributed processing and pipeline operations in IBM environments.
How much does the IBM C2090-101 exam cost? Typically $200 to $300 USD in the US, with regional variation. Verify on IBM or Pearson VUE at checkout.
What is the passing score for IBM C2090-101? Confirm on the official exam page, since scoring and reporting can change.
How hard is the IBM Big Data Engineer (C2090-101) exam? Medium to hard if you lack hands-on pipeline experience. Easier if you've worked with Spark/Hadoop concepts, troubleshooting, and governance.
What are the best study materials and practice tests for C2090-101? Official blueprint plus targeted practice questions and hands-on labs. A paid option's the C2090-101 Practice Exam Questions Pack if you want exam-style repetition without paying for a full course.
C2090-101 Passing Score and Scoring Methodology
Look, the C2090-101 passing score is one of those things where IBM doesn't make it super crystal-clear on every page, but the general threshold sits around 65-70%. I've seen candidates obsess over the exact number, but honestly the scoring methodology matters way more than hitting some magic percentage.
Why the exact number isn't as simple as you'd think
IBM uses scaled scoring instead of just counting up your correct answers and calling it a day. This means your raw score (like getting 40 out of 60 questions right) gets converted through an algorithm that accounts for difficulty variations between different exam versions. Not gonna lie, this confused me at first. Two people could answer the same number of questions correctly but get slightly different scaled scores if they took different question sets.
Why does IBM do this? Fairness, basically. If you get a slightly harder version of the exam compared to someone who tested last week, the scaled scoring compensates for that. The passing threshold stays consistent regardless of which specific questions you see. Pretty smart actually, even if it makes the math less transparent from a candidate's perspective. I mean, who doesn't want a straightforward percentage? Then again, my cousin took the CPA exam and complained about the same thing for months, so maybe opacity is just how certification bodies operate now.
How many questions you actually need to pass
Typically what you'll see:
The C2090-101 usually has somewhere between 55-65 questions depending on the version you get. Working with the 65% passing threshold and say 60 questions, you'd need roughly 39 correct answers. But remember, that's oversimplifying because of the scaled scoring. The actual number required varies based on which questions you get and how the algorithm weights them.
Most candidates I've talked to estimate they needed between 36-45 correct answers to pass, which tracks with that range. Here's what matters though: there's no penalty for guessing. An unanswered question scores exactly the same as a wrong answer. Fill in every single bubble before time runs out.
What happens immediately after you finish
You get a preliminary pass/fail result displayed on screen as soon as you complete the computer-based exam through Pearson VUE. That moment? Either a huge relief or pretty crushing. No in-between. The system calculates everything automatically using IBM's proprietary scoring algorithms, and you'll know within seconds whether you passed.
Your official score report becomes available through your Pearson VUE account typically within 5 business days, though I've seen it show up in 2-3 days sometimes. If you passed, you'll also receive a digital badge and the official IBM Big Data Engineer certification credential. The digital badge is actually useful for LinkedIn and your resume, way better than the old PDF certificates that just sat in a folder somewhere gathering digital dust.
Understanding what your score report actually tells you
Here's where it gets interesting. Or frustrating, depending on your perspective. Many IBM certification exams don't give you a specific numerical score. You just get pass or fail. The C2090-101 score report breaks down your performance by domain or objective area with labels like "above target," "near target," or "below target." This domain-level feedback is incredibly valuable if you failed because it tells you exactly where to focus your remediation efforts.
Passing candidates typically get less detailed breakdowns since, well, you already achieved certification. The report still shows section performance but IBM figures if you passed you don't need as much diagnostic detail. Makes sense from their perspective even if it's a bit frustrating when you want to know your exact score.
Each domain gets weighted. The report accessible through Pearson VUE under "Exam History" shows how you performed across data engineering fundamentals, big data storage and processing concepts, data pipeline design, transformation logic, quality considerations, and operational troubleshooting. Scored "below target" in Hadoop/Spark ecosystem concepts but "above target" everywhere else? You know exactly what killed your score.
The scaled scoring mechanics you should understand
No partial credit.
This trips people up constantly. If a question asks you to select all correct options and there are three right answers, you must choose all three to get credit. Pick two out of three and you get zero points, same as if you picked completely wrong answers. Harsh but consistent across IBM's testing platform.
Each question typically carries equal weight in IBM certification exams unless the official exam guide specifies otherwise. I haven't seen evidence that the C2090-101 uses differential question weighting, but the scaled scoring algorithm itself creates a kind of weighting by adjusting for difficulty. A particularly hard question that most candidates miss doesn't tank your score as much as missing an easy question that 90% of people get right.
The raw-to-scaled conversion happens behind the scenes. You never see your raw score, just the scaled result and the domain breakdowns. Some candidates find this annoying because they want full transparency, but standardized testing has used scaled scoring for decades. The GRE, GMAT, and most professional certifications work the same way.
What to do with your score report if you didn't pass
Look at those domain-level performance indicators seriously. "Below target" in multiple areas? You need a more thorough study approach. No shortcuts. But if you're "near target" or "above target" in most domains and only weak in one or two, focus your remediation there. I've seen people waste weeks re-studying stuff they already knew instead of drilling their actual weak spots, which is just inefficient use of your time.
The retake policy matters here too. IBM typically requires a waiting period between attempts, and you'll pay the full exam fee again. Verify the current retake policy on the official IBM certification page because these policies do change. Making sure you're truly ready for the retake saves you both time and the C2090-101 exam cost, which isn't cheap.
If you're looking at related IBM certifications, the scoring methodology is similar across their portfolio. The IBM Cloud Professional Architect v5 uses the same scaled scoring approach, as does the InfoSphere DataStage v11.3 exam. Understanding how IBM calculates scores helps across their entire certification track.
Preparing strategically for the scoring system
Since there's no guessing penalty, time management becomes critical. Don't spend five minutes agonizing over one question when you could mark it for review and move on. Answer everything, then use remaining time to revisit flagged questions. The IBM AI Enterprise Workflow V1 Data Science Specialist exam taught me this lesson the hard way. Left three questions blank and definitely regretted it.
Practice tests should simulate the real scoring conditions. Time yourself strictly. When you review wrong answers, focus on understanding the underlying concepts rather than memorizing specific questions. The scaled scoring means you can't predict exactly which questions matter most, so you need broad competency across all exam objectives.
The domain feedback? That becomes your roadmap. Failed candidates who ignore that breakdown and just study everything equally often fail again. Use that data. It's literally telling you where IBM thinks you're deficient.
Conclusion
So where does that leave you with the IBM C2090-101 exam?
Okay, real talk.
The IBM Big Data Engineer certification isn't gonna be a walk in the park. The C2090-101 difficulty level sits somewhere between "you need actual hands-on experience" and "cramming the night before will absolutely wreck you." If you've been working with Hadoop, Spark, or similar big data platforms for even six months to a year (maybe longer, depending on how deep you got into the weeds) you're in a way better position than someone trying to memorize dumps without understanding how data pipelines actually break when you're three hours into a production incident and everyone's pinging you on Slack.
The C2090-101 exam cost varies depending on where you register. It's not cheap, though. IBM analytics certification C2090-101 pricing typically runs a few hundred dollars, so you definitely don't wanna burn through retake fees because you skipped the fundamentals or thought YouTube videos alone would carry you. The C2090-101 passing score is usually around 65-70%. Confirm that on the official exam page because IBM tweaks it sometimes. But here's the thing: don't aim for the minimum. You want buffer room. Scenario questions can trip you up even when you know the tech inside out, I mean they're designed that way.
What really matters? How you actually use C2090-101 study materials.
Official IBM documentation is dense as hell but it's gold for exam objectives. Data ingestion patterns, transformation logic, those weird performance tuning quirks that only show up in real deployments when your manager's breathing down your neck. Combine that with hands-on labs. Spin up a local Spark cluster, break it on purpose, fix it. That muscle memory pays off big when you hit a troubleshooting question and have three minutes to pick the right answer while your brain's running on fumes.
I spent way too long once trying to optimize a job that was already fine. Turned out the bottleneck was in a completely different service I wasn't even monitoring. That kind of lesson sticks with you, and those are the situations the exam tries to recreate through its questions.
Not gonna lie, a solid C2090-101 practice test is one of the smartest investments you'll make in your prep. Maybe the smartest, actually. It exposes gaps you didn't even know existed and forces you to work under time pressure, which is exactly what the real exam throws at you from question one. Practice questions also help you recognize IBM's question style, and they love asking 'what would you do first' or 'which approach minimizes latency' instead of pure recall stuff.
If you're serious about passing on the first attempt and actually retaining what you learn for your career as an IBM data engineering credential holder (not just passing and forgetting everything two weeks later) check out the C2090-101 Practice Exam Questions Pack. It's built to mirror the real exam structure and covers all the big data engineering certification IBM topics you'll face. Use it as a diagnostic early, then again as a final run-through before test day. Your future self, and your wallet, will thank you.
Show less info
Hot Exams
Related Exams
IBM Cloud Technical Advocate v3
IBM Security QRadar SIEM V7.4.3 Deployment
IBM Mobile Foundation v8.0 Application Development
IBM Tivoli Monitoring V6.3 Fundamentals
IBM Cloud Pak for Business Automation v21.0.3 Solution Architect
IBM SPSS Statistics Level 1 v2
IBM Informix 12.10 System Administrator
IBM Security Guardium V10.0 Administration
IBM Cloud Pak for Data v4.x Solution Architecture
IBM FileNet P8 V5.5.3 Deployment Professional
IBM InfoSphere Optim for Distributed Systems v9.1
Cloud Pak for Integration v2021.4 Solution Architect
IBM Cloud Advocate v2
IBM Big Data Architect
Rational Team Concert V6
IBM Sterling Order Management v10.0 and Order Management on Cloud Architect
How to Open Test Engine .dumpsarena Files
Use FREE DumpsArena Test Engine player to open .dumpsarena files

DumpsArena.co has a remarkable success record. We're confident of our products and provide a no hassle refund policy.

Your purchase with DumpsArena.co is safe and fast.
The DumpsArena.co website is protected by 256-bit SSL from Cloudflare, the leader in online security.