Databricks-Certified-Professional-Data-Scientist Practice Exam - Databricks Certified Professional Data Scientist Exam
Reliable Study Materials & Testing Engine for Databricks-Certified-Professional-Data-Scientist Exam Success!
Exam Code: Databricks-Certified-Professional-Data-Scientist
Exam Name: Databricks Certified Professional Data Scientist Exam
Certification Provider: Databricks
Certification Exam Name: Databricks Certification


Free Updates PDF & Test Engine
Verified By IT Certified Experts
Guaranteed To Have Actual Exam Questions
Up-To-Date Exam Study Material
99.5% High Success Pass Rate
100% Accurate Answers
100% Money Back Guarantee
Instant Downloads
Free Fast Exam Updates
Exam Questions And Answers PDF
Best Value Available in Market
Try Demo Before You Buy
Secure Shopping Experience
Databricks-Certified-Professional-Data-Scientist: Databricks Certified Professional Data Scientist Exam Study Material and Test Engine
Last Update Check: Mar 18, 2026
Latest 138 Questions & Answers
45-75% OFF
Hurry up! offer ends in 00 Days 00h 00m 00s
*Download the Test Player for FREE
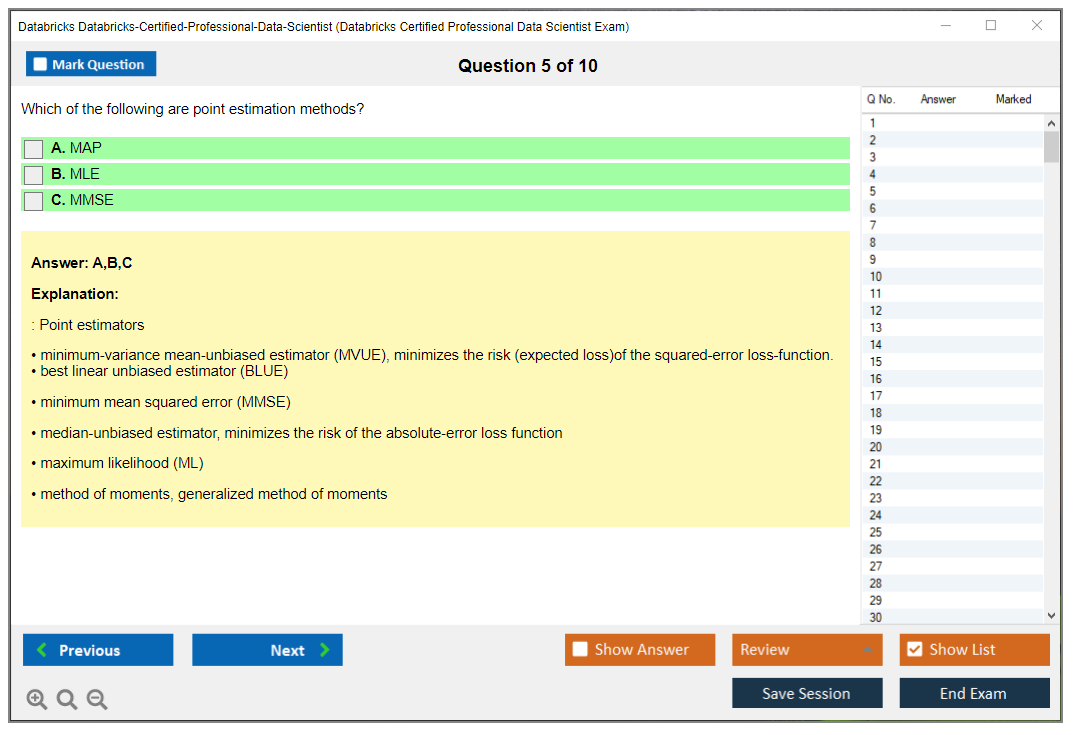
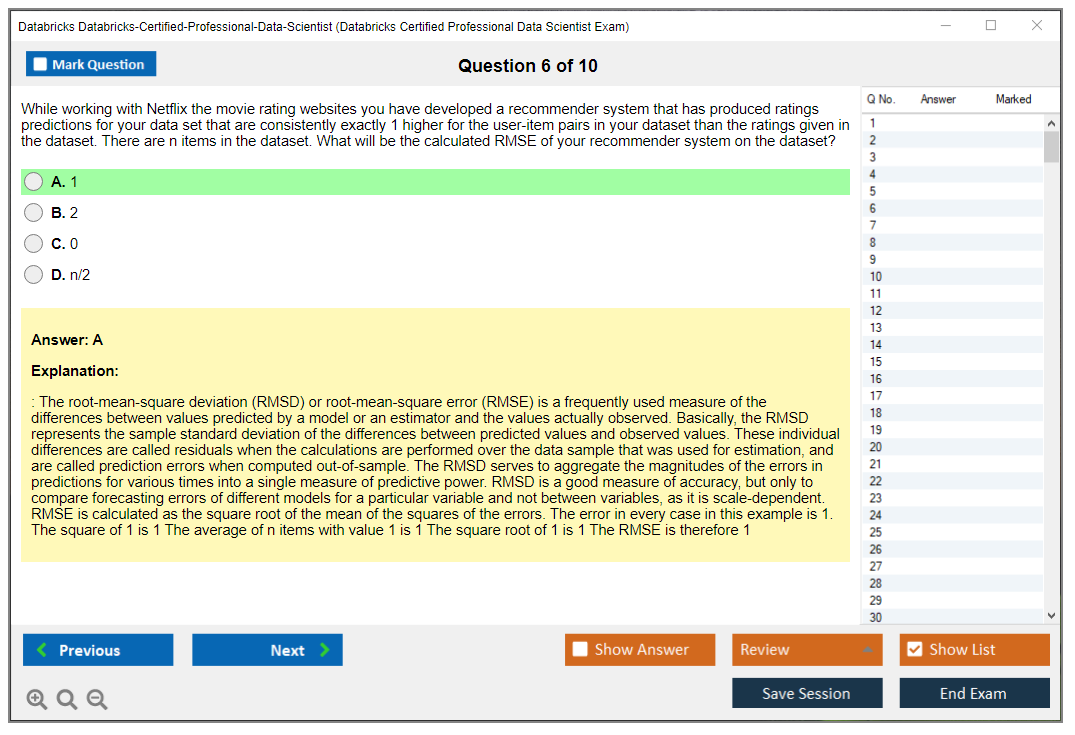
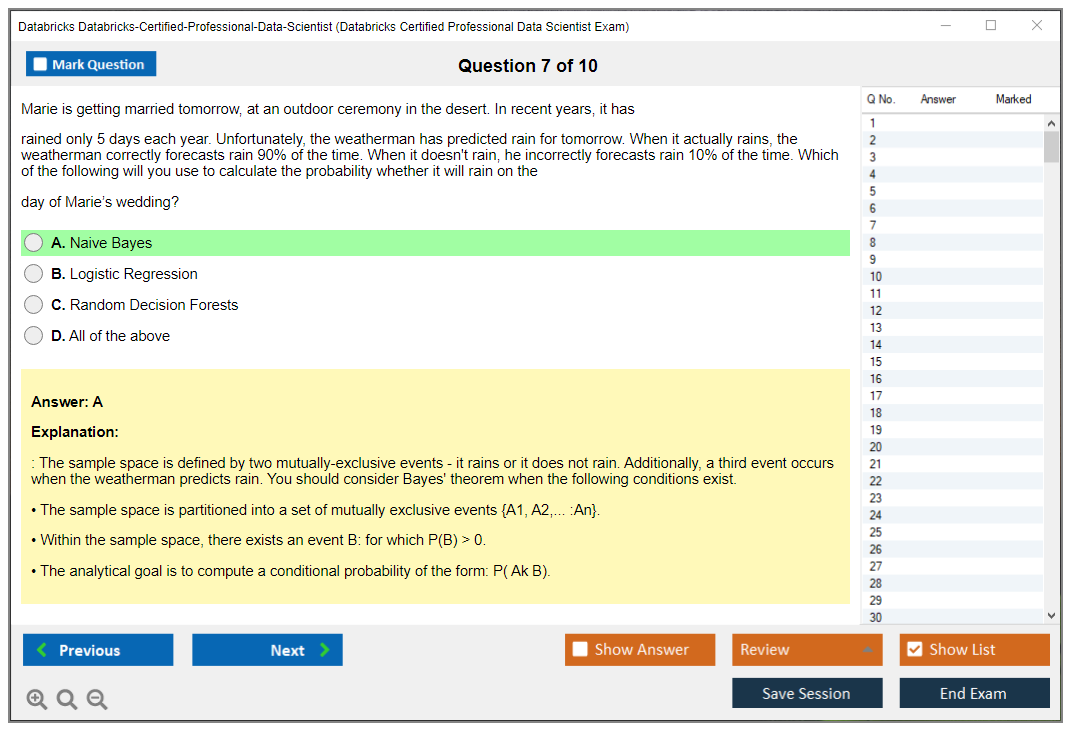
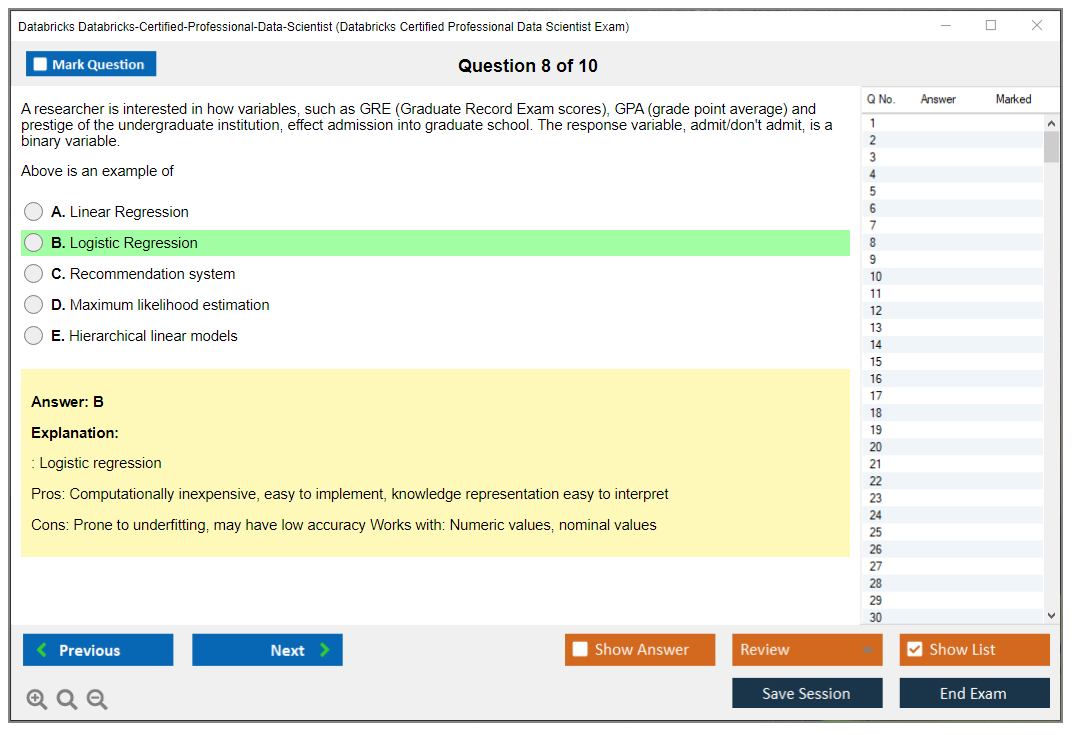
Dumpsarena Databricks Databricks Certified Professional Data Scientist Exam (Databricks-Certified-Professional-Data-Scientist) Free Practice Exam Simulator Test Engine Exam preparation with its cutting-edge combination of authentic test simulation, dynamic adaptability, and intuitive design. Recognized as the industry-leading practice platform, it empowers candidates to master their certification journey through these standout features.
What is in the Premium File?
Satisfaction Policy – Dumpsarena.co
At DumpsArena.co, your success is our top priority. Our dedicated technical team works tirelessly day and night to deliver high-quality, up-to-date Practice Exam and study resources. We carefully craft our content to ensure it’s accurate, relevant, and aligned with the latest exam guidelines. Your satisfaction matters to us, and we are always working to provide you with the best possible learning experience. If you’re ever unsatisfied with our material, don’t hesitate to reach out—we’re here to support you. With DumpsArena.co, you can study with confidence, backed by a team you can trust.
Databricks Databricks-Certified-Professional-Data-Scientist Exam FAQs
Introduction of Databricks Databricks-Certified-Professional-Data-Scientist Exam!
The Databricks Certified Professional Data Scientist exam is a comprehensive exam that tests a candidate's knowledge and skills in data science, machine learning, and Apache Spark. The exam covers topics such as data wrangling, data exploration, data visualization, machine learning, and Apache Spark. The exam is designed to assess a candidate's ability to apply data science techniques to real-world problems.
What is the Duration of Databricks Databricks-Certified-Professional-Data-Scientist Exam?
The Databricks Databricks-Certified-Professional-Data-Scientist exam is a 2-hour online proctored exam.
What are the Number of Questions Asked in Databricks Databricks-Certified-Professional-Data-Scientist Exam?
There are a total of 60 questions on the Databricks Certified Professional Data Scientist exam.
What is the Passing Score for Databricks Databricks-Certified-Professional-Data-Scientist Exam?
The passing score for the Databricks Certified Professional Data Scientist exam is 70%.
What is the Competency Level required for Databricks Databricks-Certified-Professional-Data-Scientist Exam?
The Databricks Certified Professional Data Scientist exam requires a competency level of professional Data Scientist. This level of competency includes an understanding of the principles and techniques of data science, including data wrangling, feature engineering, machine learning algorithms, and predictive analytics. It also requires experience in the use of Databricks tools and technologies, such as Apache Spark, Delta Lake, and MLFlow.
What is the Question Format of Databricks Databricks-Certified-Professional-Data-Scientist Exam?
The Databricks Certified Professional Data Scientist exam consists of multiple-choice questions, fill-in-the-blank questions, and drag-and-drop questions.
How Can You Take Databricks Databricks-Certified-Professional-Data-Scientist Exam?
The Databricks Certified Professional Data Scientist exam can be taken online or at a testing center. To take the exam online, you will need to register for an account at the Databricks website and purchase an exam voucher. Once you have purchased the voucher, you will be able to access the exam and take it at your own pace. To take the exam at a testing center, you will need to register for an exam at a Pearson VUE testing center. You will need to bring a valid form of identification and your exam voucher to the testing center.
What Language Databricks Databricks-Certified-Professional-Data-Scientist Exam is Offered?
The Databricks-Certified-Professional-Data-Scientist Exam is offered in English.
What is the Cost of Databricks Databricks-Certified-Professional-Data-Scientist Exam?
The Databricks-Certified-Professional-Data-Scientist Exam is offered at a cost of $250 USD.
What is the Target Audience of Databricks Databricks-Certified-Professional-Data-Scientist Exam?
The target audience of the Databricks-Certified-Professional-Data-Scientist exam is professionals with at least two years of experience in data science, analytics, or related disciplines who have a strong understanding of the principles of data science, machine learning, and data engineering, and who have experience working with Databricks.
What is the Average Salary of Databricks Databricks-Certified-Professional-Data-Scientist Certified in the Market?
The average salary for a Data Scientist with a Databricks Certified Professional Data Scientist certification is around $120,000 per year. However, salaries can vary depending on experience, location, and other factors.
Who are the Testing Providers of Databricks Databricks-Certified-Professional-Data-Scientist Exam?
The Databricks Certified Professional Data Scientist exam is provided by the Databricks Academy. The exam is proctored online and requires a secure internet connection and webcam.
What is the Recommended Experience for Databricks Databricks-Certified-Professional-Data-Scientist Exam?
The recommended experience for the Databricks Certified Professional Data Scientist exam is a minimum of five years of hands-on experience with data science, machine learning, and big data technologies. Knowledge of Apache Spark, Python, and SQL, as well as experience with distributed computing and cloud-based technologies, is also recommended.
What are the Prerequisites of Databricks Databricks-Certified-Professional-Data-Scientist Exam?
The Prerequisite for Databricks Certified Professional Data Scientist Exam is a basic understanding of Databricks, Data Science and Machine Learning fundamentals. Candidates must also have a working knowledge of Python, SQL, and Big Data technologies.
What is the Expected Retirement Date of Databricks Databricks-Certified-Professional-Data-Scientist Exam?
The official website to check the expected retirement date of Databricks Databricks-Certified-Professional-Data-Scientist exam is https://www.databricks.com/certification/exam-retirement-dates.
What is the Difficulty Level of Databricks Databricks-Certified-Professional-Data-Scientist Exam?
The difficulty level of the Databricks Certified Professional Data Scientist exam is considered to be intermediate.
What is the Roadmap / Track of Databricks Databricks-Certified-Professional-Data-Scientist Exam?
The Databricks-Certified-Professional-Data-Scientist Exam is a certification track and roadmap developed by Databricks, a cloud-based data platform. This certification track is designed to validate an individual’s proficiency in data science, including topics such as data wrangling, machine learning, and data visualization. The exam covers a broad range of topics and is designed to assess an individual’s ability to apply data science principles and techniques to solve real-world problems. The certification is a great way to demonstrate proficiency in the field of data science and is a valuable asset for those looking to advance their careers in the field.
What are the Topics Databricks Databricks-Certified-Professional-Data-Scientist Exam Covers?
The Databricks Certified Professional Data Scientist exam covers the following topics:
1. Data Manipulation: This covers the basics of manipulating data using Spark SQL, DataFrames, and Databricks Delta. This includes topics such as joins, filters, and aggregations.
2. Data Visualization: This covers the basics of creating visualizations using Databricks notebooks. This includes topics such as plotting data, creating charts, and using tools such as matplotlib.
3. Machine Learning: This covers the basics of machine learning using Spark MLlib. This includes topics such as supervised and unsupervised learning, model selection and evaluation, and hyperparameter tuning.
4. Advanced Analytics: This covers the basics of advanced analytics such as streaming data, anomaly detection, and natural language processing.
5. Big Data: This covers the basics of big data technologies such as Hadoop, Hive, and Kafka. This includes topics such as distributed
What are the Sample Questions of Databricks Databricks-Certified-Professional-Data-Scientist Exam?
1. What is the purpose of the Databricks Unified Data Science Platform?
2. Describe the benefits of using Apache Spark on Databricks.
3. Explain the architecture of the Databricks platform.
4. Describe the process for building and deploying a machine learning model on Databricks.
5. What is the best way to optimize a Spark job for performance?
6. How can you use Databricks to visualize data?
7. What are the key components of the Databricks security model?
8. Describe the different types of notebooks available in Databricks.
9. What are the advantages of using the Databricks Delta Lake feature?
10. Explain the process for debugging a Spark job on Databricks.
Databricks Certified Professional Data Scientist Exam Overview The data science space's gotten crowded. Everyone's got a certification these days. But here's the thing: when you're working with production ML at scale, companies want to know you can actually deliver on the Databricks platform, not just theorize about algorithms. The Databricks Certified Professional Data Scientist exam separates people who've read some tutorials from those who've actually built, deployed, and maintained machine learning systems that handle real enterprise workloads. This isn't your typical multiple-choice test where you memorize sklearn syntax and call it a day. The Databricks-Certified-Professional-Data-Scientist certification validates that you understand the entire ML lifecycle. From messy data ingestion through distributed feature engineering, experiment tracking with MLflow, hyperparameter optimization at scale, and eventually deploying models that won't fall over when traffic spikes or data... Read More
Databricks Certified Professional Data Scientist Exam Overview
The data science space's gotten crowded. Everyone's got a certification these days. But here's the thing: when you're working with production ML at scale, companies want to know you can actually deliver on the Databricks platform, not just theorize about algorithms. The Databricks Certified Professional Data Scientist exam separates people who've read some tutorials from those who've actually built, deployed, and maintained machine learning systems that handle real enterprise workloads.
This isn't your typical multiple-choice test where you memorize sklearn syntax and call it a day. The Databricks-Certified-Professional-Data-Scientist certification validates that you understand the entire ML lifecycle. From messy data ingestion through distributed feature engineering, experiment tracking with MLflow, hyperparameter optimization at scale, and eventually deploying models that won't fall over when traffic spikes or data distributions shift. It's designed for people who've been in the trenches.
What makes this credential actually matter
Look, Fortune 500 companies and major tech organizations have standardized on Databricks for their AI/ML initiatives. They're not just running Jupyter notebooks on someone's laptop anymore. They need production-grade infrastructure with proper governance, reproducibility, and cost controls. When you hold this certification, you're signaling that you understand how to work within the Databricks Machine Learning workspace, use Unity Catalog for data governance, implement proper MLOps practices, and scale workloads across distributed computing clusters without burning through the cloud budget.
The exam tests real architectural decisions. Should you use AutoML or build custom pipelines? When does Feature Store make sense versus ad-hoc feature engineering? How do you handle model drift detection in production?
These aren't theoretical questions. They're problems you'll face every week if you're doing this work professionally. Mixed feelings about some of the specifics, but overall? Solid validation of skills. I've seen people pass this thing and still struggle with basic deployment concepts, which tells you something about how much hands-on work really matters compared to test-taking ability.
Who actually needs this thing
Professional data scientists with a couple years of hands-on ML experience are the obvious candidates, especially if their organizations are already running Databricks or planning to migrate. Machine learning engineers get the most immediate value because they're the ones responsible for MLOps deployment and monitoring in production environments. If you're the person who gets paged at 2 AM when a model starts making garbage predictions, this certification teaches you how to prevent that scenario. Trust me on that one.
Senior analytics professionals trying to level up into advanced ML roles benefit too. Data engineers who want to expand beyond ETL pipelines into the model lifecycle find it opens doors. AI/ML architects designing enterprise infrastructure need this to understand platform capabilities and limitations. Technical leads managing data science teams use it to establish best practices and ensure their team isn't reinventing wheels or creating technical debt.
Consultants and solution architects implementing Databricks for clients obviously need platform-specific expertise. Career changers with strong ML foundations but limited distributed computing experience find it bridges that gap. And if you've already got the Databricks Certified Data Engineer Associate or similar credentials, this is a natural progression into the ML side of the platform.
The 2026 exam reflects actual platform evolution
Databricks doesn't stay static. The current exam version incorporates updates from recent Databricks Runtime releases, MLflow enhancements that improve experiment tracking and model versioning, and Unity Catalog integration for proper data governance and access controls. You need to understand how these pieces fit together in modern workflows, not just what worked two years ago.
Model serving infrastructure's evolved significantly. The exam covers real-time inference endpoints, batch scoring patterns, and the operational considerations around scaling predictions. It tests your knowledge of cost optimization strategies because spinning up massive clusters for every experiment is a great way to make your finance team hate you.
How the exam actually tests you
This isn't purely theoretical knowledge. Sure, you need to understand machine learning concepts, but the exam focuses on practical application within the Databricks ecosystem. You'll face scenarios where you need to choose the right approach for distributed data processing, implement Spark ML and feature engineering pipelines that actually scale, and make architectural decisions about model deployment strategies.
The questions test both your ability to write code that works and your judgment about when to use specific tools. You might need to identify performance bottlenecks in a training pipeline, debug issues with experiment tracking, or recommend monitoring strategies for production models. The kind of stuff that separates people who've actually shipped ML systems from those who've only worked on toy datasets.
It's not glamorous work, but it matters.
Coverage spans the entire ML lifecycle
Advanced proficiency in building end-to-end machine learning solutions means you're comfortable with every stage. Data preparation and feature engineering on distributed datasets using Spark. Training models with frameworks that use cluster computing, not just running scikit-learn on a single node. Tracking experiments and ensuring reproducibility using the MLflow model lifecycle on Databricks so your team can actually figure out what worked six months from now.
Hyperparameter tuning and model evaluation at scale requires different approaches than local development. You need to understand:
- Distributed hyperparameter search patterns
- Cross-validation strategies that don't bring your cluster to its knees
- Evaluation metrics that actually matter for your business problem (not just accuracy, please)
- Model Registry for version control and Feature Store for consistency
- AutoML for rapid prototyping when timelines are tight
The deployment and monitoring sections are where a lot of people struggle because they've never had to maintain production ML systems before. You need to know CI/CD patterns for ML workflows, automated retraining strategies, model drift detection approaches, and how to set up proper alerting when models degrade. This is the stuff that actually matters in production but gets glossed over in most ML courses.
The exam structure and logistics
The Databricks Professional Data Scientist exam cost runs around $200, which is pretty standard for professional-level certifications in this space. You'll schedule through the Databricks certification portal and take it online through a proctored environment or at a testing center if you prefer. The format's multiple-choice and scenario-based questions that test both knowledge recall and applied problem-solving.
Passing score and what it takes
The Databricks Professional Data Scientist passing score is 70%, meaning you need to get roughly 7 out of every 10 questions correct. Sounds generous until you're actually sitting there trying to remember the details of model serving configurations or distributed training patterns. The exam doesn't publish exact question counts publicly, but expect to spend 90-120 minutes working through scenarios that require you to actually think, not just pattern-match answers.
You'll get your score report immediately. Pass and you get your digital badge and certificate. Fail and you'll see which domains you struggled with, which is valuable feedback for what to study before your retake. The retake policy allows you to attempt the exam again after a waiting period, usually 14 days, but you'll pay the full exam fee again. Save yourself the money and stress by preparing properly the first time.
Prerequisites and what you should know first
There are no formal Databricks Professional Data Scientist prerequisites in terms of required certifications, but let's be real. You're setting yourself up for failure if you walk in without solid foundations. Databricks recommends at least two years of hands-on machine learning experience, and that's the minimum. You should be comfortable with Python for data science, understand Spark fundamentals, and have practical experience with core ML concepts like model selection, overfitting, bias-variance tradeoff, and evaluation metrics.
Experience with the Databricks platform itself? Basically required. If you've never worked in the workspace, used notebooks for collaborative development, or run jobs on clusters, you're going to struggle with platform-specific questions. Some people start with the Databricks Certified Machine Learning Professional or even the Databricks Certified Data Engineer Professional to build platform familiarity first.
Difficulty level and common challenges
This is an advanced certification. Not beginner-friendly whatsoever. People who've passed it generally rate the difficulty as moderate to hard, depending on their background. If you've been doing production ML on Databricks for a year, it's challenging but manageable. If you're new to the platform or haven't dealt with MLOps practices? It's really difficult.
Common stumbling blocks include the distributed computing aspects, MLflow model lifecycle details, and production deployment scenarios. These are interconnected, so weakness in one area cascades into others. Time management can be tricky because scenario-based questions require you to read carefully and consider multiple factors. Some questions have multiple plausible answers, and you need platform-specific knowledge to pick the best one.
Study materials that actually help
Databricks Professional Data Scientist study materials start with the official Databricks learning paths and documentation. The platform documentation's surprisingly good. it's API references but includes architectural guidance and best practices. Work through the official training modules on the Databricks Academy, particularly anything covering MLflow, Feature Store, Model Registry, and AutoML.
Hands-on labs matter more than reading. Period. Build actual projects that implement the full ML lifecycle. Take a dataset, do distributed feature engineering with Spark, train multiple models, track experiments with MLflow, register the best model, deploy it to a serving endpoint, and implement monitoring. Do this a few times with different use cases and you'll internalize the patterns.
The Databricks Professional Data Scientist exam objectives published by Databricks should guide your studying. Map your knowledge against each objective and identify gaps honestly. Focus on areas where you lack practical experience. For most people that's deployment and monitoring rather than model training, which is kind of ironic given that's what everyone learns first.
Practice tests and prep strategy
Databricks Professional Data Scientist practice test options are somewhat limited compared to AWS or Azure certifications. Databricks offers some sample questions, which you should definitely use to understand question style and difficulty. Third-party practice exams exist but verify they're current for the 2026 exam version since platform features change.
A realistic study plan for someone with relevant experience? Three to four weeks of focused preparation, maybe 8-10 hours per week. Week one, review objectives and identify weak areas. Week two and three, deep-dive those areas with hands-on practice and documentation. Week four, practice tests and final review. If you're newer to the platform or ML in general, extend that to 6-8 weeks.
Final week checklist: review MLflow tracking and model registry workflows, practice distributed training patterns, understand deployment options and their tradeoffs, review monitoring and drift detection approaches, and memorize key Databricks-specific tools and when to use them.
Renewal and staying current
The Databricks Professional Data Scientist renewal policy requires recertification every two years. You'll need to pass the current exam version to renew, which means staying updated on platform changes. Databricks releases new features regularly. MLflow improvements, Unity Catalog enhancements, new model serving capabilities. The exam evolves to reflect these updates.
The two-year renewal makes sense because the platform changes enough that skills from 2024 might not fully apply in 2026. Stay engaged with Databricks blogs, release notes, and community forums. Experiment with new features as they drop. If you're using Databricks professionally, this happens naturally. If you're not actively working with it, maintaining certification requires intentional effort.
Career impact and market value
Organizations hiring for senior data science roles increasingly list Databricks experience as required, not preferred. The certification validates platform expertise in a way that's hard to fake on a resume. It demonstrates you understand not just ML theory but production implementation on a specific platform that happens to be gaining massive market share.
The certification complements general data science qualifications nicely. You might have a master's degree or other ML certifications, but this proves platform-specific capability. That's what hiring managers actually care about when they need someone productive immediately. For career advancement, it's particularly valuable when moving into ML engineering, MLOps, or technical lead roles where you need to establish standards and make architectural decisions.
This exam isn't easy, but it's testing skills that actually matter if you're building production ML systems on Databricks. That's worth something real.
Exam Format, Cost, and Registration
Exam cost
"How much does the Databricks Certified Professional Data Scientist exam cost?" comes up constantly. People on my team ask about the Databricks-Certified-Professional-Data-Scientist certification, and honestly, the answer looks simple at first.
As of 2026, the Databricks Professional Data Scientist exam cost is $200 USD. That's list price. Databricks applies regional pricing variations depending on where you're buying from and what tax rules kick in, so don't be shocked if your checkout total differs from your US coworker's. Currency conversion fees sneak in if your card bills in something other than USD. Annoying, but normal.
Here's what that $200 actually buys: one attempt at the Databricks Certified Professional Data Scientist exam, delivered mostly via remote proctoring through Kryterion in 2026, plus the score report you'll use to decide whether you're celebrating or rage-booking a retake.
Additional costs? Real.
Not optional for most people.
- Databricks Professional Data Scientist study materials: you can use docs for free, but many folks end up paying for an official course, a third-party class, or both.
- Databricks Professional Data Scientist practice test: if you buy decent practice questions, budget for it. Some are worth it. Some are garbage.
- Hands-on lab environment: you might need a Databricks workspace, cloud spend for clusters, and time to actually run MLflow model lifecycle on Databricks, Spark ML and feature engineering, and MLOps deployment and monitoring workflows. That's not always free.
Now, compared to other professional-level certs, $200 is.. honestly reasonable. AWS Certified Machine Learning Specialty typically costs more (and AWS adds its own ecosystem tax because you end up paying for services while practicing). Google Professional Machine Learning Engineer? Also priced higher in many regions. Databricks is basically saying "prove you can do applied ML on our platform" without charging you the premium you see from the hyperscalers.
The value proposition is where it gets spicy. If this cert helps you land a data scientist role that's actually Databricks-heavy, or helps you move from analyst into ML engineering adjacent work, the salary bump can dwarf the exam fee fast. But if you're not in a Databricks Machine Learning workspace day-to-day, $200 can turn into $200 plus weeks of context switching. That's the real cost.
Employer reimbursement? Common. And you should push for it. Ask your manager for professional development funding, show how the Databricks Professional Data Scientist exam objectives line up with team deliverables, and mention that the certification makes the org look good with partners and customers. That argument works more often than it should.
Scheduling and delivery options
Remote proctored delivery is the default for 2026, done through Kryterion. Look, remote proctoring is convenient, but it's also picky. You'll want to schedule when your home internet is stable and your environment is quiet, not when your neighbor decides to remodel their kitchen.
Scheduling flexibility? One of the better parts here. Kryterion scheduling is generally 24/7, and appointments are often available within a few days. International candidates usually have no problem finding a slot, because the proctor pool is global and the platform's built for cross-time-zone delivery. Time zones matter more than people admit, though. Book at a time you're sharp, not just when it's open, because a two-hour exam at your personal "brain fog o'clock" is self-sabotage.
If you're trying to optimize performance, pick a time when your house is quiet, your caffeine plan is predictable, and you're not coming off back-to-back meetings. Lots of folks schedule for late evening because it's "free time," then they spend the first 20 minutes fighting the check-in process while tired. Don't do that to yourself.
I learned this the hard way on a different cert years back. Scheduled for 9 PM because "I'll have the whole day to prep." Wrong. What I had was eight hours of thinking about the exam while trying to focus on actual work, then sitting down exhausted with cortisol already spiked. Passed, but barely. Stupid move.
On delivery method, expect a classic proctored exam experience: timed, locked-down, monitored. The questions are typically multiple choice and multiple select, with scenario-style prompts that test applied judgment (not trivia), and the clock's always louder than you want it to be. Duration can vary by program updates, so confirm the current time limit in the portal before you book, but plan your day like it's a serious sit-down exam. Because it is.
Administrative requirements? Basic but strict. Real ID, matching name, clean testing environment. No wiggle room.
Registration step-by-step (Databricks portal + Kryterion)
Registration is a two-system dance. Databricks for the certification storefront and eligibility, Kryterion for the actual appointment booking and exam delivery. It's not hard, but it's easy to mess up your profile details and then pay for it later.
1) Go to the official Databricks certification portal Create or sign into your Databricks certification account. Use the email you want associated with your credential long-term, not the one you're about to lose when you change jobs. Small decision. Big future annoyance if you get it wrong.
2) Find the correct exam listing Select the Databricks Certified Professional Data Scientist exam. Double-check you didn't click an associate exam by accident. People do this constantly. Then they panic.
3) Confirm your personal details Make sure your first name, last name, and any middle name match your government ID exactly. Not close. Exactly. If your ID says "Alexandra M Smith" and your profile says "Alex Smith," you might end up in a last-minute support chat instead of taking the exam.
4) Pay the fee or apply a voucher You can usually pay by credit card. Some orgs use purchase orders, training credits, or internal training agreements, but the exact options depend on how your company buys from Databricks. If you've got a corporate voucher, apply it here. Keep the voucher email and code handy, because people lose these constantly.
5) Redirect to Kryterion for scheduling After purchase or authorization, you'll be pushed into Kryterion to schedule. If you don't already have a Kryterion account, you'll create one. Again, your name must match. Yes, I'm repeating it because that's the number one preventable exam-day failure.
6) Choose remote proctoring and pick your slot Select the online proctored option, pick your date and time, confirm your time zone, and book. Screenshot the confirmation page and keep the email. Kryterion emails are famous for ending up in spam.
7) Run the system check early Do the compatibility test at least a day before. Then do it again the day of. Different Wi-Fi. Different laptop updates. Same heartbreak.
Remote proctoring, security, and what they watch
Remote proctoring is basically "you're taking the exam, but someone's watching and the software's watching too." Expect webcam monitoring, microphone monitoring, and a locked-down testing experience that blocks screen sharing tools and may require closing background apps. The proctor may ask you to rotate your webcam to show your desk and room. Clean desk policy? Real. If you've got notes, extra monitors, or a phone within reach, assume you'll be asked to remove it.
Security measures are there to protect exam integrity, and yeah, they can feel intense. Identity verification, environment scan, restrictions on breaks, and monitoring for suspicious behavior. If your eyes keep darting off-screen because you're thinking, the proctor might still flag it. So set up your space so your natural "thinking stare" stays on-screen.
Technical requirements for remote exams
This is where people get burned. Not by content. By setup.
You'll generally need a supported Windows or macOS computer, a working webcam, a microphone, and a stable internet connection. Wired's safer than Wi-Fi. Corporate laptops can be a problem if your IT policy blocks the secure browser or proctoring tools, so test on the exact machine you'll use. Early.
Browser and system requirements can change, so follow Kryterion's current checklist, but the practical rule is: keep your OS updated, disable VPNs unless explicitly allowed, close all apps you don't need, and don't try to run the exam on a flaky setup. If your webcam's "usually fine," that's not fine.
Check-in process and exam day expectations
Plan to arrive 15 minutes early for check-in. Sometimes it's smooth. Sometimes there's a queue. If you show up right at start time and the proctor's delayed, your stress spikes before question one even loads.
During check-in you'll typically:
- Verify identity with an accepted government ID (passport or driver's license, depending on region)
- Complete a system check
- Do a room scan and desk scan
- Confirm exam rules, including prohibited items
Prohibited items usually include phones, notes, smartwatches, extra monitors, and anything that looks like it could store info. Water's sometimes allowed, sometimes not, depending on policy. Don't argue with the proctor. It won't end well.
Once the exam starts, treat it like a sprint with pacing. The question style's often scenario-based, like "given this pipeline and these constraints, what's the best next step," and it can touch topics like hyperparameter tuning and model evaluation, Spark ML and feature engineering, MLflow model lifecycle on Databricks, and MLOps deployment and monitoring. The content's technical, but the execution's administrative. Pass both parts.
Discounts, vouchers, and enterprise buying options
If you're paying out of pocket, you should still check for discounts. Databricks sometimes runs promotional pricing around Databricks events, partner programs, or training course bundles. Training packages can include exam attempts, or offer reduced pricing when you buy learning plus the exam together. Not always, but often enough that it's worth looking before you click "pay."
For companies, there are typically corporate voucher programs, bulk pricing, and corporate training agreements where an enterprise team buys a block of exams or a training bundle. If you're in a big org, ask your enablement team, your Databricks account rep, or whoever owns the learning budget. Volume licensing options exist, but they aren't always advertised loudly.
Payment methods vary by channel. Individuals usually pay via credit card. Enterprises might pay via invoice, purchase order, or training credits depending on their agreement.
Refund policies also vary, so read the current terms at checkout. In general, assume refunds are limited and tied to cancellation windows, no-shows, or technical failures that are clearly on the vendor side. If your internet dies, that can get messy. Document everything if there's a disruption.
Retake policy (and how to not waste money)
Retakes are straightforward and kind of brutal.
You pay the full exam fee each time. No discounted retakes. No "second try half off." So if you fail twice, you're at $400 plus time, and that's before counting any paid training.
Waiting periods matter:
- 14 days between the first and second attempt
- 30 days after the second failed attempt for subsequent attempts
If there's a lifetime attempt limit, Databricks may specify it in the current candidate handbook, and you should check that before you treat retakes like a subscription. Policies change. Don't rely on old Reddit posts.
Use the waiting period like a professional. Pull your score report, map weak areas back to the Databricks Professional Data Scientist exam objectives, and do targeted practice in a real environment. Build small projects that force you to touch the stuff you avoided, like experiment tracking in MLflow, distributed model training patterns, and monitoring concepts that show up in MLOps questions. Do that, and your next attempt isn't just "hope harder."
Sometimes the right move? Not to retake immediately. If you haven't actually worked with Databricks workflows beyond notebooks, you might need more hands-on time before another $200 attempt makes sense. Pride scheduling's expensive.
Accessibility accommodations
Accommodations are available for candidates with special testing requirements, but you've got to request them through the official process, typically before scheduling or at least well before exam day. Extra time, assistive technology allowances, or other adjustments may be possible depending on documented needs and the delivery method. Start early, because approval can take time, and you don't want to be stuck rescheduling because your accommodation wasn't applied to the appointment.
That's the practical truth of this exam: content matters, sure, but logistics can still fail you if you treat registration, setup, and scheduling like afterthoughts.
Passing Score and Scoring Details
What you actually need to know about passing
Okay, here's the deal. The Databricks Certified Professional Data Scientist exam doesn't publish an exact passing score on their website, and honestly that drives a lot of people crazy. But here's what I can tell you from working with candidates and digging into how these programs work: you're looking at roughly 70% as your target. This fits with the industry-standard passing score threshold for professional-level certifications, and Databricks follows similar psychometric principles to other major cloud and data platform vendors.
It's not simple math.
The thing is, Databricks uses scaled scoring. Your raw score (the actual number of questions you answered correctly) gets converted through a statistical model that accounts for question difficulty variations. Not all exam questions are created equal. Some test basic recall while others require you to troubleshoot complex MLflow experiment tracking scenarios or optimize distributed hyperparameter tuning across a Spark cluster.
How scaled scoring actually works behind the scenes
Scaled scoring exists because Databricks maintains multiple versions of the exam at any given time. They need someone taking version A in January to have the same difficulty experience as someone taking version B in March. Without this adjustment, you could get an easier set of questions just by luck, which wouldn't be fair to other candidates.
Item response theory matters. Each question has a difficulty rating based on historical performance data from thousands of previous test-takers. Harder questions contribute more to your scaled score when answered correctly. Easier questions still count, but they don't move the needle as much.
What this means in practice is that you might answer 72% of questions correctly and pass, or answer 69% correctly and still pass if you nailed the harder questions. On the flip side, someone could get 71% right but fail if they only got the easy stuff correct and bombed the advanced MLOps deployment and monitoring scenarios. Not gonna lie, this can feel arbitrary when you're staring at a "did not pass" screen. But the statistical validation behind these exams is actually pretty solid.
Why Databricks won't just tell you the magic number
Certification vendors keep exact passing scores confidential for a few reasons. First, it prevents people from gaming the system by aiming for the bare minimum. If you knew it was exactly 68%, you might study just enough to scrape by rather than actually developing professional skills in Spark ML and feature engineering.
The threshold shifts slightly. The passing score can move between exam versions as the psychometric analysis gets refined. What counts as "passing" is determined by subject matter expert panels who review questions and establish cut scores based on what a minimally competent professional data scientist working with Databricks should know. They're not just pulling numbers out of thin air. They conduct job task analyses and gather input from hiring managers about what skills actually matter in production environments.
Third, and this is the part nobody likes to hear, keeping the exact threshold vague forces you to prepare more thoroughly. I mean, the difference between minimal competency and actual mastery is huge when you're implementing model evaluation pipelines or managing the MLflow model lifecycle on Databricks in a real job. I've seen people pass and still struggle on day one because they studied for the test instead of understanding the platform.
Comparing difficulty with other Databricks certifications
The Databricks Professional Data Scientist passing score requirements are definitely steeper than what you'd see with the Databricks Certified Data Analyst Associate exam. Associate-level certs typically have more straightforward questions and might have slightly lower cut scores in the 65-70% range. At the professional level, you're expected to handle multi-step problem-solving scenarios that don't have obvious answers.
Professional exams hit harder. If you've taken the Databricks Certified Data Engineer Associate or moved up to the Databricks Certified Data Engineer Professional, you'll notice the professional exams share a similar difficulty profile. They're testing whether you can actually build solutions and troubleshoot problems, not just recite documentation.
The Databricks Machine Learning Professional certification has some overlap with this data scientist exam, but focuses more on production ML systems. The data scientist cert puts more weight on experimentation, model development, and statistical validation techniques. Pass rates for well-prepared candidates with relevant hands-on experience typically fall in the 60-75% range across these professional certifications.
Understanding what's actually being measured
The exam isn't trying to trick you. Really. It's designed to measure whether you can perform job tasks that professional data scientists actually do on the Databricks platform. Can you prepare data and engineer features at scale? Can you train models using distributed ML libraries? Do you know how to track experiments properly with MLflow? Can you evaluate model performance, tune hyperparameters efficiently, and deploy models following MLOps best practices?
Pretest items exist everywhere. The questions that appear on your exam but don't count toward your score are pretest items. Databricks includes these experimental questions to gather statistical data for future exam versions. You won't know which ones they are, which is why you need to treat every question seriously. These unscored questions don't affect your pass/fail outcome, but they help the testing program validate new content before it goes live.
Scoring mechanics and what happens when you click submit
When you finish the exam, the scoring happens immediately through an automated process. Each question is marked correct or incorrect. There's no partial credit for getting "close" on a multiple-choice question. The system tallies your raw score, applies the scaled scoring algorithm specific to your exam version, and determines whether you met the passing threshold.
Results come fast. Most candidates see provisional results on-screen within seconds of completing the exam. You'll know right away whether you passed or failed. The official score report arrives within five business days via email and through your certification portal. This report breaks down your performance by domain area: data preparation and feature engineering, model training, experiment tracking, model evaluation and tuning, deployment and monitoring, performance optimization.
The domain-level feedback is actually useful, especially if you need to retake the exam. You won't see which specific questions you missed (that would compromise exam security), but you'll get percentage ranges showing whether you were "above target," "near target," or "below target" in each knowledge area. This helps you focus your retake preparation on actual weak spots rather than just reviewing everything again.
What to actually aim for when preparing
Don't aim for 70%. Aim higher. Target 85%+ on practice tests and study materials before you schedule the real thing. Why? Because the practice questions you'll find, even in quality resources like the Databricks-Certified-Professional-Data-Scientist Practice Exam Questions Pack at $36.99, might not perfectly match the difficulty distribution of the actual exam.
Buffers save you. Exam anxiety is real. Time pressure affects performance, and you might encounter question formats or scenarios you didn't expect. If you're consistently scoring 75% on practice tests, you're probably not ready. If you're hitting 90%+, you've got a solid shot at passing comfortably.
The relationship between preparation quality and passing probability isn't linear, it's exponential. Someone who does 20 hours of hands-on labs and thoroughly understands MLflow experiment tracking will perform dramatically better than someone who does 50 hours of passive reading. Working through realistic scenarios where you actually build end-to-end ML pipelines on Databricks gives you pattern recognition that no amount of flashcard memorization can replicate.
Score report details and what comes next
Your official score report includes your pass/fail status right at the top. No ambiguity there. Below that you'll see your performance across the major exam domains. Databricks doesn't provide a numerical score, just domain-level indicators and the binary pass/fail decision.
Badge arrives soon. If you passed, you'll receive your digital badge within a few days. The certificate comes as a downloadable PDF, and you get a verification URL you can share on LinkedIn or with employers. The certification portal maintains your historical records, so you can always access proof of your credentials even years later.
If you didn't pass, the score report becomes your study guide for round two. Focus on the domains where you scored "below target" and dig deeper into those topics. The retake policy allows you to test again after a waiting period, typically 14 days, and you'll need to pay the full exam cost again.
The passing score might seem like a mystery, but the actual standard is consistent with professional-level technical certifications across the industry. Prepare thoroughly, get hands-on experience with the Databricks Machine Learning workspace, and aim significantly above the minimum threshold. The scoring methodology is fair, even if it feels opaque from the outside.
Exam Objectives (Skills Measured)
The Databricks Certified Professional Data Scientist exam is basically Databricks saying, "cool, you can build models, but can you build models that survive contact with production, other teams, and messy data." That's the energy here. Not academic Kaggle stuff. Not toy datasets. Real pipelines, real governance, real tradeoffs.
You'll see the Databricks Professional Data Scientist exam objectives broken into domains mirroring how work actually happens inside the Databricks Machine Learning workspace: ingest, explore, engineer features, train at scale, track everything, evaluate like an adult, then ship and monitor without breaking the business. Short version? End-to-end ML lifecycle competency. Full stop.
The other thing: these objectives test both "do you know what this is" and "can you do it on Databricks." Conceptual plus hands-on implementation skills, even if the exam format's multiple choice. The questions are written like case studies for a reason.
How the objectives are weighted and how to prioritize
Databricks doesn't always publish fixed percentages the way some vendors do, but the exam clearly behaves like a weighted blueprint. Look, you can feel it when you take enough practice questions. I mean, the gravitational pull toward certain topics becomes obvious pretty fast. Expect the biggest gravity wells to be feature engineering, training, MLflow, and MLOps.
My practical weighting mental model goes like this:
- Deployment, MLOps, monitoring, governance: heavy and sneaky, because the questions are scenario-based and include Unity Catalog, Model Registry stages, serving choices, and drift
- Feature engineering and data prep: also heavy, because Spark ML and feature engineering's where Databricks wants you living day to day
- MLflow lifecycle: constant background radiation across everything. If you don't know tracking, registry, and reproducibility patterns, you bleed points
- Modeling and tuning: plenty of it, but it's framed as "what works at scale, what integrates cleanly, what avoids leakage," not "derive the gradient"
Study priority advice. Honestly? Start by building one end-to-end project that logs to MLflow, writes features to Feature Store, trains something distributed, registers a model, and serves it. Then go back and fill in gaps with docs and targeted drills.
If you start with isolated theory, you'll get wrecked by integration questions. I learned that one the expensive way on a different cert years back, spent three weeks memorizing API signatures only to face questions about "your pipeline just failed in prod at 2am, what's your move." Theory's fine but it doesn't teach you how things break.
Why the objectives match real workflows on Databricks
The exam objectives are basically a map of the modern Databricks workflow: data comes in from everywhere, lands in Delta, gets cleaned and versioned, features get computed and shared, models get trained with either Spark MLlib or external frameworks, everything gets tracked in MLflow, and then you deploy through registry and serving with monitoring and governance.
And yes, the 2026 flavor of this exam reflects how Databricks has been moving: more emphasis on governed assets via Unity Catalog, more "production-ready" language, more expectation that you know how Databricks Model Serving and MLflow Registry fit together, and more attention to performance and cost on clusters because nobody wants a $4,000 training job that could've been $400.
Data preparation and feature engineering on Databricks
This domain's where the exam gets very Databricks-specific, and also very real-world. You're expected to be fluent in ingestion patterns and then in turning raw data into stable, reusable, testable features.
Ingestion shows up as "can you bring data in from diverse sources." Cloud object storage. Databases via JDBC. Streaming platforms like Kafka. APIs. You should know when you'd use Auto Loader versus a one-time batch read, how structured streaming changes your thinking, and how Delta Lake fits as the landing zone so downstream transformations are reliable.
EDA's included too, and it's "print schema." Expect notebook-driven workflows with matplotlib, seaborn, plotly. Quick distribution checks. Null profiling. Correlation and leakage sniff tests. Visual sanity checks. Small fragments, big impact.
Feature engineering's the meat:
- Handling missing data, outliers, and data quality issues in production datasets. Not just "dropna," I mean think imputation strategies, winsorization, rule-based filters, and what you log for later debugging
- Encoding categorical variables: one-hot encoding, target encoding, embeddings. When one-hot explodes cardinality. When target encoding risks leakage. When embeddings make sense for deep models
- Time-series feature engineering: lag features, rolling statistics, temporal aggregations. Plus the big rule: don't leak future information. Ever
- Scaling and transformations: normalization, standardization, log transforms, power transforms, and why some algorithms care more than others
Feature Store's explicitly in scope. Creating, versioning, sharing. You should understand how features get computed, stored, and served consistently for training and inference, and why lineage matters when a downstream model suddenly degrades and you need to answer "what changed." That ties into data versioning and lineage tracking for reproducible feature engineering pipelines, which isn't optional anymore in regulated or high-stakes environments.
Also: performance optimization for large-scale feature computation using Spark DataFrames and Delta Lake. This is where you need opinions. Don't do Python UDFs when built-in functions exist. Partition intelligently. Cache when it actually helps. Use Delta optimization patterns when the table's getting hammered.
Imbalanced data gets tested too. Sampling techniques, class weights, SMOTE and synthetic generation. And then you need to connect it back to evaluation metrics, because accuracy's a lie when 99.5% of your labels are negative.
Feature selection methods show up in multiple forms: statistical tests, recursive feature elimination, and embedded methods like L1 regularization or tree-based importance. Custom transformers and pipelines matter because Databricks expects you to create repeatable workflows, not ad hoc notebook cells that nobody can rerun.
Model training with Spark ML / distributed ML
This domain's about picking the right training approach and using cluster resources without lighting money on fire. Expect Spark MLlib algorithms across classification, regression, clustering, and recommendation systems. You should know the standard pipeline components, how estimators and transformers work, and how distributed training affects runtime and memory.
Single-node scikit-learn's still on the table for smaller datasets, and the exam loves asking "should this be Spark ML or sklearn" based on data size, algorithm availability, and iteration speed. Quick note: this matters.
Deep learning integration's included: TensorFlow, PyTorch, Keras on Databricks. You're expected to understand how to run training jobs on GPU clusters, how artifacts get logged, and where distributed deep learning fits. Horovod's specifically called out, so know what it does, when to use it, and what changes in your training script.
Ensembles are fair game: random forests, gradient boosting, plus popular libraries like XGBoost, LightGBM, CatBoost. Transfer learning and fine-tuning pre-trained models show up as "can you adapt a model for a domain-specific use case," not as a math quiz.
Also included: incremental and online learning for streaming data, plus federated learning concepts and privacy-preserving ML techniques. Those tend to be lighter touch, more conceptual, but you should know what problem they solve and why they're hard.
Training best practices are everywhere: cross-validation, stratified sampling, reproducibility, proper splits. Serialization and large model artifacts matter too, because in real platforms you hit limits fast if you treat artifacts like an afterthought. Caching, persistence, checkpointing. Memory management and resource allocation. This is the "professional" part.
Experiment tracking and reproducibility (MLflow)
The exam expects thorough expertise in the MLflow model lifecycle on Databricks. Tracking. Registry. Projects. Models. Flavors. Autologging. The whole thing.
You need to know how to log parameters, metrics, artifacts, and model versions, and also how to organize experiments using nested runs, tags, and searchable metadata because real teams don't have one run. They've got 400. MLflow UI literacy matters. Programmatic APIs matter too.
MLflow Projects gets tested as reproducibility packaging: dependencies, entry points, rerunning the same code elsewhere. MLflow Models format's about standard serialization and deployment compatibility across frameworks, and custom flavors exist for weird models and custom inference logic.
Artifact storage strategy matters more than people think. Where artifacts go. How they're retained. How they tie into cloud storage. And yeah, CI/CD integration's part of this domain: automated training pipelines that log, validate, and promote models with minimal human clicking.
Collaboration and access control show up too, including sharing experiments and migrating between workspaces or environments. This is where Databricks wants you to think like a team, not a solo notebook wizard.
Model evaluation, tuning, and validation
Hyperparameter tuning and model evaluation's a core objective, and it's framed as "pick the right strategy for the workload." Grid search. Random search. Bayesian optimization with Hyperopt. Databricks AutoML and its MLflow integration.
Metrics selection's heavily tested. Accuracy, precision, recall, F1, AUC-ROC for classification. RMSE, MAE, R-squared for regression. And domain-specific metrics, because fraud and ads and forecasting all grade differently.
Cross-validation strategy's a common trap: k-fold, stratified k-fold, time-series split, group-based validation. Time-series leakage prevention's huge. Group leakage too, like customer-level splits.
Interpretability's in scope: SHAP, LIME, permutation importance, partial dependence plots. You're not expected to reinvent them. You're expected to know when to use them and what they tell you. Overfitting diagnostics. Bias-variance tradeoff. Early stopping and regularization.
Production evaluation concepts appear: A/B testing frameworks, statistical significance, confidence intervals, and multi-objective optimization when you're balancing accuracy with latency and cost. Fairness metrics and bias detection also show up, usually in scenario form where you're asked what to measure and what to do next.
Deployment, MLOps, monitoring, and governance
This is where the exam fits with current industry practices in MLOps deployment and monitoring, and where a lot of people who "only trained models" get exposed. You need to know MLflow Model Registry deeply: versioning, stages, transitions, and lifecycle management patterns.
Deployment options matter. Batch inference. Real-time serving. Streaming inference. Databricks Model Serving for low-latency REST endpoints, including the operational concerns: auth, latency, scaling, and cost. Containerization with Docker shows up as the portability story, especially when you need consistent runtime behavior outside a notebook.
CI/CD comes back again here: automated testing, validation gates, deployment automation. Blue-green and canary releases are explicitly called out, so know the difference and why you'd pick one when you're trying not to break revenue.
Monitoring's not just "log metrics." You're expected to think about performance degradation, drift detection, alerting for failures and latency spikes, and data quality monitoring because garbage inputs kill models quietly. Retraining pipelines triggered by schedules or thresholds. Feedback loops. Impact analysis with lineage tracking.
Governance's increasingly a Databricks thing, especially with Unity Catalog: centralized access control, audit logs, and permissions around data and models. Add in security best practices like authentication, authorization, encryption, and vulnerability scanning. Compliance requirements like GDPR and CCPA show up as "what should you do" scenarios, usually involving explainability and documentation expectations.
Performance, scalability, and best practices
Finally, the exam expects you to think like someone who's paid a cloud bill. Cluster configuration. Autoscaling. Resource allocation. Memory. GPU choices. Tuning Spark jobs so feature computation and training don't crawl.
Delta Lake optimization's part of it too: compaction and Z-ordering are named, so know why they matter, when to do them, and what problem they solve for read performance.
This domain's also where integration between domains gets tested. One question might start as "feature pipeline's slow" and end with "model serving's timing out" because the exam wants end-to-end thinking, not isolated textbook answers.
What the scenario questions feel like
Expect practical scenarios and case-study questions where the "right" answer's the one matching Databricks-native patterns and general ML engineering best practices at the same time. Like, you'll get a prompt about streaming ingestion, then feature computation, then training, then registry promotion, then monitoring drift, all in one narrative.
That balance's the point. Databricks-specific features matter: Spark, Delta, Feature Store, MLflow, Unity Catalog, Model Serving. But the exam's also checking whether you understand general ML engineering hygiene. Reproducibility, leakage prevention, evaluation discipline, deployment safety, and operational monitoring.
If you've done production ML, the objectives will feel familiar. If you've only done notebooks, they'll feel.. the thing is, they'll feel personal.
Conclusion
Wrapping up your prep path
Okay, real talk.
The Databricks Certified Professional Data Scientist exam? You can't just waltz in after binge-studying Saturday night. We're talking validation of serious skills here: handling MLflow model lifecycle on Databricks, architecting feature engineering pipelines with Spark ML, deploying models that won't crash the second they hit production. The exam objectives throw everything at you. Hyperparameter tuning, model evaluation, MLOps deployment, monitoring across the entire Databricks Machine Learning workspace. All of it.
Sure, the Databricks Professional Data Scientist exam cost looks kinda steep upfront. But here's the thing. It's actually an investment that delivers when you're going after roles where these tools aren't optional, they're daily requirements. Knowing the Databricks Professional Data Scientist passing score gives you something concrete to aim for, but don't just scrape by the minimum threshold. Truly own this material since you'll be living in it anyway.
Landing your Databricks-Certified-Professional-Data-Scientist certification? Takes genuine preparation. The Databricks Professional Data Scientist prerequisites aren't meaningless hoops. You need actual hands-on experience, not textbook theory. Build real projects. Intentionally break stuff in the workspace (trust me on this one). Track experiments with MLflow until it becomes muscle memory.
Not gonna sugarcoat it.
The sheer variety of Databricks Professional Data Scientist study materials floating around gets overwhelming fast. Official docs are solid but, I mean, they're dense as hell. Tutorials definitely help but conveniently skip those annoying edge cases. What really moves the needle? Combining multiple resources together. Official learning paths, your own messy lab work, community forums where folks share what actually appeared on their exam.
I spent three days once trying to debug why my feature store kept throwing weird timestamp errors. Turned out my timezone assumptions were completely wrong. That kind of frustration teaches you more than any video course.
Your final push before exam day
Here's what nobody tells you about Databricks Professional Data Scientist practice test options. Quality varies wildly. Some throw softball questions that don't remotely match real complexity. Others hit you with scenarios mirroring what you'll legitimately face: distributed training headaches, model registry workflows, production monitoring decisions that don't have obvious answers.
The Databricks Professional Data Scientist renewal policy means you can't just pass once and coast forever. Platform updates drop constantly. MLOps best practices shift. Staying current isn't optional.
Before scheduling your exam, I'd honestly recommend checking out the Databricks-Certified-Professional-Data-Scientist Practice Exam Questions Pack at /databricks-dumps/databricks-certified-professional-data-scientist/. It's specifically designed to match actual exam format and difficulty, covering everything from Spark ML distributed training to MLflow experiment tracking to deployment scenarios you'll legitimately encounter in the Databricks Machine Learning workspace. Authentic exam prep means practicing with questions that challenge your actual understanding, not just quiz surface-level memorization.
You've got this.
Put in deliberate work, practice with intention, and that certification's yours.
Show less info
Comments
Hot Exams
Related Exams
Certificate of Cloud Security Knowledge (v5.0)
Microsoft Power BI Data Analyst
Avaya Workforce Optimization Select Implementation and Support Exam
HashiCorp Certified: Terraform Associate
VMware Carbon Black Portfolio Skills
Service Provider Routing and Switching, Specialist (JNCIS-SP)
Advanced Routing and Switching for Field Engineers – ARSFE
Avaya Aura Contact Center Administration
Nutanix Certified Systems Engineer (NCSE): Level 1
SAP Certified Technology Associate - SAP Fiori System Administration
Certified Scrum Master (CSM)
Microsoft Dynamics 365: Finance and Operations Apps Developer
Databricks Certified Professional Data Scientist Exam
Databricks Certified Data Analyst Associate Exam
Databricks Certified Data Engineer Associate Exam
Databricks Certified Data Engineer Professional Exam
How to Open Test Engine .dumpsarena Files
Use FREE DumpsArena Test Engine player to open .dumpsarena files

DumpsArena.co has a remarkable success record. We're confident of our products and provide a no hassle refund policy.

Your purchase with DumpsArena.co is safe and fast.
The DumpsArena.co website is protected by 256-bit SSL from Cloudflare, the leader in online security.