Databricks Databricks-Certified-Data-Engineer-Associate (Databricks Certified Data Engineer Associate Exam)
Databricks Certified Data Engineer Associate Exam Overview
The Databricks Certified Data Engineer Associate exam represents a foundational credential that validates your ability to build and maintain data pipelines on the Databricks Lakehouse platform. Real talk? If you're working with data at any scale, this certification proves you understand more than just theory. You can actually deploy production-grade ETL/ELT workflows using Delta Lake, Spark, and Databricks-specific tooling, which honestly separates you from folks who've only read documentation without getting their hands dirty in actual implementation. It's positioned as an entry point within Databricks' certification ecosystem, sitting below the Professional Data Engineer credential but demonstrating real hands-on competency.
What this certification actually validates
The Databricks Certified Data Engineer Associate exam tests practical skills across data ingestion, transformation pipelines, Delta Lake management, and orchestration using Databricks Workflows. You'll need to show you can ingest raw data from various sources (cloud storage, streaming, databases), transform it using PySpark or Spark SQL, optimize Delta tables with proper partitioning and Z-ordering, and monitor pipeline health.
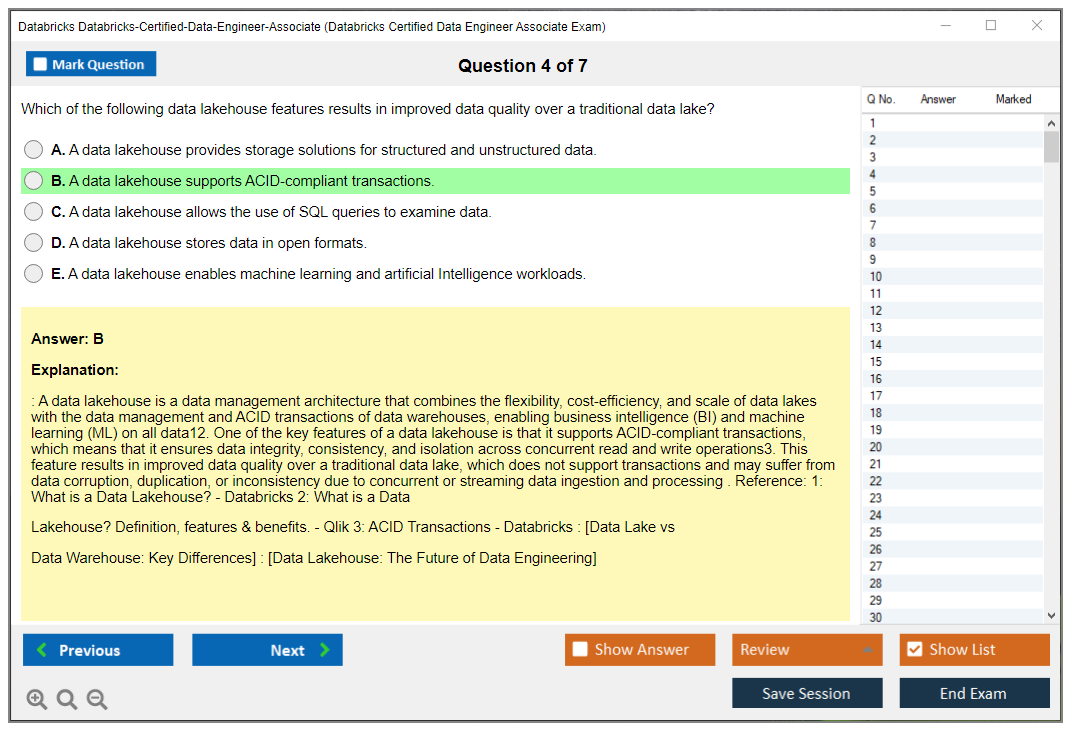
The exam focuses heavily on Delta Lake fundamentals. ACID transactions, time travel, schema enforcement. That's the backbone of the Lakehouse architecture. You also need basic understanding of governance concepts, though Unity Catalog questions aren't as deep as what you'd see in platform admin certifications.
This isn't just passing multiple-choice questions. The certification validates you can troubleshoot performance bottlenecks in Spark jobs, implement incremental processing patterns, and design pipelines that actually scale. Employers recognize this because Databricks skills directly translate to faster development cycles and lower infrastructure costs compared to traditional data warehouse approaches that honestly feel clunky once you've experienced Lakehouse workflows. I spent two weeks once trying to debug a legacy warehouse partition that kept timing out. With Delta Lake? Fixed the equivalent problem in about twenty minutes using time travel to isolate when the data corruption started.
Who should pursue this credential
Ideal candidates? Data engineers with 6-12 months of Databricks experience.
ETL developers transitioning from legacy tools like Informatica or SSIS benefit massively because cloud-native data engineering requires different thinking around distributed processing and storage optimization. Data analysts moving into engineering roles find this certification bridges the gap between SQL-heavy analytics work and full pipeline development. Software engineers specializing in data infrastructure also pursue this to formalize their platform knowledge.
The target audience extends beyond pure data engineers though. Solutions architects designing Lakehouse implementations use this as a baseline competency check. Platform teams adopting Databricks want their members certified to ensure consistent best practices across projects.
Industry recognition and job market relevance
Databricks certifications carry weight because the platform dominates modern data engineering stacks, particularly in enterprises already invested in AWS, Azure, or GCP. The thing is, this credential complements cloud-provider certifications rather than replacing them. Pairing the Databricks Data Engineer Associate certification with AWS Certified Data Analytics or Azure Data Engineer Associate creates a powerful combination that recruiters absolutely notice when scanning resumes for mid-level roles. Recruiters specifically search for Databricks skills in job postings for mid-level data engineering roles paying $95k-$140k depending on location and experience.
I've seen certified professionals report 10-15% salary increases after earning this credential, especially when negotiating offers or internal promotions. Not gonna lie, job mobility improves because Databricks expertise transfers across industries. Finance companies use it for risk analytics, healthcare organizations for patient data pipelines, retail for customer behavior modeling, tech companies for product analytics at scale.
Career advancement and specialization paths
This certification opens doors to specialization. Some engineers move toward the Machine Learning Professional track to build ML pipelines and feature engineering workflows. Others pursue the Professional Data Engineer exam for deeper architectural knowledge. Platform administration becomes an option through the Azure Databricks Platform Administrator certification if you're managing multi-workspace deployments.
Real-world applications span every industry. Financial services firms use Databricks for real-time fraud detection pipelines processing millions of transactions daily. Healthcare organizations aggregate clinical trial data from disparate sources into unified Delta Lake tables. Retail companies build customer 360 views combining online behavior, purchase history, and inventory data. The skills tested in this exam directly apply to these scenarios.
Why Lakehouse architecture matters
Understanding the Databricks Lakehouse architecture separates this certification from generic data engineering credentials. The Lakehouse combines data warehouse performance with data lake flexibility, using Delta Lake to provide ACID guarantees on object storage.
This matters because traditional architectures forced you to choose between analytical query performance and flexible schema-on-read processing, which honestly always felt like choosing between speed and flexibility when you really needed both. Databricks eliminates that tradeoff, and this exam makes sure you understand how to exploit that advantage through proper table design, maintenance operations, and query optimization.
The certification integrates Apache Spark fundamentals with Databricks-specific innovations. You need strong Spark SQL knowledge but also understand Databricks SQL endpoints, serverless compute, and photon acceleration. After certification, most professionals report improved job performance through better debugging skills and deeper platform understanding. Not just resume credibility.
Exam Format, Cost, and Key Policies
Exam cost (price, taxes, vouchers if applicable)
The Databricks Certified Data Engineer Associate exam runs you USD $200 per try. That's the baseline. What you'll see in the Databricks Academy checkout most of the time, and honestly, the number I'd tell anyone to plan for when budgeting for the Databricks Data Engineer Associate certification. Taxes get added depending on your location. VAT and GST are the usual suspects in tons of countries, and look, this is why people suddenly think the Databricks data engineering associate exam cost "jumped" when really it's just local tax nonsense kicking in.
Regional pricing exists. But it's not laid out nicely everywhere. Some candidates see the fee in local currency at checkout, and the final charge shifts a bit. Exchange rates, card processor conversion spreads, whether the system bills in USD first then flips it over. Your company reimbursing you? Keep that receipt showing original currency plus conversion breakdown, because finance departments love to nitpick that stuff.
Payment methods are standard fare. Credit cards and debit cards work easiest. Purchase orders might be available for organizations, though that usually hinges on how your company's tied into Databricks training programs, and you'll probably need your internal training coordinator handling it. Vouchers are common. Employers buy exam vouchers in bulk sometimes, and Databricks partner programs hand them out during enablement. Academic discounts appear through university partnerships, and every now and then Databricks runs promo windows around events or training pushes. Not always. Worth a look. If you're chasing discounts, I mean, don't burn hours refreshing pages, but definitely ask your Databricks account team, partner manager, or school contact if you've got one.
Voucher policies matter more than you'd think. They've got expiration dates and fixed validity windows, so don't let one go stale sitting in your inbox. Vouchers typically cover the exam fee but not always the local taxes, depending on transaction processing. I once watched a colleague lose a perfectly good voucher because he kept putting off scheduling "until he felt ready." Six months later it expired. Don't be that person.
Exam duration, question types, and delivery method
Format's straightforward enough. 45 questions, mostly multiple-choice and multiple-select, with a hard 90-minute clock. No lab. No coding environment. Just questions testing whether you can reason through Databricks Lakehouse data engineering skills, Delta Lake fundamentals for data engineers, and the kind of ETL pipelines in Databricks (PySpark/SQL) calls you'd make on the job.
Time management? That's where people fall apart. Ninety minutes for 45 questions is 2 minutes per question average. Some fly by. Others are traps. My take is to rip through a first pass quickly, flag anything eating more than 90 seconds, circle back later. Getting stuck early is how you end up panic-guessing five questions in the final two minutes.
Multiple-choice single-answer questions are what you'd expect. One correct option. Example vibe is "Which command optimizes a Delta table for query performance?" Multiple-select questions eat your time. They'll say "Select two" or "Select all that apply," and wrong answers are sneaky. Like a Spark behavior that's technically true but not in Databricks, or a Delta feature that exists but needs a specific config flag.
Delivery's usually online proctored through the Kryterion platform. Testing centers pop up in some regions. Online's the default for most folks. Testing centers can be clutch if your home setup's chaotic, but they're not always close, and scheduling gets tighter.
For online proctoring, expect standard tech requirements like a supported OS and browser, stable internet, working webcam, working mic. "Stable" connection means more than "my Wi-Fi seems fine." Signal drops or your VPN switching? You're getting booted. Run the pre-exam system check early, not five minutes before start time. Common headaches include corporate laptops with locked permissions, aggressive endpoint security blocking the secure browser, audio devices the system won't recognize, external monitors making the proctoring app freak out.
Check-in's strict. You'll show ID, scan your room, sometimes do a desk sweep. Proctors communicate via chat, sometimes voice. Just follow instructions. Don't push back. Quiet room. Clear desk. Good lighting. No second monitor. No phone "face down." The thing is, they don't care about your excuses. It still counts as prohibited.
Retake policy and scheduling details
Scheduling happens through the Databricks Academy portal. You pick the exam, pay or apply a voucher, then grab an available slot with Kryterion. The flow's not complicated. Few screens, that's it. Account login, exam selection, candidate info, payment, appointment booking. Save the confirmation email. Screenshot the appointment. Seriously.
Rescheduling's allowed, but there's a cutoff, usually 24 to 48 hours before your slot. Miss that window? You might forfeit the fee or catch a reschedule charge depending on booking terms. Cancellation and refunds follow similar time limits. Cancel early enough, you might get money back. No-show? Assume you're eating the cost. Medical emergencies and platform outages can be exceptions, but you'll need documentation and, honestly, patience.
Retakes have waiting periods. Typically 14 days after the first bomb, and 30 days after repeat fails. There might be a cap on attempts within a set window too, so if you're failing repeatedly, the system forces a longer cooldown. That's not Databricks being harsh. It's exam integrity.
Day-of, you'll need government-issued photo ID. Passport, driver's license, usual safe picks. Names gotta match exactly. No notes. No reference materials. No extra devices anywhere near you. Bathroom breaks during the 90 minutes? Generally not happening, and even if a proctor allows it in some weird case, it can flag a review. You'll sign an NDA too. Content's confidential. Sharing questions can torch your score, and yeah, people do get flagged for sketchy behavior like looking off-screen a bunch, running forbidden software, having someone else in the room.
If you're also stressing about the Databricks certified data engineer associate passing score, or how Databricks certification renewal data engineer associate works down the line, those are different policy chunks, but the big point here's simple. Follow the rules, because the fastest way to fail isn't the questions. It's getting your attempt tossed.
Passing Score and Scoring Details
Understanding the passing threshold
Okay, so here's the deal. The Databricks Certified Data Engineer Associate exam? You're gonna need roughly 70% to pass. That's about 32 right answers out of 45 total questions, though that exact number bounces around a bit depending on which exam version you get because Databricks does this whole psychometric scaling thing to keep difficulty consistent across different forms. One version might let you pass with 31 correct answers, another could demand 33, but they're targeting that 70% mark as the standard benchmark.
The scaled scoring system isn't random. Your raw score (literally just how many you nailed) gets converted into a scaled score that adjusts for question difficulty variations across different exam forms. Some versions pack in tougher questions than others, so the scaling tries to keep things fair. If you draw a harder version, you'll need fewer correct answers to hit that passing threshold versus someone who gets an easier form.
How questions are weighted and scored
Here's what matters.
Every question's worth the same on this exam. Doesn't matter if you're tackling a straightforward SQL query question or grinding through a brutal Delta Lake optimization scenario. Each one counts the same toward your final score. Multiple-choice questions with single answers work how you'd expect, but those multiple-select questions? All or nothing. You've gotta select every correct option and dodge every incorrect one to get credit. Miss one correct choice or accidentally include one wrong option, and boom. Zero points.
No penalty for guessing exists here, which honestly flips your strategy completely. Stuck on a question with 30 seconds remaining? Just pick something. Anything. An unanswered question guarantees zero points, but a guess at least gives you a shot at earning credit. I've watched candidates leave questions blank thinking it's the safer move, and that's literally throwing away potential points for no reason whatsoever.
My cousin took this exam last year and left eight questions blank because he "didn't want to hurt his score with wrong guesses." Eight questions. I still bring it up at family dinners because he failed by four points and refuses to admit the math on that one.
Getting your results and understanding the report
You'll see preliminary results right after finishing. The second you click that final submit button, the system tells you pass or fail. It's nerve-wracking but also kind of a relief not waiting days wondering how you did.
The official score report lands in your email within 24 to 48 hours typically. This report breaks down way more than just your overall scaled score and pass or fail status. It shows performance by domain. You'll see how you did across areas like data ingestion, Delta Lake operations, transformations with PySpark and Spark SQL, pipeline orchestration, and data quality monitoring. Each domain gets a performance indicator showing whether you're below, at, or above the target level.
Using score reports to improve
Don't pass on the first attempt? Those domain-level breakdowns become your roadmap. Maybe you crushed the Delta Lake fundamentals section but struggled hard with Databricks Workflows orchestration. That tells you exactly where to focus study time before retaking. The report won't give you question-by-question feedback or show specific items you missed, but the domain analysis is detailed enough to guide targeted preparation efforts.
Your exam results stay accessible in the Databricks Academy portal forever, basically. Years later, you can still log in and review your certification history, which matters when you're tracking professional development or preparing for the Databricks Certified Data Engineer Professional exam as your next step.
Digital credentials and verification
Pass the exam?
You'll receive a digital badge through Credly within a few days. Badge issuance is usually automatic but can take up to a week sometimes. You can download your certificate directly from the Databricks Academy portal in PDF format, and honestly the digital badge has become way more practical than the certificate for most people since you can slap it on LinkedIn, your email signature, or professional profiles with verification already built in.
Employers can verify your certification status through the Databricks certification verification system. You've got options for making your certification publicly visible or keeping it private while still allowing specific verification requests. Some candidates create public profiles showcasing their achievements, which can help with job searches in the data engineering space.
Appeals and statistical context
If you believe a scoring error happened, Databricks has an appeals process, though these situations are pretty rare since the exam's computer-scored with standardized rubrics. The process involves submitting a formal request through the certification team.
Pass rates for the Databricks Certified Data Engineer Associate certification aren't officially published, but anecdotally it looks like candidates with hands-on Databricks experience and structured preparation see success rates hovering around 60 to 70% on first attempts. That's comparable to the Databricks Certified Data Analyst Associate in terms of difficulty, maybe slightly more technical given the engineering focus.
Databricks Data Engineer Associate Exam Objectives
Databricks Certified Data Engineer Associate exam overview
The Databricks Certified Data Engineer Associate exam is basically Databricks asking, "Can you build and run real pipelines on the Lakehouse without breaking stuff?" Not theory-first. Practical-first. Short questions, scenario-ish prompts, lots of "what's the right command / option / approach" vibes.
Who's this for? Data engineers. Analytics engineers drifting into Spark. Folks doing ELT in the Lakehouse. If your day job includes Delta tables, ingestion headaches, and someone pinging you about a failing job at 2 a.m., you're the target.
Exam format, cost, and key policies
People always ask: how much does it cost? Honestly, pricing can change by region and taxes, and vouchers pop up through partners, so treat any number you see online as temporary. If you're searching Databricks data engineering associate exam cost, go straight to Databricks' certification site the week you plan to schedule.
Expect multiple-choice and multiple-select. Timed. Delivered online with proctoring in many locations. Scheduling's normal Pearson VUE style stuff. Retakes exist, but there's usually a waiting period. Read the policy before you click pay. Annoying? Yeah. Necessary? Also yeah.
Passing score and scoring details
Another FAQ: Databricks certified data engineer associate passing score. Databricks doesn't always make scoring feel super transparent, and they can update the exam without telling you, so focus less on the magic number and more on being able to explain why an answer's right. Score report timing's usually fast. I've seen people get results after a short delay though. It happens.
Exam objectives (what you'll be tested on)
Here's the meat: the five primary domains and weightings for the Databricks data engineer associate exam objectives. Look, the weights matter because they tell you where to spend your time when you're tired and trying to cram.
- Domain 1: Databricks Lakehouse Platform (around 20%)
- Domain 2: ETL/ELT and Data Ingestion (around 25%)
- Domain 3: Delta Lake fundamentals for data engineers (around 25%)
- Domain 4: ETL pipelines in Databricks using PySpark and SQL (around 20%)
- Domain 5: Databricks Workflows and job orchestration (around 10%)
Domain 1: Databricks Lakehouse platform (about 20%)
You need to understand the Lakehouse architecture and why it beats the old "warehouse over here, lake over there" split. That means unified storage on object storage, open formats, and governance without a bunch of duct tape. Expect questions about workspace basics too: notebooks, clusters, jobs, SQL warehouses. Simple stuff. But easy to miss when you only live in one UI screen.
DBFS comes up. So do storage integration patterns. Think mounting, direct cloud paths, and what actually gets used in production now. Compute's a big deal: cluster types (all-purpose vs job), autoscaling, and cost control. Also Databricks Runtime selection. Don't overthink it, but know why you'd pick a runtime with ML versus a standard runtime, and how runtime versions can affect libraries and Spark behavior.
Unity Catalog awareness is usually basic, like governance concepts, permissions, and metadata organization. Not a full admin exam. Still matters. I spent way too long trying to memorize every Unity Catalog permission hierarchy once, only to realize the exam just wants you to know it exists and handles governance across workspaces. Sometimes less is more.
Domain 2: ETL/ELT and data ingestion (about 25%)
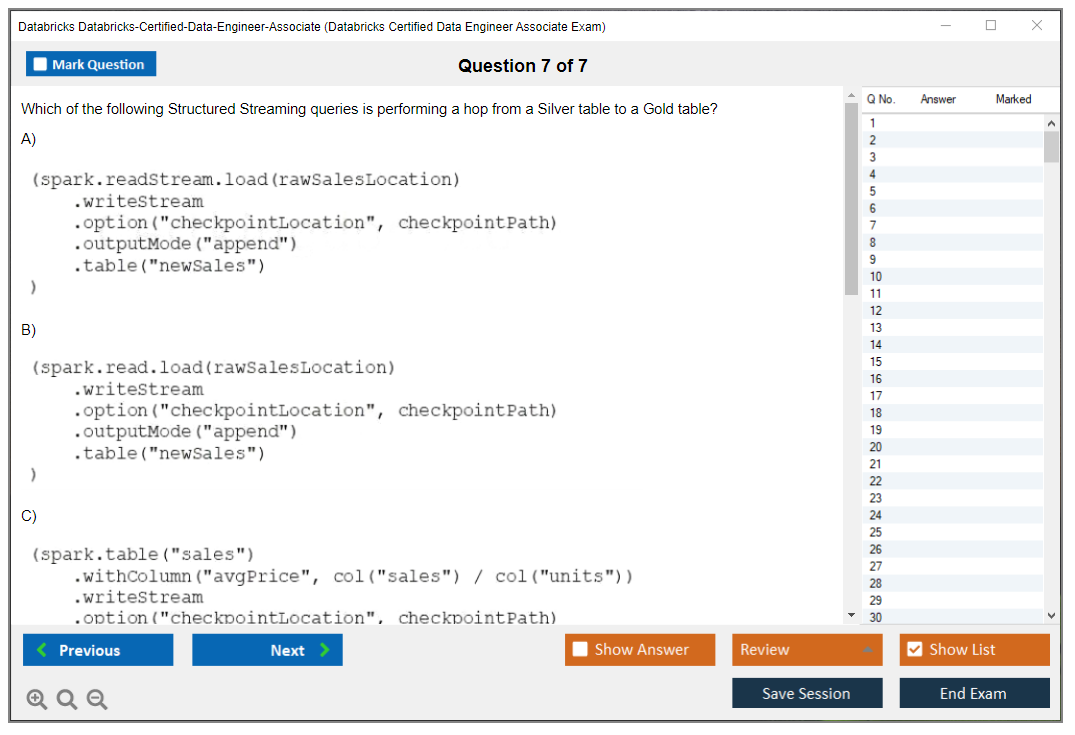
This domain's where people lose points because they "kind of know ingestion" but don't know the Databricks way. Auto Loader's a headline feature, so understand incremental file processing, schema inference, schema evolution, and what makes it reliable at scale. Also know streaming vs batch decisions. Not every "near real time" request should be Structured Streaming. Sometimes batch every 5 minutes is fine, sometimes it's not.
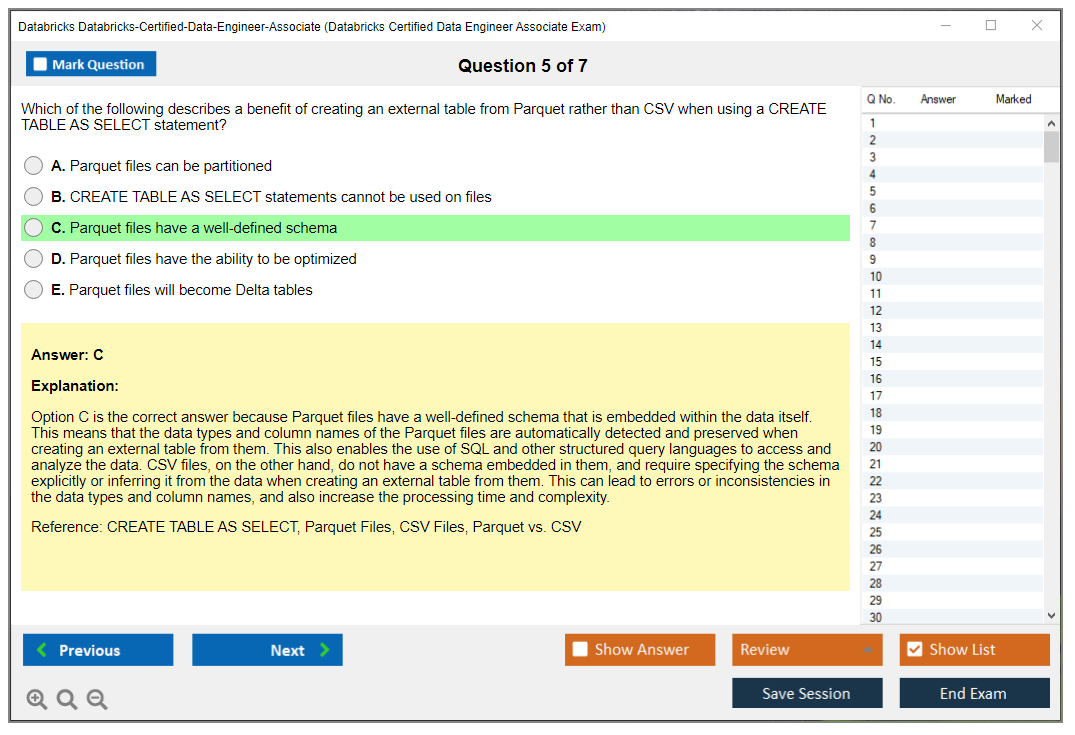
File formats show up constantly. Parquet, JSON, CSV, Avro, ORC. Know what's splittable, what's columnar, and what options you tend to set (headers, multiline JSON, inferSchema, etc.). COPY INTO is another frequent topic for efficient batch loading, especially for repeatable ingestion into Delta tables.
Don't ignore checkpointing. If you can't explain why a streaming query needs a checkpoint location and what happens when it changes, you're gonna have a bad time. External sources matter too: cloud storage, databases via JDBC, maybe APIs conceptually. Error handling and data quality checks? Mentioned a lot. Sometimes tested lightly. Still, know patterns like quarantining bad records and validating schema early.
Domain 3: Delta Lake fundamentals (about 25%)
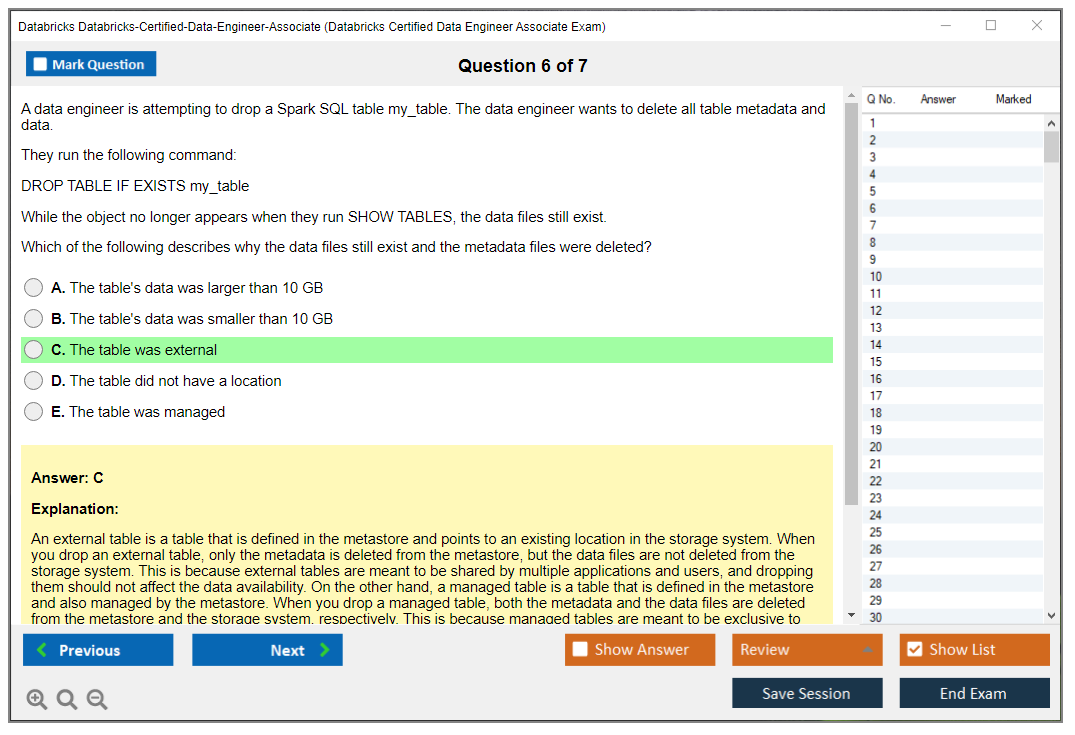
This is the other big chunk. You need Delta Lake fundamentals for data engineers, not just "Delta is Parquet with a log." Know how to create and manage Delta tables, pick partitioning that doesn't explode small files, and use CRUD operations. MERGE's huge for upserts and slowly changing dimensions. Learn the common SCD2 pattern well enough to spot the right MERGE clauses.
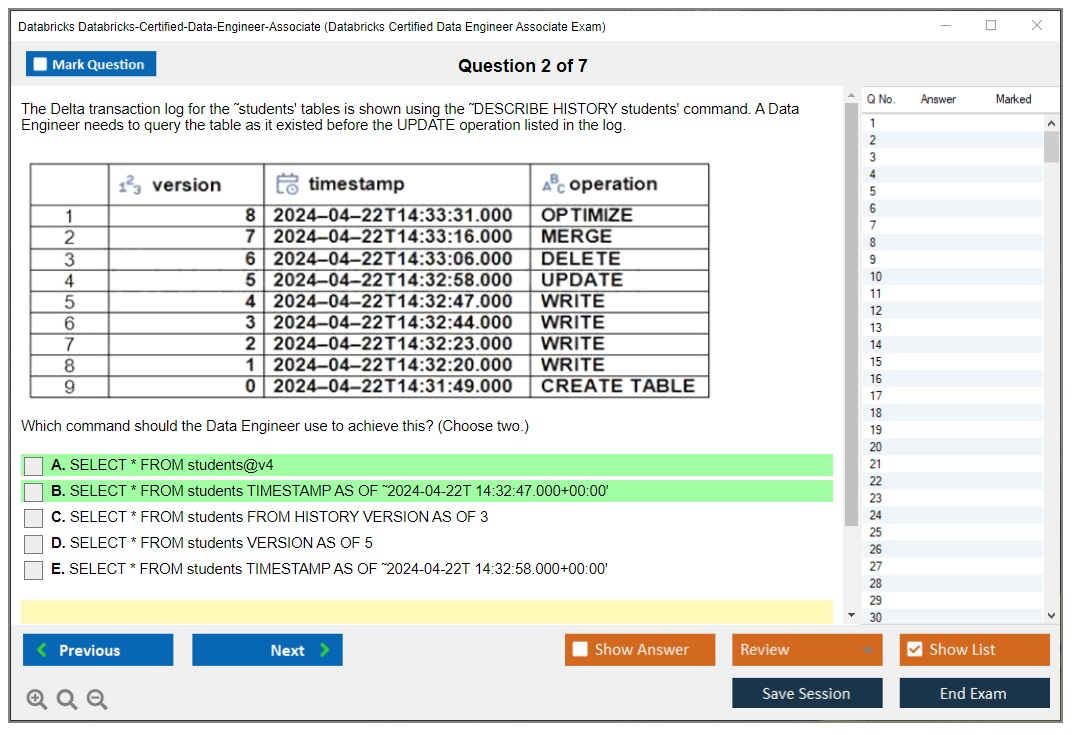
Time travel's fair game. 'VERSION AS OF', 'TIMESTAMP AS OF'. Transaction log concepts too, because that's how ACID works here. Optimization: 'OPTIMIZE' for compaction, Z-ordering for clustering, and 'VACUUM' for clearing old files while respecting retention. Constraints, generated columns, and Change Data Feed can show up as "what feature solves this requirement." Liquid clustering's newer, so at least know what problem it tries to solve versus Z-ordering when data access patterns change.
Domain 4: ETL pipelines with PySpark and SQL (about 20%)
This is your daily work. Spark SQL queries, DataFrame API, transformations like 'select', 'filter', 'groupBy', joins. Window functions. Complex types like arrays and structs. Null handling and safe casts.
The exam also likes performance fundamentals: lazy evaluation, execution plans, broadcast joins, skew hints, caching and persistence. UDFs are a trap. Built-ins are usually faster and easier to optimize, so know when a UDF's justified.
If you want targeted drilling, grab Databricks data engineer associate practice tests that include code snippets and output reasoning. I mean, I've also seen folks use the Databricks-Certified-Data-Engineer-Associate Practice Exam Questions Pack to spot weak areas fast, then go back to docs and labs.
Domain 5: Workflows and job orchestration (about 10%)
Smaller weight. Still free points if you prep. Know Jobs, schedules, triggers, parameters, task dependencies, retries, and monitoring logs. Job clusters vs all-purpose clusters is a classic cost question. Delta Live Tables shows up as a declarative pipeline option, with expectations for quality checks. Airflow integration gets mentioned, not deeply, just know where it fits.
Cross-cutting stuff you'll see everywhere
Data quality validation. Performance troubleshooting with Spark UI. Security basics like access controls and encryption. Cost controls across compute and storage. Debugging common Spark and Delta errors. This is where "Databricks Lakehouse data engineering skills" actually show.
If you're collecting Databricks data engineer associate study materials, mix docs with hands-on reps, then validate with something like the Databricks-Certified-Data-Engineer-Associate Practice Exam Questions Pack before you book the exam. Not gonna lie, practice questions are often where the "oh, they meant that wording" clicks.
Prerequisites and Recommended Experience
Official prerequisites (if any)
No gatekeeping here.
Databricks certification exams don't actually have hard prerequisites, which is kinda refreshing but also maybe dangerous depending on where you're at skill-wise. You won't need to prove prior certifications or submit transcripts before registering for the Databricks Certified Data Engineer Associate exam. You could literally sign up tomorrow if that's what you wanted. But here's the thing: just because there's no bouncer at the door doesn't mean you should waltz in unprepared. The exam assumes you've already got a solid foundation in data engineering concepts. Walking in cold is pretty much guaranteeing you'll waste money and leave feeling defeated.
Recommended hands-on experience (Databricks, Spark, SQL, Delta)
Look, the unofficial sweet spot? Six to twelve months of actual Databricks experience before attempting this thing.
I mean hands-on work. Not passively watching videos or skimming documentation while pretending you're learning. You need real experience creating notebooks, spinning up clusters, writing queries that processed actual data. And yeah, probably breaking stuff along the way because that's how you figure out what not to do. There's no substitute for that.
SQL proficiency is non-negotiable. We're talking intermediate-level comfort with SELECT statements, JOINs (especially multi-table joins), aggregations like GROUP BY and HAVING, subqueries, common table expressions. The usual toolkit. If you freeze up when someone mentions LEFT JOIN versus INNER JOIN, you're not ready. Period. The exam doesn't hold your hand on basic query syntax. It expects you to scan code snippets and immediately grasp what's happening without needing five minutes to decode each line.
Python skills matter too, particularly around data manipulation. Wait, let me clarify. You don't need to be some Python wizard or anything. You should be comfortable with pandas operations and PySpark syntax because questions about DataFrame transformations, filtering, and aggregations absolutely show up. You need to read PySpark code without your brain completely melting.
Apache Spark architecture fundamentals come up repeatedly. Understanding how drivers coordinate with executors, what distributed computing actually means in practice (not just theory), why certain operations trigger shuffles. This stuff matters when performance optimization questions appear. I've seen people who can write decent queries but have zero clue about what's happening under the hood, and they really struggle. Once had a colleague who could build entire pipelines but couldn't explain why her jobs kept timing out after adding one seemingly innocent groupBy operation. Turned out she was triggering massive shuffles across a billion-row dataset without any partitioning strategy. That's the kind of blindspot that kills you on exam day.
Delta Lake exposure? Basically mandatory at this point. You need hands-on experience creating Delta tables, understanding ACID transactions, running OPTIMIZE commands, working with time travel features. If Delta Lake is just a buzzword to you right now, spend serious time in the Databricks Community Edition workspace before scheduling anything.
Cloud fundamentals help tremendously. Object storage concepts across S3, ADLS, and GCS. Understanding how data lakes work, what mounting storage means, basic file path structures. ETL/ELT pipeline development experience from any platform translates well. The concepts remain consistent even if the specific tools differ.
Data warehouse concepts pop up too. Dimensional modeling basics in scenario questions. You don't need a degree in data warehousing, but understanding star schemas, fact tables, dimension tables gives you context for why certain design decisions make sense.
Skills checklist before attempting the exam
Run through this self-assessment honestly before dropping money.
Can you write intermediate SQL queries with multiple joins and aggregations without constantly googling syntax? If yes, good. If you're still searching "how to join three tables SQL" regularly, pump the brakes and practice more.
Reading and writing Python code for data transformation tasks should feel comfortable, not like deciphering ancient hieroglyphics. You need to understand DataFrame operations in PySpark. Filtering rows, selecting columns, applying transformations, handling null values. Basic stuff, but it needs to be second nature when you're under exam time pressure.
Experience creating and optimizing Delta tables matters more than you'd think. The exam loves asking about OPTIMIZE, VACUUM, Z-ORDER, and specifically when to use each command versus just throwing them at problems randomly. Familiarity with job scheduling and workflow orchestration concepts helps too, even if you haven't personally architected massive production pipelines.
Troubleshooting skills for common data pipeline errors separate candidates who pass from those who don't. When a job fails, can you read error messages and identify the actual problem? Do you understand why schema mismatches break ingestion pipelines? These practical scenarios show up.
Git basics for version control should be in your toolkit. Managing notebook code, committing changes, collaborating with teams through repositories. Command-line comfort for working through file systems and executing basic commands comes up in practical scenarios too.
Gap analysis and when to delay versus push forward
Do a gap analysis before committing. List topics from exam objectives. Rate your confidence on each. Identify weak areas.
If you're shaky on more than 30% of the content domains, consider delaying your attempt and focusing on targeted learning instead of gambling on exam fees. The thing is, Databricks Academy offers free courses that perfectly align with exam topics. Complete those before spending money. The Community Edition workspace gives you a free sandbox for gaining prerequisite experience without cloud bills piling up, which is a huge advantage if you're budget-conscious.
If you're coming from a non-technical background or recent bootcamp, give yourself more runway. Alternative pathways through online courses and self-study absolutely work, but they require more preparation time than someone with a computer science degree and existing data engineering experience already has.
Complementary certifications like cloud provider credentials (Azure Databricks platform administration or AWS fundamentals) strengthen your overall profile, but tackle this exam first if data engineering is your primary career path.
Difficulty Level and Common Challenges
Difficulty level and common challenges
The Databricks Certified Data Engineer Associate exam sits at intermediate certification territory. Not for beginners. Definitely not for the "I binged a couple YouTube tutorials" crowd. Theory matters, sure, but what really counts is actually applying this stuff in a workspace where things go sideways, jobs suddenly fail, and Spark gets temperamental unless you really understand what's happening behind the scenes.
Stacked against other data engineering certs, the Databricks Data Engineer Associate certification lands squarely in moderately challenging territory. Harder than those lightweight SQL-only tests where you're basically identifying join types. Easier than architect-level cloud exams that sprawl across like ten services you'll realistically never use in production. It's totally achievable with proper prep, especially if you actually spend time building small ETL pipelines in Databricks using PySpark or SQL, digging into execution plans, and getting really comfortable with Delta Lake fundamentals for data engineers instead of treating that material like it's just trivia you cram the night before.
Hands-on experience beats memorization here. That's the common refrain from candidates. Look, you can memorize what OPTIMIZE does technically, but the exam loves throwing scenarios where the actual question becomes "when would you do this, what's the tradeoff you're accepting, and what metrics would you check afterward," and that knowledge only sticks if you've actually done it yourself. You need to see the file layout firsthand and notice what happens when retention settings or partitioning choices come back to bite you weeks later.
Your background totally changes the pain points. Software engineers moving into data engineering usually find the coding parts easier because they're comfortable reading PySpark, but they often struggle with Delta Lake specifics like transaction log behavior, table properties, and what optimization commands really mean operationally in production environments. Traditional DBAs are basically the opposite scenario. SQL feels like home territory. They'll absolutely crush joins and basic transformations, but PySpark and distributed computing concepts can feel slippery, especially when the exam hints at shuffles, skew, and why "works perfectly on my laptop" logic completely collapses at cluster scale. Data analysts moving toward engineering roles tend to get hit hardest by programming depth and performance tuning. They know the business logic cold, but performance troubleshooting is just a different muscle entirely. Experienced Spark developers? The concepts feel familiar, honestly, but Databricks-specific implementations and terminology can still trip them up. This includes UI components, Databricks Workflows and job orchestration, and how Databricks frames proprietary features like Auto Loader or Delta Live Tables differently than standard Spark. Side note: I once watched a senior Spark dev who could optimize joins in his sleep completely bomb a question about workspace tokens and permission inheritance because he'd never bothered with the admin console.
The hardest topics show up repeatedly in feedback and failure write-ups people share online. Delta Lake optimization techniques are a massive one, especially the "when" questions. When to use OPTIMIZE, when Z-ORDER actually helps versus when it's overkill, and when VACUUM is appropriate, plus retention periods and the serious consequences if you vacuum too aggressively and accidentally break time travel. Auto Loader trips people up too because configuration details really matter, and schema evolution handling is where candidates start guessing instead of knowing. Performance troubleshooting is another frequent landmine. You have to identify bottlenecks from Spark execution plans, understand what causes expensive shuffles, and know which change actually improves runtime instead of just changing syntax cosmetically.
Structured Streaming is a classic stress point. Watermarking, windowing, checkpoint management. The thing is, those are easy to read about in docs, but in the exam you'll see scenario-based questions where one missing checkpoint detail means duplicates, or a wrong watermark assumption means late data never lands correctly. You need to understand the operational implications, not just the syntax. Delta Live Tables also shows up with syntax and expectations framework questions, and they're subtle, because the exam can ask what happens when an expectation fails at different severity levels, or where you'd place quality checks for maximum impact. Unity Catalog permissions and governance models are another headache. Candidates constantly mix up workspace-level permissions with catalog and schema permissions. The "who can do what" questions are annoyingly picky about hierarchies.
Subtle differences between similar commands is where time just disappears. Same for "best" vs "correct" answer choices. The exam writers absolutely know it.
Common failure mistakes are super predictable. Insufficient hands-on practice is number one because scenario questions require you to apply concepts in context, not just recite definitions. Relying only on documentation reading without building actual pipelines is basically the same trap with extra steps and maybe some false confidence. Underestimating Delta Lake depth is huge. People walk in thinking Delta is "just parquet with ACID," then get absolutely smacked by questions about optimization choices, retention policies, and operational outcomes. Poor time management is another killer because 90 minutes for 45 questions is roughly two minutes each, and if you overthink early questions you'll rush later ones and start making dumb errors you'd never make otherwise.
Misreading questions is brutal here. You'll see qualifiers like "most efficient," "best approach," or "least operational overhead," and missing one word completely flips the answer. Confusing PySpark syntax with pandas or standard Python happens more than you'd think, especially under pressure. Not understanding when to use different optimization techniques leads to wrong "best choice" answers even if you know each command exists in isolation. That gap between knowing a concept exists and knowing when to apply it strategically is basically the whole exam wrapped up.
Tricky patterns show up constantly. Multiple correct answers where you must pick the best approach based on scenario context. Negative questions asking what NOT to do. Performance comparison questions tied to execution plans. Troubleshooting scenarios where you identify the root cause rather than just the symptom. Mental fatigue is absolutely real by question 35. Take quick micro-resets, slow down deliberately for negations, and flag anything that smells like a time sink.
Randomized pools mean difficulty varies between versions. That's why practical experience reduces difficulty substantially. You start recognizing patterns. You stop guessing. And if you want reps, doing timed drills helps tremendously, and a focused set like the Databricks-Certified-Data-Engineer-Associate Practice Exam Questions Pack can be a decent way to pressure-test weak areas before you pay the Databricks data engineering associate exam cost again on a retake. I'd rather see someone do hands-on labs plus targeted practice tests, then use the Databricks-Certified-Data-Engineer-Associate Practice Exam Questions Pack to practice reading questions carefully and deciding fast under time pressure.
Confidence comes from evidence. Build small pipelines. Break them on purpose. Fix them. Then your brain has actual receipts when exam anxiety kicks in, and you're not just hoping you remember a line from the docs or a bullet from your Databricks data engineer associate study materials.
Best Study Materials and Resources
Official Databricks data engineer associate study materials
Okay, here's the deal. The official Databricks Academy learning paths? That's your starting point. No debate. These aren't some watered-down third-party courses that sorta cover what you need. They're purpose-built for the Databricks Certified Data Engineer Associate exam, which makes all the difference when you're trying to figure out what actually matters versus what's just noise.
The "Data Engineering with Databricks" course is your full foundation. If you're gonna use just one resource, this should be it.
Self-paced online training modules come with hands-on exercises that actually matter. You're not just watching videos and clicking through slides like some mindless zombie. You're working with real Databricks notebooks, building pipelines, messing with Delta tables. That's what separates people who pass from those who memorize definitions and then panic when they see scenario-based questions. Happens way more than you'd think. Some folks prefer instructor-led training for the structured approach and expert guidance, which works great if you need accountability or learn better with someone walking you through the material instead of fumbling around solo.
Documentation areas you absolutely can't skip
Delta Lake guide? Non-negotiable. I mean every single section. Table operations, optimizations like Z-ordering and data skipping, MERGE syntax for upserts, time travel queries, all of it. The exam loves asking about when to use OPTIMIZE versus VACUUM or how to handle schema evolution, and if you don't know this cold, you're toast.
Databricks SQL documentation covers query syntax and warehouse management in ways that'll save your butt on performance-related questions.
Auto Loader documentation with all those configuration examples? Read it twice, maybe three times. The exam scenarios will throw different file formats and schema evolution requirements at you. You need to know which options solve which problems without second-guessing yourself or wasting precious time during the test trying to remember what parameter does what.
Structured Streaming programming guide, Delta Live Tables documentation (especially expectations and pipeline syntax), job orchestration guides, Unity Catalog for governance concepts. These aren't optional reading, they're required. Cluster configuration guides matter more than you'd think because optimization questions come up constantly. They love testing whether you actually understand resource allocation or you're just guessing.
Apache Spark foundations matter
Here's the thing about the Databricks certification: it assumes you understand the underlying Spark concepts, not just the Databricks-specific stuff layered on top. The Spark SQL guide helps you understand DataFrame operations at a deeper level than just "run this code and it works." You need to know why it works. PySpark API reference is where you verify function syntax and parameters when you're building your practice projects, which you should be doing constantly.
The Spark tuning and optimization guide explains why certain approaches perform better. Connects directly to exam questions about partitioning strategies or broadcast joins.
Hands-on practice is everything
Real talk here. Databricks Community Edition gives you a free workspace for unlimited practice, and not using it is basically self-sabotage. Why would you skip free hands-on experience? Create personal projects that mirror exam scenarios. Don't just follow tutorials like a robot. Build an incremental data ingestion pipeline using Auto Loader with schema evolution, which sounds complicated but becomes second nature once you've done it a few times.
Implement a slowly changing dimension Type 2 using MERGE operations. Sounds fancy but it's actually a common exam topic that trips people up constantly.
Real-time streaming pipelines with aggregations and windowing will test whether you actually understand Structured Streaming or just memorized definitions from documentation without internalizing the concepts. A Delta Live Tables pipeline with bronze, silver, and gold layers forces you to think about data quality expectations and pipeline dependencies in ways that reading alone never will. I mean, there's just no substitute for building the thing yourself and watching it either work beautifully or fail spectacularly. Job orchestration workflows with task dependencies and error handling? That's exam material right there, showing up in multiple questions.
Performance optimization projects where you compare different partitioning and clustering strategies will teach you more than reading documentation ever could. Use the sample datasets from Databricks (NYC taxi data, retail data, IoT sensor data) because measuring actual performance impacts beats theoretical knowledge every single time. No question.
Third-party resources and practice materials
Online course platforms like Udemy, Coursera, and Pluralsight offer Databricks-focused content that varies wildly in quality, so read reviews before dropping money. YouTube channels with tutorials can fill knowledge gaps when you're stuck on specific concepts. Blog posts from certified professionals sharing their exam experiences give you realistic expectations about difficulty level and question types, which helps with anxiety management.
The Databricks Community Forums and Reddit discussions help when you're stuck on specific concepts and need someone to explain it differently than the official docs.
Books like "Learning Spark" by Jules Damji cover Spark fundamentals thoroughly, while "Delta Lake: The Definitive Guide" goes deep on Delta knowledge that directly applies to exam questions. Not just theory, but practical application stuff. The Databricks blog posts on new features and best practices are worth skimming regularly, though admittedly some of it gets technical beyond exam requirements. I once spent an afternoon reading about photon execution engine internals when I should've been practicing Auto Loader configurations. Interesting? Sure. Necessary for passing? Not really.
For structured practice, the Databricks Certified Data Engineer Associate Practice Exam Questions Pack at $36.99 gives you realistic scenario-based questions that match the exam format. Practice questions reveal knowledge gaps faster than anything else because they force you to apply concepts under pressure, which is exactly what the real exam does.
If you're considering other Databricks certifications afterward, check out the Databricks Certified Data Engineer Professional or Databricks Certified Data Analyst Associate paths to see how they build on this foundation. Some folks even explore the Azure Databricks Certified Associate Platform Administrator track for cloud-specific skills, though that's a bit of a tangent from pure data engineering.
Bottom line: official materials first, hands-on practice constantly, practice questions to validate your readiness.
Conclusion
Wrapping this up
Look, the Databricks Certified Data Engineer Associate exam isn't something you just wing on a Tuesday afternoon. It's a proper test of your ability to actually build data pipelines, not just talk about them in meetings. You need solid hands-on experience with Delta Lake fundamentals for data engineers, Spark SQL transformations, and the whole Databricks Lakehouse data engineering skills ecosystem before you even think about scheduling this thing.
The exam objectives? Pretty specific.
You're covering data ingestion patterns, ETL pipelines in Databricks (PySpark/SQL), optimization techniques, and Databricks Workflows and job orchestration. You're gonna spend time on Delta table operations, troubleshooting performance issues, and understanding how data quality checks actually work in production environments. The sections on incremental processing and Auto Loader trip people up way more than they expect, which always surprises me because these are tools you'd think would be straightforward once you've read the docs. Apparently the details around schema inference and exactly-once semantics catch folks off guard. I once watched a colleague spend three hours debugging an Auto Loader job that was duplicating records because he'd misconfigured the checkpoint location, and honestly that kind of mistake is more common than anyone wants to admit.
Cost-wise, yeah, it's an investment. The Databricks data engineering associate exam cost runs a couple hundred bucks, and you need to hit that Databricks certified data engineer associate passing score on your first try if possible because retakes add up fast. Most people I've talked to say 4-6 weeks of focused study works if you're already working with Databricks daily. Coming from traditional data warehousing or haven't touched Apache Spark on Databricks certification material before? Give yourself more runway. Maybe double that.
Here's the thing about study materials. Official Databricks documentation? Required reading. But it's not enough by itself, which frustrates a lot of candidates. You need hands-on labs where you're actually writing PySpark code, creating Delta tables, setting up job clusters, and debugging failed workflows. The certification doesn't expire immediately, but Databricks certification renewal data engineer associate requirements mean you'll need to stay current as the platform keeps changing.
The best prep strategy combines official training paths with quality practice tests that mirror the actual exam format. And I mean actually good Databricks data engineer associate practice tests. Not those garbage dumps with outdated questions from 2019 that still reference deprecated APIs.
If you're serious about passing, check out the Databricks Certified Data Engineer Associate Practice Exam Questions Pack. It's built around current exam objectives and gives you the kind of scenario-based questions you'll actually face. Real preparation beats wishful thinking every single time.